看了不少朋友圈裡推薦的Python爬蟲文章,都覺得太小兒科,處理內容本來就是PHP的強項,Python唯一的好處估計也就天生的Linux自帶, 和Perl一樣,這點覺得挺不夠意思的Linux,還是Mac厚道,天生就自帶了Python、Perl、PHP、Ruby,當然我也很討厭討論一門語言 的好壞,每門語言存在就一定有它的道理,反正PHP是全世界最好用的語言,大家都懂的^_^
前幾天比較火的是一個人用C#寫了一個多線程爬蟲程序,抓取了QQ空間3000萬QQ用戶,其中有300萬用戶是有QQ號、昵稱、空間名稱等信息的,也就 是說,有詳情也就300萬,跑了兩周,這沒什麼,為了證明PHP是全世界最好的語言,雖然大家都懂的^_^,我用PHP寫了一個多進程爬蟲程序,只用了一 天時間,就抓了知乎100萬用戶,目前跑到第8圈(depth=8)互相有關聯(關注了和關注者)的用戶。
爬蟲程序設計:
因為知乎需要登錄才能獲取到關注者頁面,所以從chrome登錄之後把cookie拷貝下來給curl程序模擬登錄。
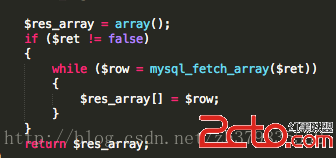
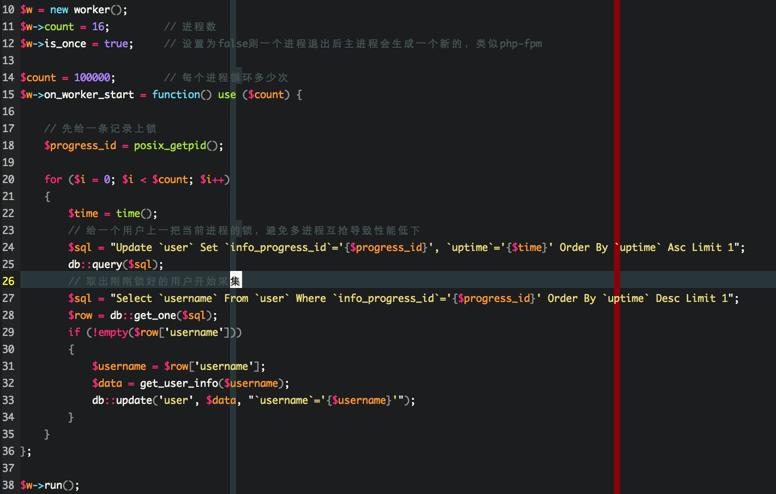
使用兩大獨立循環進程組(用戶索引進程組、用戶詳情進程組),用的是php的pcntl擴展,封裝了一個非常好用的類,使用起來和golang的攜程也差不多了。
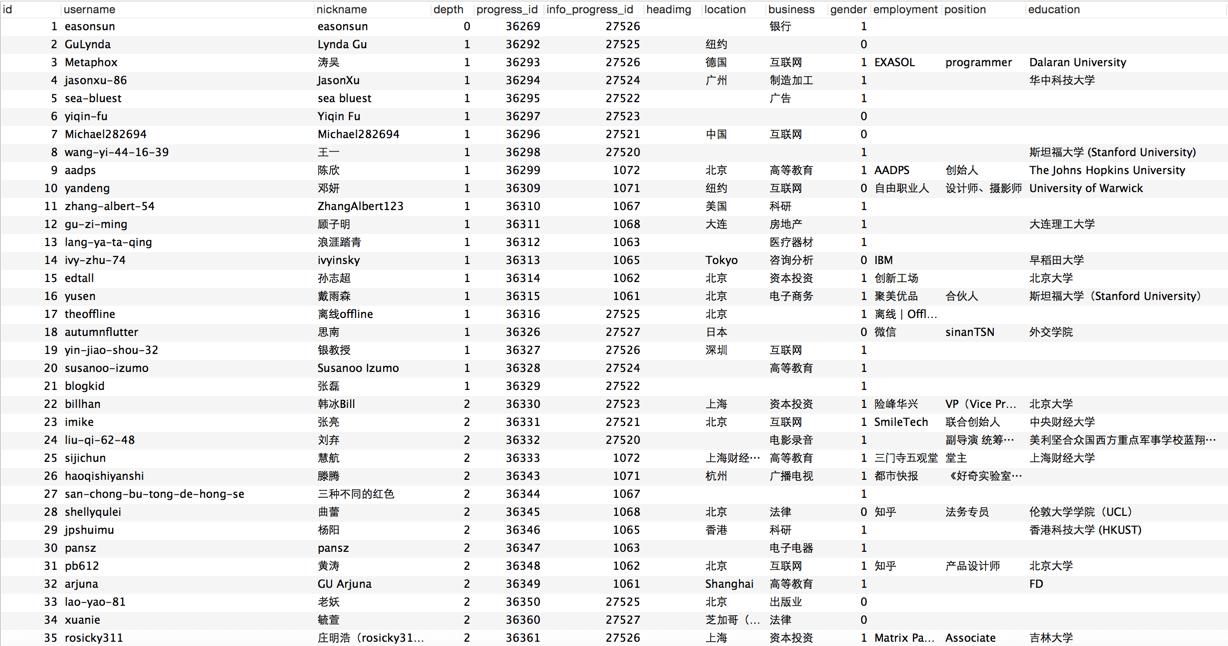
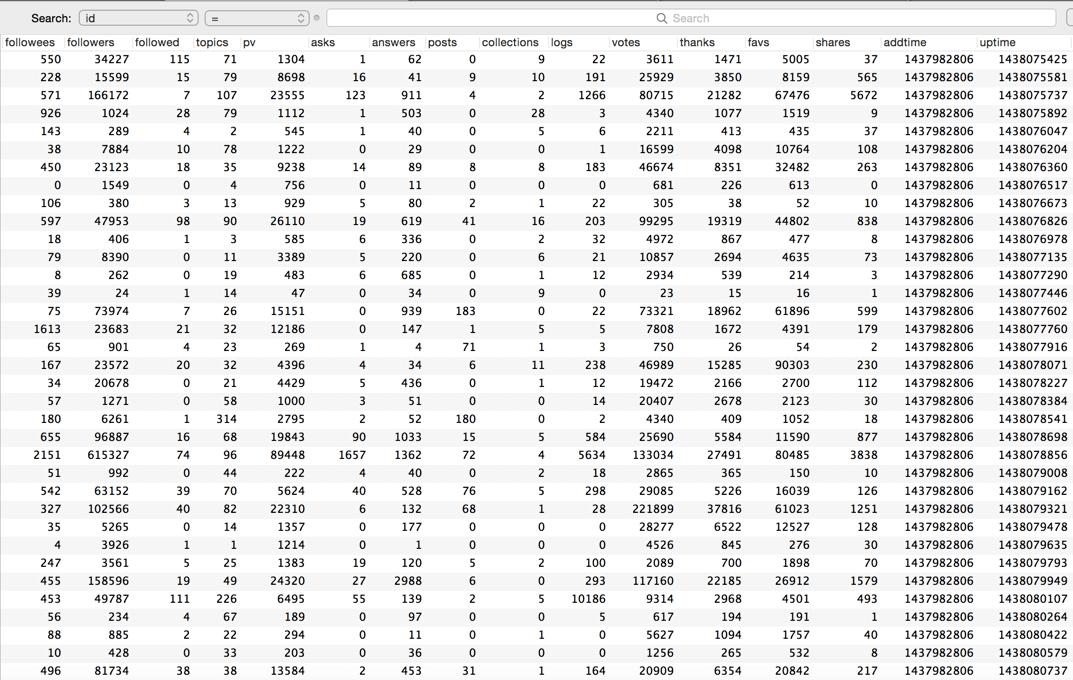
下面是用戶詳情的截圖,用戶索引代碼類似
這裡插個題外話,經過測試,我的8核的Macbook,跑16進程的速度最快,而16核的Linux服務器,居然是跑8進程最快,這點有點讓我莫名其妙了,不過既然測試出最後進程數,就按照最好的設置就好啦。
