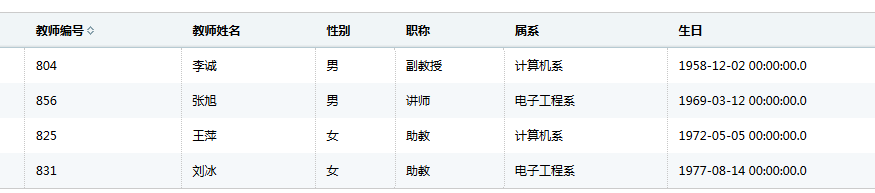
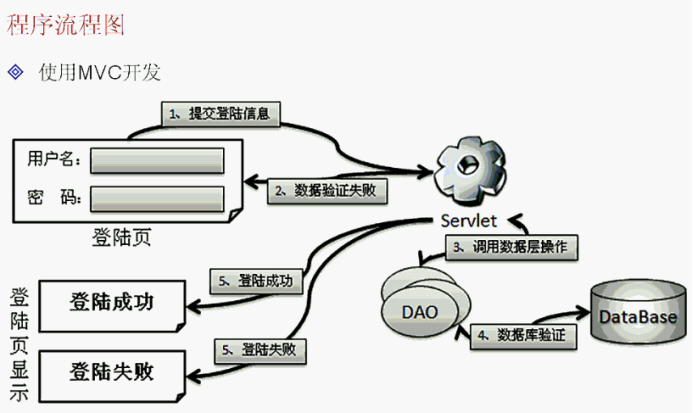
不外乎有以下因素:
1、從頁面加載時間來看:靜態頁面不需要與數據庫建立連接,尤其是訪問數據量較大的頁面,這種頁面大多要查很多結果集,因此建立連接次數就增多了,時間不可觀,而靜態頁面則省去了這些時間。
2、從便於搜索引擎抓取的角度來講:搜索引擎更喜歡靜態的網頁,靜態網頁與動態網頁相比,搜索引擎更喜歡靜的,更便於抓取,搜索引擎SEO排名更容易提高,一些大門戶站頁面大多都采用靜態或偽靜態網頁來顯示,更便於搜索引擎抓取與排名。
3、從安全性來看:靜態網頁不宜遭到黑客攻擊,因為黑客不知道你的網站的後台、網站采用程序、數據庫的地址。
4、從穩定性來看:哪天數據庫服務器掛了,動態網頁就拜拜了!而要運行一個靜態網頁的發布服務器,相信大家都知道配置不是太高也行的吧?呵呵。
因此,我認為,生成靜態頁面具有可行性。
那麼怎麼把動態網頁的代碼生成靜態網頁呢?又存在哪呢?原理其實很簡單。
1、利用Freemark模板生成靜態頁面,網上搜一下大把大把的代碼隨你挑,我就不在這裡啰嗦了。
我很討厭這種方式,因為對於一個數據量較大的頁面來講工作量太大,要寫模板,語法又比較怪異,不流行!
2、也是我偶爾想起來的。用Java中URLConnection抓取某個URL網頁源碼(這是原理核心)生成html文件,就是這麼簡單!就是這麼Easy!
代碼奉上!
1)、以下是捕捉網頁源碼程序: 復制代碼 代碼如下:
import java.io.BufferedReader;
import java.io.File;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.commons.io.FileUtils;
import org.apache.commons.lang.StringUtils;
/**
* @author Xing,XiuDong
*/
public class HTMLGenerator {
public static final String generate(final String url) {
if (StringUtils.isBlank(url)) {
return null;
}
Pattern pattern = Pattern.compile("(http://|https://){1}[\\w\\.\\-/:]+");
Matcher matcher = pattern.matcher(url);
if (!matcher.find()) {
return null;
}
StringBuffer sb = new StringBuffer();
try {
URL _url = new URL(url);
URLConnection urlConnection = _url.openConnection();
BufferedReader in = new BufferedReader(new InputStreamReader(urlConnection.getInputStream()));
String inputLine;
while ((inputLine = in.readLine()) != null) {
sb.append(inputLine);
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return sb.toString();
}
/**
* Test Code
* Target : http://www.google.cn/
*/
public static void main(String[] args) throws IOException {
String src = HTMLGenerator.generate("http://www.google.cn/");
File file = new File("C:" + File.separator + "index.html");
FileUtils.writeStringToFile(file, src, "UTF-8");
}
}
2)、將源碼寫入Html文件,這個需要根據用戶的需求了,我根據我項目中遇到的情況寫了以下代碼:
復制代碼 代碼如下:
/**
* generite html source code
*
* @author Xing,XiuDong
* @date 2009.06.22
* @param request
* @param url
* @param toWebRoot
* @param encoding
* @throws IOException
*/
public void genHtml(HttpServletRequest request, String url, boolean toWebRoot, String encoding) throws IOException {
if (null == url) {
url = request.getRequestURL().toString();
}
String contextPath = request.getContextPath();
String seq = StringUtils.substring(String.valueOf(new Date().getTime()), -6);
String ctxPath = super.getServlet().getServletContext().getRealPath(File.separator);
if (!ctxPath.endsWith(File.separator)) {
ctxPath += File.separator;
}
String filePath = StringUtils.substringAfter(url, contextPath);
filePath = filePath.replaceAll("\\.(do|jsp|html|shtml)$", ".html");
String savePath = "";
String autoCreatedDateDir = "";
if (!toWebRoot) {
savePath = StringUtils.join(new String[] { "files", "history", "" }, File.separator);
String[] folderPatterns = new String[] { "yyyy", "MM", "dd", "" };
autoCreatedDateDir = DateFormatUtils.format(new Date(), StringUtils.join(folderPatterns, File.separator));
filePath = StringUtils.substringBefore(filePath, ".html") + "-" + seq + ".html";
}
File file = new File(ctxPath + savePath + autoCreatedDateDir + filePath);
FileUtils.writeStringToFile(file, HTMLGenerator.generate(url), encoding);
}
來源:http://blog.csdn.net/xxd851116