今天在調取一家商城的頁面信息時候,使用file_get_contents抑或curl:
復制代碼 代碼如下:
$url = 'http://www.xxx.com/21/?type=23′;
$temp = file_get_contents($url);
echo $temp;
都得到一片亂碼,查看了許多內容,包括頁面的header信息,發現原來頁面使用了。
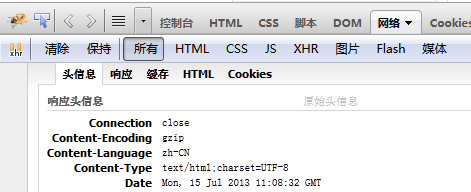
類似的信息,即Content-Encoding為gzip,即該站點開啟了gzip壓縮。這裡的解決方案有多種,當然如果你使用file_get_contents的話,可以這樣修改:
復制代碼 代碼如下:
file_get_contents("compress.zlib://".$url);
或者使用curl來完成:
復制代碼 代碼如下:
function curl_get($url, $gzip=false){
$curl = curl_init($url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_CONNECTTIMEOUT, 10);
if($gzip) curl_setopt($curl, CURLOPT_ENCODING, "gzip"); // 關鍵在這裡
$content = curl_exec($curl);
curl_close($curl);
return $content;
}
同時,參考手冊上面的解法,還可以對保存gzip類型的字符串進行處理如下:
復制代碼 代碼如下:
function gzdecode($data){
$g=tempnam(‘/tmp','ff');
@file_put_contents($g,$data);
ob_start();
readgzfile($g);
$d=ob_get_clean();
return $d;
}