來源:http://www.ido321.com/1158.html
抓取某一個網頁中的內容,需要對DOM樹進行解析,找到指定節點後,再抓取我們需要的內容,過程有點繁瑣。LZ總結了幾種常用的、易於實現的網頁抓取方式,如果熟悉JQuery選擇器,這幾種框架會相當簡單。
一、Ganon
項目地址: http://code.google.com/p/ganon/
文檔: http://code.google.com/p/ganon/w/list
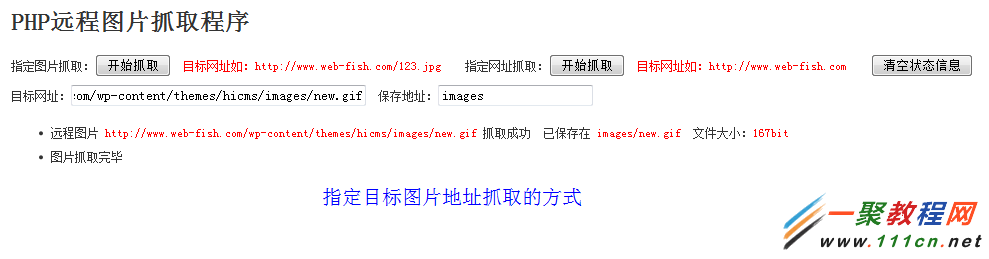
測試:抓取我的網站首頁所有class屬性值是focus的div元素,並且輸出class值
<?php
include 'ganon.php';
$html = file_get_dom('http://www.ido321.com/');
foreach($html('div[class="focus"]') as $element) {
echo $element->class, "<br>\n";
}
?>
結果:
二、phpQuery
項目地址:http://code.google.com/p/phpquery/
文檔:https://code.google.com/p/phpquery/wiki/Manual
測試:抓取我網站首頁的article標簽元素,然後出書其下h2標簽的html值
<?php
include 'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('http://www.ido321.com/');
$artlist = pq("article");
foreach($artlist as $title){
echo pq($title)->find('h2')->html()."<br/>";
}
?>
結果:
三、Simple-Html-Dom
項目地址: http://simplehtmldom.sourceforge.net/
文檔: http://simplehtmldom.sourceforge.net/manual.htm
測試:抓取我網站首頁的所有鏈接
<?php
include 'simple_html_dom.php';
//使用url和file都可以創建DOM
$html = file_get_html('http://www.ido321.com/');
//找到所有圖片
// foreach($html->find('img') as $element)
// echo $element->src . '<br>';
//找到所有鏈接
foreach($html->find('a') as $element)
echo $element->href . '<br>';
?>
結果:(截圖是一部分)
四、Snoopy
項目地址:http://code.google.com/p/phpquery/
文檔:http://code.google.com/p/phpquery/wiki/Manual
測試:抓取我的網站首頁
<?php
include("Snoopy.class.php");
$url = "http://www.ido321.com";
$snoopy = new Snoopy;
$snoopy->fetch($url); //獲取所有內容
echo $snoopy->results; //顯示結果
// echo $snoopy->fetchtext ;//獲取文本內容(去掉html代碼)
// echo $snoopy->fetchlinks($url) ;//獲取鏈接
// $snoopy->fetchform ;//獲取表單
?>
結果:
五、手動編寫爬蟲
如果編寫能力ok,可以手寫一個網頁爬蟲,實現網頁抓取。網上有千篇一律的介紹此方法的文章,LZ就不贅述了。有興趣了解的,可以百度 php 網頁抓取。
ps:資源分享
常見的開源爬蟲項目請戳:http://blog.chinaunix.net/uid-22414998-id-3774291.html
下一篇:國民岳父的“屁民理論”
樓主,你可以使用simpl_html_dom 這個類來采集,具體怎麼使用,如果你會jquery的話,相信你看一下就懂了。祝你好運。
strip_tags($string)