大家在自己的程序中相信都會經常用到截取字符串吧,但是往往遇到截取中文字符串的時候會遇到亂碼的問題。很是讓人頭疼,接下來介紹兩種方法防止截取中文字符串的時候出現亂碼的問題。
首先第一種,自己寫好的一個函數方便使用
利用這個函數截取就不會出現亂碼了。
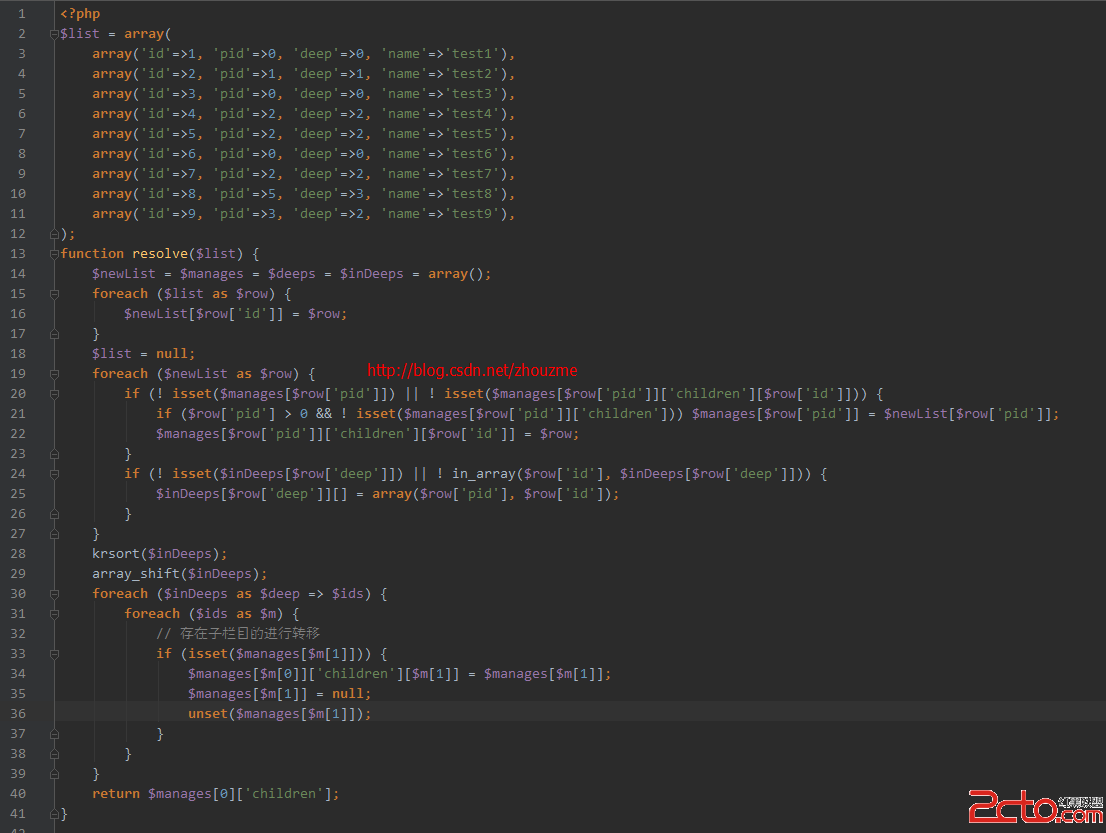
/**
* 支持中文字符串截取
*/
function msubstr($str, $start=0, $length, $charset="utf-8", $suffix=true){
switch($charset){
case 'utf-8':$char_len=3;break;
case 'UTF8':$char_len=3;break;
default:$char_len=2;
}
//小於指定長度,直接返回
if(strlen($str)<=($length*$char_len)){
return $str;
}
if(function_exists("mb_substr")){
$slice= mb_substr($str, $start, $length, $charset);
}else if(function_exists('iconv_substr')){
$slice=iconv_substr($str,$start,$length,$charset);
}else{
$re['utf-8'] = "/[\x01-\x7f]|[\xc2-\xdf][\x80-\xbf]|[\xe0-\xef][\x80-\xbf]{2}|[\xf0-\xff][\x80-\xbf]{3}/";
$re['gb2312'] = "/[\x01-\x7f]|[\xb0-\xf7][\xa0-\xfe]/";
$re['gbk'] = "/[\x01-\x7f]|[\x81-\xfe][\x40-\xfe]/";
$re['big5'] = "/[\x01-\x7f]|[\x81-\xfe]([\x40-\x7e]|\xa1-\xfe])/";
preg_match_all($re[$charset], $str, $match);
$slice = join("",array_slice($match[0], $start, $length));
}
if($suffix)
return $slice;
return $slice;
}
第二種是php內置的一個函數mb_substr函數
指定要截取的字符串的編碼格式,就能有效的防止出現亂碼了。
說明
string mb_substr ( string $str , int $start [, int $length [, string $encoding ]] )
<?php
function substr_unicode($str, $s, $l = null) {
return join("", array_slice(
preg_split("//u", $str, -1, PREG_SPLIT_NO_EMPTY), $s, $l));
}
$str = "Büyük";
$s = 0; // start from "0" (nth) char
$l = 3; // get "3" chars
echo substr($str, $s, $l) ."\n";
echo mb_substr($str, $s, $l) ."\n";
echo substr_unicode($str, $s, $l);
?>
以上所述就是本文的全部內容了,希望大家能夠喜歡。