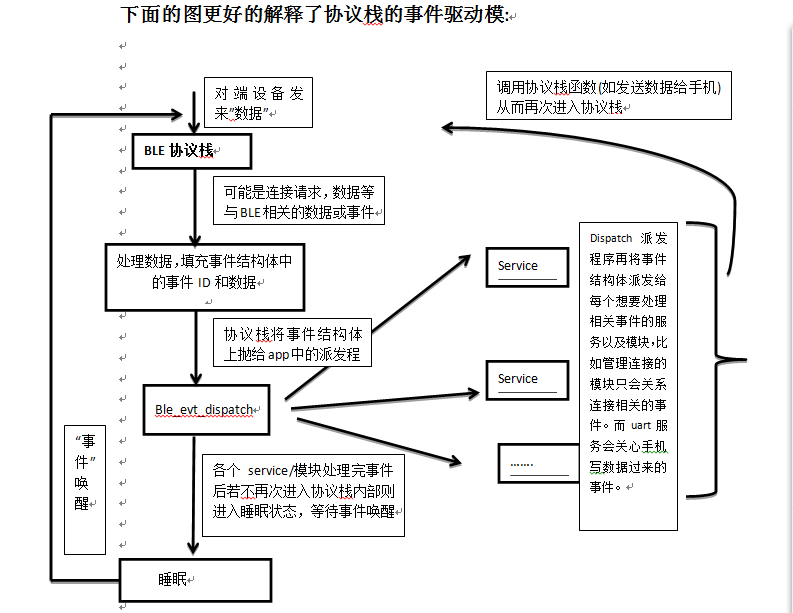
selenium中webdriver的局部HTML提取
別和我說selenium中的webdriver用driver.page_source,我就是不想把整篇HTML文檔每次都全部提出來做Soup。因為,對下面這樣左右結構的論壇而言,每次內容的改變對於整個HTML頁面而言實在是一個很小的部分,如果我想把整個網站所有MOOC課程評論爬下來的話,將要做多少無用功!