1、用戶索引進程組先以一個用戶為起點,抓取這個用戶的關注了和關注者,然後合並入庫,因為是多進程,所以當有兩個進程在處理同一個用戶入庫的時候就會出 現重復的用戶,所以數據庫用戶名字段一定要建立唯一索引,當然也可以用redis這些第三方緩存來保證原子性,這個就見仁見智了。
通過步驟一之後,我們就得到下面的用戶列表:

2、用戶詳情進程組按照時間正序,拿到最先入庫的用戶抓取詳情,並且把更新時間更新為當前時間,這樣就可以變成一個死循環,程序可以無休止的跑,不斷的循環更新用戶信息。
程序穩定運行到第二天,突然沒有新數據了,檢查了一下發現知乎改規則了,不知是為了防我,還是碰巧,反正給我返回的數據是這樣的

第一感覺就是胡亂給我輸出數據讓我采集不到,換了IP、模擬偽裝了些數據,都沒用,突然感覺這個很熟悉,會不會是gzip?抱著懷疑的態度,試了試gzip,首先當然是告訴知乎不要給我gzip壓縮過的數據
把 "Accept-Encoding: gzip,deflate\r\n"; 去掉,然並卵!
看來知乎是強制要給我gzip壓縮數據了,既然如此,那我就解壓呗,查了一下php解壓gzip,發現就一個函數gzinflate,於是把獲取到得內容加上:
$content = substr($content, 10);
$content = gzinflate($content));
當然還可以用curl自帶的:
curl_setopt( self::$ch, CURLOPT_ENCODING, 'gzip' );
這裡我真想說,PHP真的是全世界最好的語言,就一兩個函數,就徹底解決了問題,程序又歡快的跑起來了。
在匹配內容的時候,知乎的細心也是給了我無數的幫助,例如我要分清用戶性別:


哈哈開玩笑的拉,其實是樣式裡面有 icon-profile-female 和 icon-profile-male ^_^
我蛋疼的抓了它那麼多用戶,到底有什麼用呢?
