Scrapy是一個為了爬取網站數據,提取結構性數據而編寫的應用框架。 可以應用在包括數據挖掘,信息處理或存儲歷史數據等一系列的程序中。
Scrapy基於事件驅動網絡框架 Twisted 編寫。因此,Scrapy基於並發性考慮由非阻塞(即異步)的實現。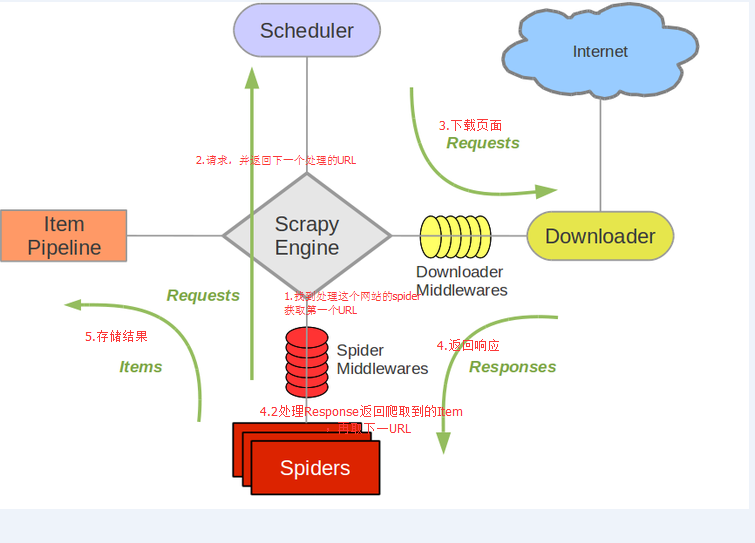
引擎負責控制數據流。
調度器從引擎接受request並將他們入隊,以便之後引擎請求他們時提供給引擎。
下載器負責獲取頁面數據並提供給引擎,而後提供給spider。
Spider是Scrapy用戶編寫用於分析response並提取item(即獲取到的item)或額外跟進的URL的類。 每個spider負責處理一個特定(或一些)網站。
Item Pipeline負責處理被spider提取出來的item。典型的處理有清理、 驗證及持久化(例如存取到數據庫中)。
下載器中間件是在引擎及下載器之間的特定鉤子(specific hook),處理Downloader傳遞給引擎的response。 其提供了一個簡便的機制,通過插入自定義代碼來擴展Scrapy功能。
Spider中間件是在引擎及Spider之間的特定鉤子(specific hook),處理spider的輸入(response)和輸出(items及requests)。 其提供了一個簡便的機制,通過插入自定義代碼來擴展Scrapy功能。
創建工程
命令行運行 scrapy startproject 工程名
爬蟲Class定義需要放在spiders目錄下。
屬性
name : 爬蟲名字(必有)
start_urls : 爬取起始網址(必有)
方法
parse(self, response) :獲取網頁內容後框架執行的回調方法,在該方法中可以對響應進行處理,也可以再次發起Request請求,例如:
scrapy.Request(url=link, errback=self.errback_http, callback=self.parse_article)
框架會對url=link的地址發起請求,如果請求出現錯誤執行用戶自定義的errback_http方法,如果請求成功則執行用戶自定義的parse_article方法。
頁面元素解析Selector有四個基本的方法(點擊相應的方法可以看到詳細的API文檔):
xpath(): 傳入xpath表達式,返回該表達式所對應的所有節點的selector list列表 。css(): 傳入CSS表達式,返回該表達式所對應的所有節點的selector list列表.extract(): 序列化該節點為unicode字符串並返回list。re(): 根據傳入的正則表達式對數據進行提取,返回unicode字符串list列表。運行爬蟲
在項目目錄下運行以下命令,即可執行爬蟲:
scrapy crawl NAME
其中NAME為爬蟲屬性name
自定義元素(Item)在items.py中定義,需要繼承scrapy.Item,可以將元素理解成key-value的HashMap。
Spider代碼盡可能關注內容抽取,並保存在Item中,後續框架將Item交給管道處理,這種方式很好地對數據抽取和處理進行解耦。
例如上述的 parse_article 方法, API要求返回一個元素或字典類型對象,在管道中可獲取該對象並進行數據處理。
配置信息都定義在settings中,可以把它理解成Java應用中的application.properties文件,數據庫,緩存等信息都保存在這裡。