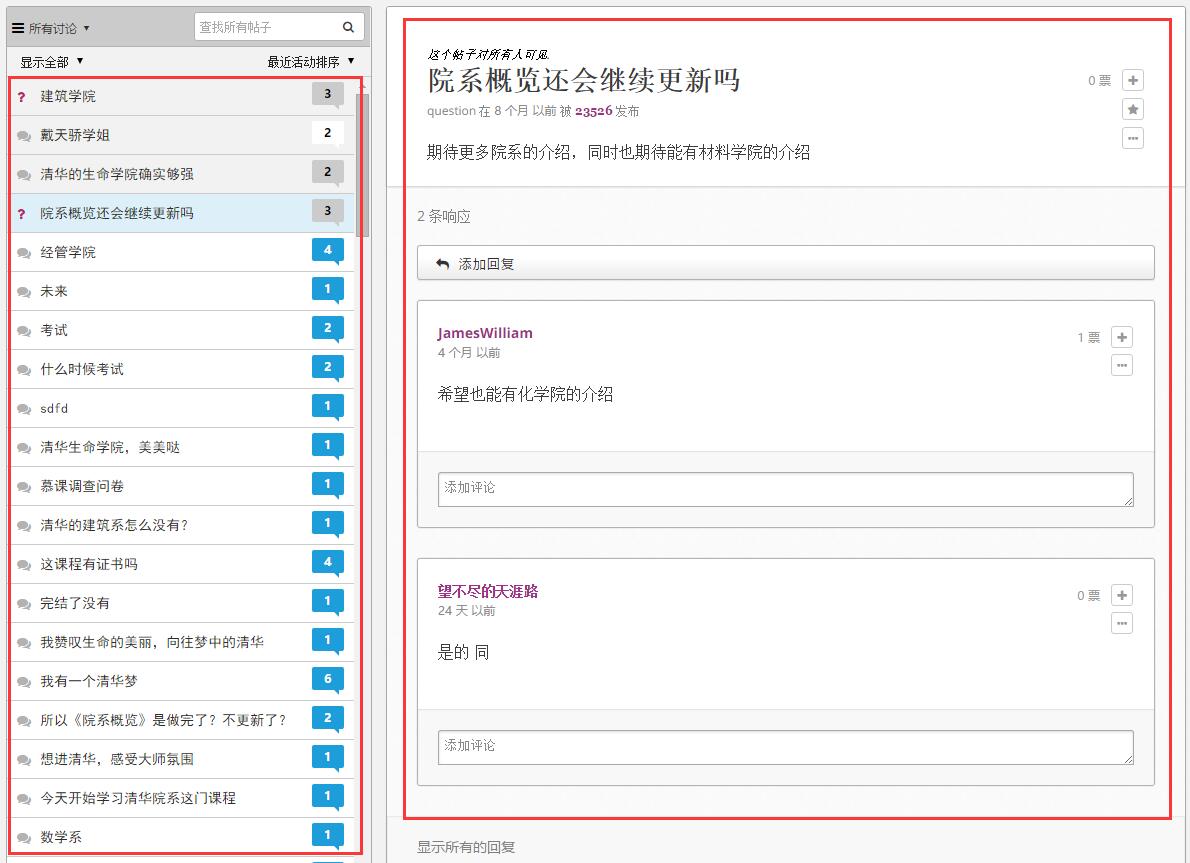
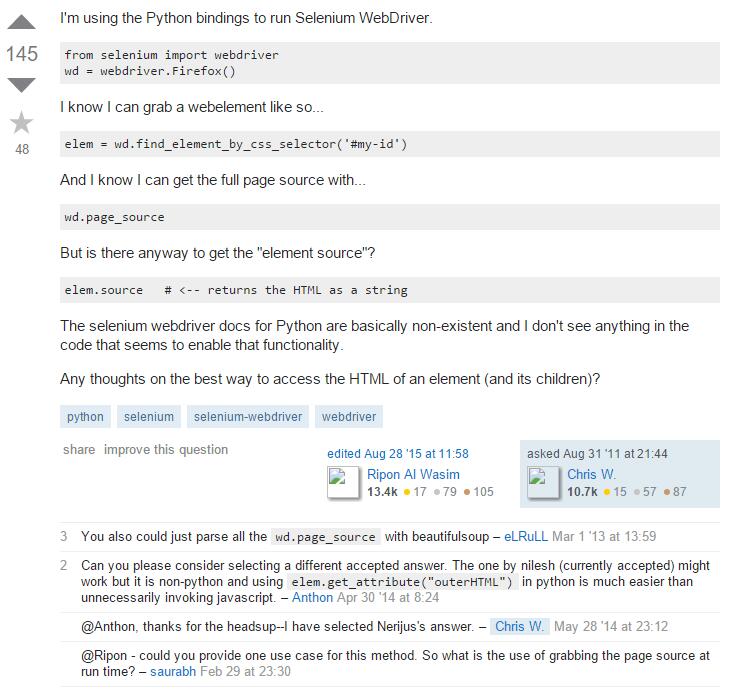
然而,百度遍中文內容並無解答。於是翻出去Google了一把,發現世界上已有前輩對該問題進行了解答:
主要思路是使用get_attribute方法,提取innerHTML,如下:
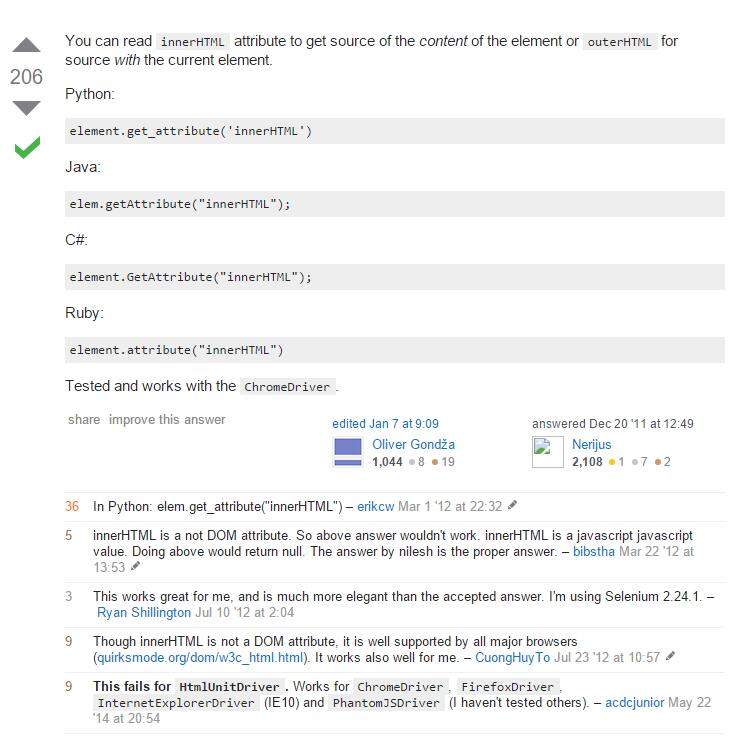
經驗證,一切OK: