昨天想批處理以前下載的一堆文件,把文件裡的關鍵內容用正則匹配出來,集中處理。在操作文件時遇到一個問題,就是windows操作系統中的編碼問題。
我們都知道windows中(當然是中文版),文件名和文件內容等編碼都是gbk,而我們在開發過程中,IDE裡的編碼則是UTF-8,(這裡不討論為什麼等等問題,
只考慮怎麼把編碼轉變成一樣的)所以導致我寫的UTF-8編碼的正則模式字符串中的中文在gbk編碼的文件中並不能正確匹配。
一開始,我並沒有什麼辦法,試過把PHP腳本文件的編碼也改成GBK,也可以用,但是想到這種方法太low了,所以找一找PHP中有沒有函數可以滿足我的需求。
這時,我想到了以前在處理windows中的文件名時用的函數iconv(),其函數原型如下:
string iconv ( string $in_charset , string $out_charset , string $str )
Performs a character set conversion on the string str from in_charset to out_charset.
我們常使用:
$out_charset='utf-8'; $fileName=iconv($fileName,$out_charset,'gbk');
來處理文件名,將文件名改從gbk改為UTF-8而內容不變。
手冊翻譯附加:
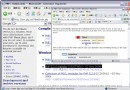
但是,我在用這個函數處理時,結果卻是這樣:

意思是iconv()函數能處理的最大字符數只有64,一般的文件名大小,而我的文件內容很顯然不止64個字符。
沒有辦法,我只好再次各種翻找別的函數。
直到我發現了mb_string函數庫,這個函數庫一般都在PHP環境裡集成,我們可以在phpinfo()裡找到它。

mb_string函數裡有一個mb_convert_encoding()函數,可以將一個字符串的編碼改變,其函數原型如下:
string mb_convert_encoding ( string $str , string $to_encoding [, mixed $from_encoding ] )
Converts the character encoding of string str to to_encoding from optionally from_encoding.
基原型跟iconv()函數差不多,只是它沒有對輸出函數的後綴修飾,它也沒有對字符串長度的明確限制。
而且我們看到$from_encoding是可選的,它可以自動識別源編碼。
因為找不到一個確切的無法轉碼的字符,也不知道它遇到無法轉碼的字符會怎麼處理。
通過mb_convert_encoding()函數,將整個文件處理了一下,於是,問題順利解決。
最後介紹一下mb_string函數庫,它全名叫Multibyte String,它的很多方法都擴展自PHP自身的string函數庫,函數名在原函數的前面加了"mb_",這些函數除了擁有原函數的作用外,還在可選參數的最後加入了一個$encoding的可選參數,這個參數可以規定函數以什麼樣的編碼方式來處理字符串。
例如strpos()函數,找到一個字符串在另一個字符串中的位置。
strpos("歡迎來訪問","問",0)返回的結果是12,因為腳本是UTF-8編碼,而將字符串轉為UTF-8編碼後,每個中文字符會占用3個字節。
而在mb_strpos()函數中,mb_strpos("歡迎來訪問","問",0,'utf-8')則會返回4,它會將字符串當作已經轉UTF-8的狀態執行。
而mb_strpos("歡迎來訪問","問",0,'gbk')會返回6
當然,它還有更多有特色的地方~
如果您覺得本博文對您有幫助,您可以推薦或關注我,如果您有什麼問題,可以在下方留言討論,謝謝。