其實沒什麼用,我就是閒的蛋疼 ^_^
有了這些信息,其實就可以做一些別人開頭閉口就亂吹一通的大數據分析拉
最常見的當然是:
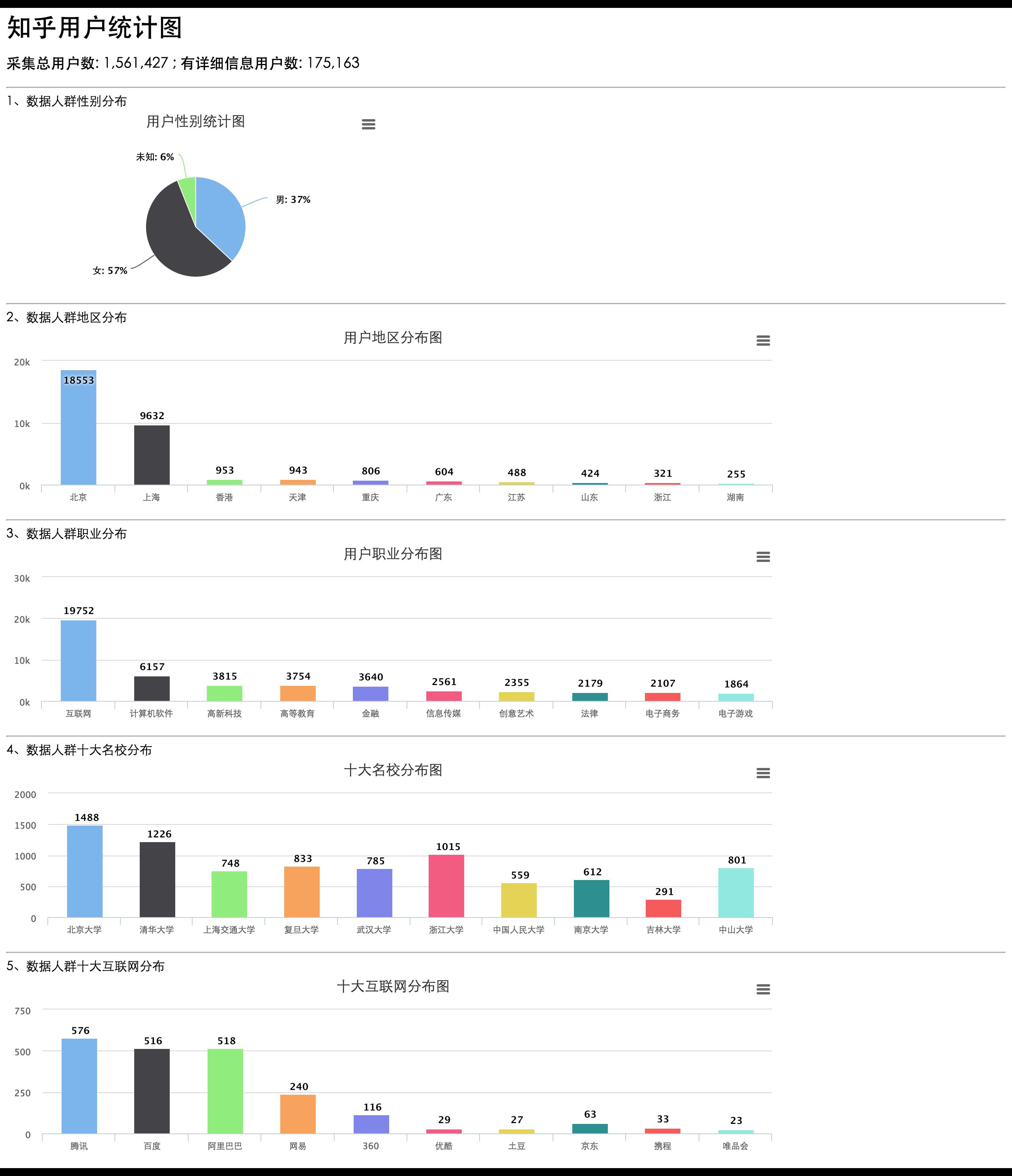
1、性別分布
2、地域分布
3、職業分布,來自那個公司
4、每個職業的男女比例
5、大家一般在什麼時候上知乎?發問題、關注問題,那些問題值得關注
當然,按照關注人數、浏覽人數、提問數、回答數等排序,看看人民都在關注什麼,民生、社會、地理、政治,整個互聯網都盡收眼底拉。。
也許,你還可以把頭像拿來分析,用開源的驗黃程序,把色情的篩選出來,然後去拯救東莞? ^_^
然後,你還可以看看那些大學出來的人,最後都干了什麼。
有了這些數據,是不是可以打開腦洞 ^_^
下面是利用這些數據做出來的一些有趣的圖表,實時圖表數據可以去 http://www.epooll.com/zhihu/ 上看