今天抽了一上午時間,來看了看之前解決過內存問題的代碼,相對來說,我對自己代碼的優化程序非常不滿意,一次性導入四萬條數據就使代碼變得如此繁瑣,我想這不是根本的解決方法。通過網上檢索,對問題有進一步的分析:
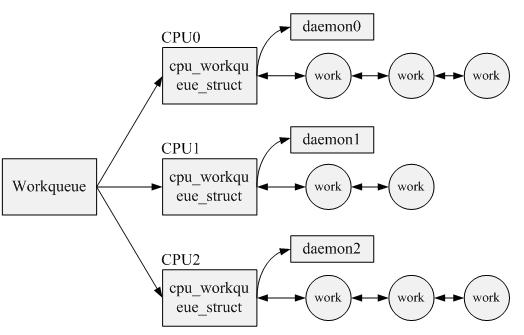
在php內存溢出的問題中,前兩種方法就不提了(可以參考《關於php內存釋放問題》在博園中),不難分析出,其實問題的關鍵在於如何在循環中同步釋放內存,而不是循環幾百條來釋放一次,因為大家在調試中會發現,如果我們把循環中復用性較高的代碼封裝到函數中,然後使用調用子函數的形式,會是程序的執行速度降低,大約幾十倍左右,這個下降幅度會隨著數據量的不同而改變。
循環嵌套的形式,在處理較大數據量的數組,有很多使用 unset($a),的形式來及時釋放內存,但是 實際上這麼做是沒有意義的,引用以下分析:
”在引擎中,變量名和它們的值實際上是兩個不同的概念。值本身是一個無名的zval*存儲體(在本例中,是一個字符串值),它被通過zend_hash_add()賦給變量$a。如果兩個變量名都指向同一個值,會發生什麼呢?
此時,你可以實際地觀察$a或$b,並且會看到它們都包含字符串"Hello World"。遺憾的是,接下來,你繼續執行第三行代碼"unset($a);"。此時,unset()並不知道$a變量指向的數據還被另一個變量所使用,因此它只是盲目地釋放掉該內存。任何隨後的對變量$b的存取都將被分析為已經釋放的內存空間並因此導致引擎崩潰。
這個問題可以借助於zval(它有好幾種形式)的第四個成員refcount加以解決。當一個變量被首次創建並賦值時,它的refcount被初始化為1,因為它被假定僅由最初創建它時相應的變量所使用。當你的代碼片斷開始把helloval賦給$b時,它需要把refcount的值增加為2;這樣以來,現在該值被兩個變量所引用:
現在,當unset()刪除原變量的$a相應的副本時,它就能夠從refcount參數中看到,還有另外其他人對該數據感興趣;因此,它應該只是減少refcount的計數值,然後不再管它。“
綜上,我們最需要做的其實是減少最初存儲數據的數組,上面的例子,在循環中及時釋放掉數組中已經處理完的元素,這樣隨著循環,內存占用量的會一直上下波動(內存回收機制問題),但不會一直增長,也就達到了我們最初的目的。當然,一次性最大的數據處理量還是取決於服務器給php分配的內存,單次數據量讀入數組就超出了限制,哪就是神仙也沒有辦法了,哈哈