這幾天在做數據統計,有幾個統計圖的需求是這樣的: 按照年、月、日統計訂單數量, 比方一年12個月,統計出1月多少訂單,二月多少訂單,按照這種模式統計。
但是數據庫裡存放的是 timestamp 的 current_timestamp 默認值——"2016-12-16 12:30:00"。(這裡許多公司會使用時間戳,其實都差不多)
當時腦子裡想到的第一種做法是,講所有數據一次性取出來,然後foreach 一個個date()後,得到日期後再一個個去分組。
後來考慮到如果數據量大了,性能上會不會出問題。就想到了mysql 內置的FROM_UNIXTIME() 函數 然後用一個group by 分組解決。
date("Y-m-d", 1481862600) = 2016-12-16 12:30:00
FROM_UNIXTIME(add_time, '%Y-%m-%d')
為了比較兩個函數之間的效率,我做了一個實驗,
1、創建一張表 只有三個字段
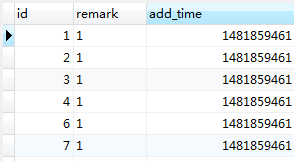
CREATE TABLE `t1` ( `id` int(11) NOT NULL AUTO_INCREMENT, `remark` char(10) DEFAULT NULL, `add_time` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=458731 DEFAULT CHARSET=latin1;
2、再用自我復制語句,迅速將表數據復制到了20多萬條數據
INSERT INTO t1(remark,add_time) SELECT remark,add_time FROM t1
3、接下來是PHP的執行代碼
第一種,使用PHP的date函數循環賦值:
// 獲取開始時間的微妙
$startTime = microtime(true);
$pdo = new PDO("mysql:host=localhost;dbname=test","root","");
$rs = $pdo -> query("select id,add_time,remark from t1 limit 262144");
$data = $rs->fetchAll();
$php_number_count = 0;
foreach ($data as $item){
$php_number_count +=1;
$tmp[] = date("Y-m-d", $item['add_time']);
}
echo $php_number_count."<br>";
echo "開始時間:".$startTime."<br>";
echo "結束時間:".$endTime = microtime(true). "<br>";
$resTime = $endTime - $startTime;
echo "用時:".$resTime;exit;
輸出結果
262144 開始時間:1481871208.7704 結束時間:1481871210.1535 用時:1.3830921649933 秒
第二種使用mysql的FROM_UNIXTIME()函數
// 獲取開始時間的微妙
$startTime = microtime(true);
$pdo = new PDO("mysql:host=localhost;dbname=test","root","");
$rs = $pdo -> query("select id,remark,add_time,FROM_UNIXTIME(add_time, '%Y-%m-%d') as datetime from t1 limit 262144");
$data = $rs->fetchAll();
echo "開始時間:".$startTime."<br>";
echo "結束時間:".$endTime = microtime(true). "<br>";
$resTime = $endTime - $startTime;
echo "用時:".$resTime;exit;
輸出結果:
開始時間:1481871495.7308 結束時間:1481871496.7279 用時:0.99707913398743
從上面的結果顯示明顯是 使用 mysql的 FROM_UNIXTIME()函數要快一些
但是發現在使用PHP的date()函數裡 多個一個對結果集的foreach 循環,為了保證數據的嚴謹性,我又再 使用 mysql的 FROM_UNIXTIME() 的後面加了一個結果集的foreach循環來盡量保證結果的准確性 如下
// ..........
$data = $rs->fetchAll();
foreach ($data as $row){
$tmp[] = $row['add_time'];
};
// .........
結果:
開始時間:1481871764.8102 結束時間:1481871766.0483 用時:1.2380890846252
為了盡量避免數據的偏差性、不穩定性,每份代碼我分別執行了10次,並記錄下結果
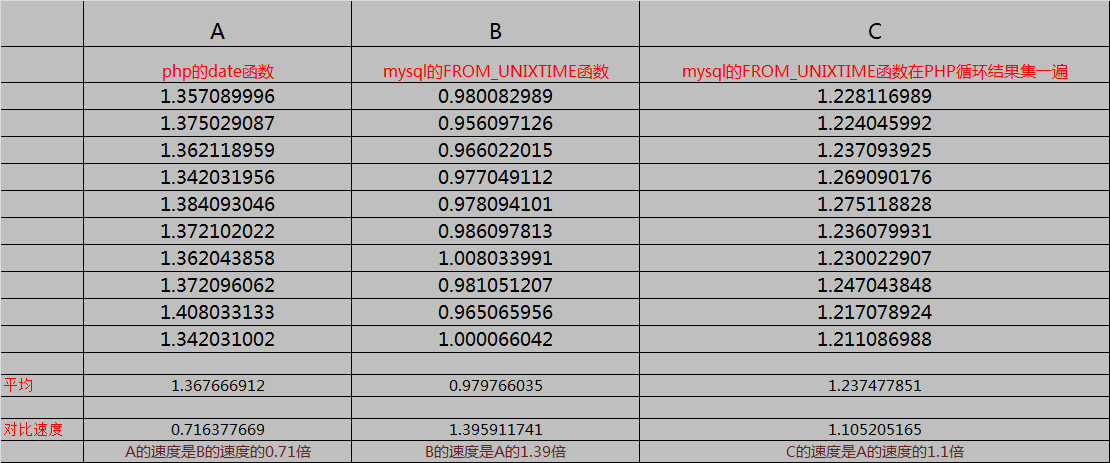
最後得出的結果是, 使用FROM_UNIXTIME()函數 是速度是最快的,如果group by 後能直接得到想要的結果集,那自然是最好的。
不過我們不能忽略mysql數據庫執行的開銷。畢竟執行中一定程度上會加大數據庫的壓力。
最後這個世界是沒有最好的辦法,只有最適合的辦法。 如果哪位大俠有哪種更好的辦法,歡迎分享。