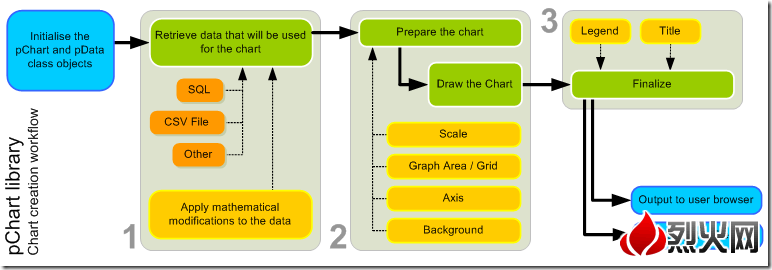
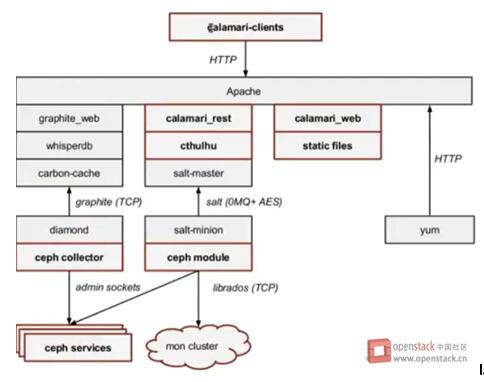
 Calamari的架構圖
Calamari的架構圖其中紅框部分為Calamari代碼實現的部分,非紅框部分為非Calamari實現的開源框架。
在Cephserver node安裝的組件有Diamond和Salt-minion。Diamond負責收集監控數據,它支持非常多的數據類型和metrics;每一個類型的數據都是上圖中的一個collector,它除了收集Ceph本身的狀態信息,它還可以收集關鍵的資源使用情況和性能數據,包括CPU,內存,網絡,I / O負載和磁盤指標。Collector都是使用本地的命令行來收集數據,然後報告給Graphite。
Graphite不僅是一個企業級的監控工具, 還可以實時繪圖。carbon-cache是Python實現的高度可擴展的事件驅動的I/O架構的後端進程,它可以有效地跟大量的客戶端通信並且以較低的開銷處理大量的業務量。
Whisper跟RRDtool類似,提供數據庫開發庫給應用程序來操縱和檢索存儲在特殊格式的文件數據(時間數據點數據),Whisper最基本的操作是創建作出新的Whisper文件,更新寫入新的數據點到一個文件中,並獲取檢索的數據點
Graphite_web是用戶接口,用來生成圖片,用戶可以直接通過URL的方式訪問這些生成的圖片。
Calamari 使用了Saltstack讓Calamari Server和Ceph server node通信。Saltstack是一個開源的自動化運維管理工具,與Chef和Puppet功能類似。Salt-master發送指令給指定的Salt-minion來完成對Cpeh Cluster的管理工作;Salt-minion 在Ceph server node安裝後都會從master同步並安裝一個ceph.py文件,裡面包含Ceph操作的API,它會調用librados或命令行來最終和Ceph Cluster通信。
calamari_rest提供Calamari REST API,詳細的接口請大家參照官方文檔。Ceph的REST API是一種低層次的接口,其中每個URL直接映射到等效的CEPH CLI;Calamari REST API提供了一個更高層次的接口,API的使用者可以習慣的使用GET/POST/PATCH方法來操作對象,而無需知道底層的Ceph的命令;它們之間的主要區別在於,Ceph的REST API的使用者需要非常了解Ceph本身,而Calamari 的REST API更貼近對Ceph資源的描述,所以更加適合給上層的應用程序調用。
cthulhu可以理解是Calamari Server的Service層,對上為API提供接口,對下調用Salt-master。
calamari_clients是一套用戶界面,Calamari Server在安裝的過程中會首先創建opt/calamari/webapp目錄,並且把webapp/calamari下的manager.py(django 配置)文件考進去, calamari_web的所有內容到要放到opt/calamari/webapp下面來提供UI的訪問頁面。
calamari-web包下面的文件提供所有web相關的配置,calamari_rest和calamari_clients都要用到。在Calamari的基礎之上進行新的功能開發,主要分為如下的幾個模塊,這部分包括Rest-API部分,Cthulhu、salt客戶端的擴展。關於擴展新功能的基本步驟如下:
>> 擴展URL模塊,確定對應的響應接口參數、對應ViewSet中的響應接口。
>> 完成ViewSet中部分接口的實現,這部分主要涉及與cthulhu的交互,如何獲取數據信息,有些情況下還需要獲取serializer中對象的序列化操作。
>> 完成後台rpc.py中對應類型的擴展,這部分主要是針對部分的post操作。
>> 完成cluster_monitor.py的擴展,對於提供操作的部分功能需要支持create、update、delete等操作,必須提供對應的RequestFactory。而在cluster_monitor.py中需要將對應的RequestFactory添加代碼中。
>> 完成對應RequestFactory類的編寫,這部分主要是完成命令操作的封裝。並構建對應的請求操作。
>> salt-minion的擴展,這部分主要是針對ceph.py文件的擴展,當然也可以提供新的xxx.py文件。
接下來以PG的控制和操作為例進行說明。
目前Calmamari采用Rest-API形式,采用Django的Rest-Framework框架支持,這部分在rest-api代碼目錄中。Django采用Url和代碼邏輯分離的實現方式,因此URL可以單獨的擴展。
在rest-api/calamari-rest/urls/v2.py中添加如下的有關PG的URL:
url(r'^cluster/(?P<fsid>[a-zA-Z0-9-]+)/pool/(?P<pool_id>\d+)/pg$', calamari_rest.views.v2.PgViewSet.as_view({'get': 'list'}), name='cluster-pool-pg-list'),
url(r'^cluster/(?P<fsid>[a-zA-Z0-9-]+)/pool/(?P<pool_id>\d+)/pg/(?P<pg_id>[0-9a-fA-F]+\.[0-9a-fA-F]+)/command/(?P<command>[a-zA-Z_]+)$',
calamari_rest.views.v2.PgViewSet.as_view({'post': 'apply'}),
name='cluster-pool-pg-control'),
以上定義了兩個URL,分別是:
api/v2/cluster/xxxx/pool/x/pg
api/v2/cluster/xxxx/pool/x/pg/xx/command/xxx
以上兩個URL分別指定了PgViewSet中的接口,url的get方法對應了list接口。post接口對應的apply接口。這兩個接口就是PgViewSet中必須實現的。
在擴展URL之後,接下來就是進行對應響應接口的擴展,這部分的擴展主要是針對在URL中指定的接口類進行實現。在之前的PG指定了兩個不同的接口,分別是獲取和操作命令,對應的代碼路徑為/rest-api/calamari-rest/view/v2.py,具體的代碼如下:
class PgViewSet(RPCViewSet):
serializer_class= PgSerializer
deflist(self, request, fsid, pool_id):
poolName = self.client.get(fsid, POOL, int(pool_id))['pool_name']
pg_summary = self.client.get_sync_object(fsid, PgSummary.str)
pg_pools = pg_summary['pg_pools']['by_pool'][int(pool_id)]
forpg in pg_pools:
pg['pool'] = poolName
return Response(PgSerializer(pg_pools, many=True).data)
defapply(self, request, fsid, pool_id, pg_id, command):
return Response(self.client.apply(fsid, PG, pg_id, command), status=202)
從如上的實現可知,代碼實現了兩個接口,分別是list和apply接口,即對應與之前的get、post操作。以上兩個操作都會與後台cthulhu進行交互。分別是獲取參數和提交請求。返回內容也有一定的差異。
同時在list接口中進行了序列化設置,即PgSerializer,該實現在rest-api/calamari-rest/serializer/v2.py中。
通常在Rest-Api中會進行數據的序列化,這部分並不是一定要進行的,通常在需要更改的操作中是有必要的。如下是Pg的序列化操作:
class PgSerializer(serializers.Serializer):
classMeta:
fields = ('id', 'pool', 'state', 'up', 'acting', 'up_primary','acting_primary')
id =serializers.CharField(source='pgid')
pool =serializers.CharField(help_text='pool name')
state =serializers.CharField(source='state', help_text='pg state')
up =serializers.Field(help_text='pg Up set')
acting =serializers.Field(help_text='pg acting set')
up_primary = serializers.IntegerField(help_text='pg up primary')
acting_primary =serializers.IntegerField(help_text='pg acting primary')
這部分並不是必須的。有些模塊可能不存在這部分的操作。在之前的三個步驟中基本上就實現了Rest-API部分的擴展,其中主要的ViewSet的擴展。有關ViewSet實際上實現了cthulhu與rest-api的交互方法。
在ViewSet的擴展中實際上采用了rpc與後台交互,因此在cthulhu的實現部分主要是處理對應的rpc請求。
rpc.py中實現了所有請求的操作,但是新擴展的操作也是需要支持擴展的,以pg為例繼續說明:
defapply(self, fs_id, object_type, object_id, command):
"""
Apply commands that do not modify an object in a cluster.