如果需要使用該配置文件中定義的屬性,類(爬蟲,管道,插件)需要增加額外的類方法: from_crawler(cls, crawler)
框架在實例化類對象時候回調該方法,並傳入crawler對象,後者可以獲取到定義在settings中的屬性值,例如:
crawler.settings.get('URL_FILE')
settings中的屬性也可以通過在代碼中引入from scrapy.utils.project import get_project_settings,顯示的調用
settings = get_project_settings()方法然後就可以使用settings中的屬性值了。如下:
conn = MySQLdb.connect(
host=settings['MYSQL_HOST'],
user=settings['MYSQL_USER'],
passwd=settings['MYSQL_PASSWD'],
db=settings['MYSQL_DBNAME'],
use_unicode=True,
charset="utf8"
)
管道類似過濾處理鏈,根據自定義業務依次處理Spider解析後的數據,例如數據驗證(去重、轉換),計算存儲(DB,NOSQL),發送消息(Kafka,MQ),報表生成。
開發自定義管道類需要兩步驟:
說明
自定義管道根據序列號從小到大依次執行請求,如果拋出DropItem異常,後續管道將不會執行,例如數據出現重復主鍵,可以拋出DropItem異常。
使用以下代碼在管道中定義日志名稱
logger = logging.getLogger('pipelogger')
日志啟用也可以在settings中設置如下屬性
LOG_ENABLED = True #啟用日志
LOG_ENCODING = 'utf-8' #設置日志字符集
LOG_FILE = 'e://workspace/log/csdncrawl.log' #指定日志文件及路徑
LOG_LEVEL = 'INFO' #定義日志級別
LOG_STDOUT = True #是否將print語句打印內容輸出到日志
開發者可自定義運行在不同階段的插件,例如打開爬蟲、關閉爬蟲、數據抓取等。
插件只需要關注:在什麼時候做什麼事情,即 狀態-方法。
開發插件只需要2步:
下列的安裝步驟假定您已經安裝好下列程序:
pip install pyopenssl
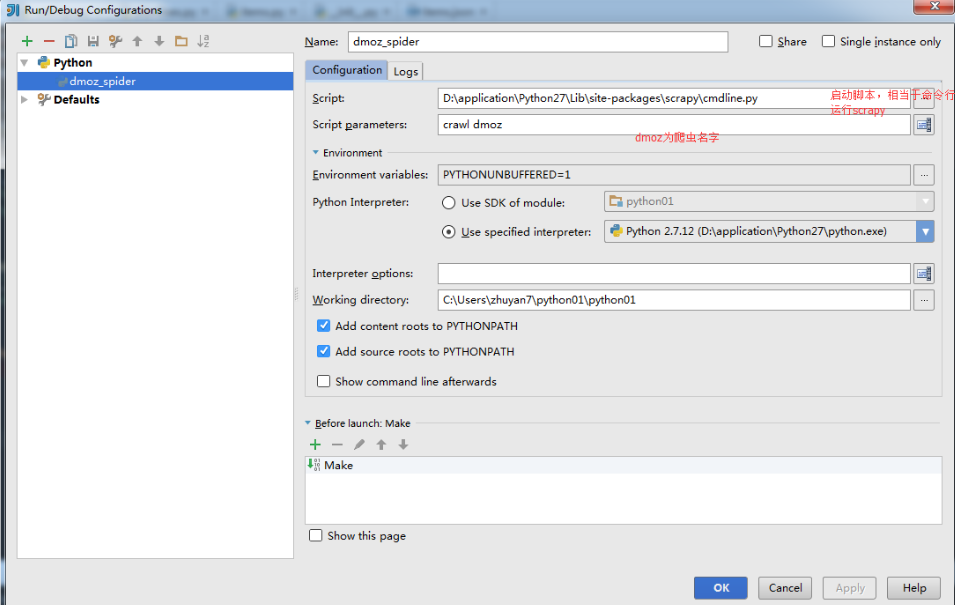
Idea中配置scrapy啟動
日志Logging
import logginglogger = logging.getLogger('mycustomlogger')
logger.warning("This is a warning")
import logging
import scrapy
logger = logging.getLogger('mycustomlogger')
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://scrapinghub.com']
def parse(self, response):
logger.info('Parse function called on %s', response.url)
參考資料:
中文版scrapy資料地址:https://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/tutorial.html