"""
cluster = self._fs_resolve(fs_id)
ifobject_type == OSD:
# Run a resolve to throw exception if it's unknown
self._osd_resolve(cluster, object_id)
return cluster.request_apply(OSD, object_id, command)
elifobject_type == PG:
return cluster.request_apply(PG,object_id, command)
else:
raise NotImplementedError(object_type)
而Pg的列表是通過PgSummary獲取。這部分在之前的實現中已存在,之前的代碼實現如下:
defget_sync_object(self, fs_id, object_type, path=None):
"""
Getone of the objects that ClusterMonitor keeps a copy of from the mon, such
asthe cluster maps.
:param fs_id: The fsid of a cluster
:param object_type: String, one of SYNC_OBJECT_TYPES
:param path: List, optional, a path within the object to return insteadof the whole thing
:return: the requested data, or None if it was not found (including ifany element of ``path``
was not found)
"""
ifpath:
obj =self._fs_resolve(fs_id).get_sync_object(SYNC_OBJECT_STR_TYPE[object_type])
try:
for part in path:
if isinstance(obj, dict):
obj = obj[part]
else:
obj = getattr(obj, part)
except (AttributeError, KeyError) as e:
log.exception("Exception %s traversing %s: obj=%s" % (e, path,obj))
raise NotFound(object_type, path)
return obj
else:
returnself._fs_resolve(fs_id).get_sync_object_data(SYNC_OBJECT_STR_TYPE[object_type])
有關請求的操作都會進行集群的控制,這部分可以通過cluster_monitor進行實現,以pg為例進行說明。
def__init__(self, fsid, cluster_name, notifier, persister, servers, eventer,requests):
super(ClusterMonitor, self).__init__()
self.fsid = fsid
self.name = cluster_name
self.update_time = datetime.datetime.utcnow().replace(tzinfo=utc)
self._notifier = notifier
self._persister= persister
self._servers = servers
self._eventer = eventer
self._requests = requests
#Which mon we are currently using for running requests,
#identified by minion ID
self._favorite_mon = None
self._last_heartbeat = {}
self._complete = gevent.event.Event()
self.done = gevent.event.Event()
self._sync_objects = SyncObjects(self.name)
self._request_factories = {
CRUSH_MAP: CrushRequestFactory,
CRUSH_NODE: CrushNodeRequestFactory,
OSD: OsdRequestFactory,
POOL: PoolRequestFactory,
CACHETIER: CacheTierRequestFactory,
PG: PgRequestFactory,
ERASURE_PROFILE: ErasureProfileRequestFactory,
ASYNC_COMMAND: AsyncComRequestFactory
}
self._plugin_monitor = PluginMonitor(servers)
self._ready = gevent.event.Event()
這部分主要是將對應的請求與對應的請求工廠類進行綁定,這樣才能產生出合適的請求。
該工廠類主要是針對不同的需求,實現具體的接口類,不同的對象有不同的請求類,以Pg為例說明:
from cthulhu.manager.request_factory importRequestFactory
from cthulhu.manager.user_request importRadosRequest
from calamari_common.types importPG_IMPLEMENTED_COMMANDS, PgSummary
class PgRequestFactory(RequestFactory):
def scrub(self,pg_id):
return RadosRequest(
"Initiating scrub on{cluster_name}-pg{id}".format(cluster_name=self._cluster_monitor.name,id=pg_id),
self._cluster_monitor.fsid,
self._cluster_monitor.name,
[('pg scrub', {'pgid': pg_id})])
defdeep_scrub(self, pg_id):
return RadosRequest(
"Initiating deep-scrub on{cluster_name}-osd.{id}".format(cluster_name=self._cluster_monitor.name,id=pg_id),
self._cluster_monitor.fsid,
self._cluster_monitor.name,
[('pg deep-scrub', {'pgid': pg_id})])
defrepair(self, pg_id):
return RadosRequest(
"Initiating repair on{cluster_name}-osd.{id}".format(cluster_name=self._cluster_monitor.name,id=pg_id),
self._cluster_monitor.fsid,
self._cluster_monitor.name,
[('pg repair', {'pgid': pg_id})])
defget_valid_commands(self, pg_id):
ret_val = {}
file('/tmp/pgsummary.txt', 'a+').write(PgSummary.str + '\n')
pg_summary = self._cluster_monitor.get_sync_object(PgSummary)
pg_pools = pg_summary['pg_pools']['by_pool']
pool_id = int(pg_id.split('.')[0])
pool= pg_pools[pool_id]
forpg in pool:
if pg['pgid'] == pg_id:
ret_val[pg_id] = {'valid_commands': PG_IMPLEMENTED_COMMANDS}
else:
ret_val[pg_id] = {'valid_commands': []}
return ret_val
該類中實現了三個不同的命令的實現,該命令主要是進行對應的封裝,這部分關鍵字需要根據ceph源碼中的參數進行選擇,因此在編碼時需要參照ceph源碼中對應命令的json參數名。