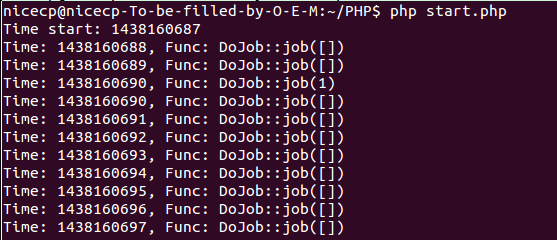
Android字符串格式化開源庫phrase介紹
在上一篇博客Android通過String.format格式化(動態改變)字符串資源的顯示內容中介紹了通過String.format來格式化string.xml文件中的字符串,本文介紹一個可以實現同樣功能的開源庫phrase,相比於String.format,通過phrase格式化字符串代碼更具可讀性。
一、phrase項目介紹:
1、源碼:phrase項目的源代碼很簡單,裡面總共只有一個類:Phrase.java,代碼如下:
/*
* Copyright (C) 2013 Square, Inc.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.uperone.stringformat;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
import android.app.Fragment;
import android.content.Context;
import android.content.res.Resources;
import android.text.SpannableStringBuilder;
import android.view.View;
/**
* A fluent API for formatting Strings. Canonical usage:
*
* CharSequence formatted = Phrase.from("Hi {first_name}, you are {age} years old.")
* .put("first_name", firstName)
* .put("age", age)
* .format();
*
*
* - Surround keys with curly braces; use two {{ to escape.
* - Keys start with lowercase letters followed by lowercase letters and underscores.
* - Spans are preserved, such as simple HTML tags found in strings.xml.
* - Fails fast on any mismatched keys.
*
* The constructor parses the original pattern into a doubly-linked list of {@link Token}s.
* These tokens do not modify the original pattern, thus preserving any spans.
*
* The {@link #format()} method iterates over the tokens, replacing text as it iterates. The
* doubly-linked list allows each token to ask its predecessor for the expanded length.
*/
public final class Phrase {
/** The unmodified original pattern. */
private final CharSequence pattern;
/** All keys parsed from the original pattern, sans braces. */
private final Set
keys = new HashSet();
private final Map keysToValues = new HashMap();
/** Cached result after replacing all keys with corresponding values. */
private CharSequence formatted;
/** The constructor parses the original pattern into this doubly-linked list of tokens. */
private Token head;
/** When parsing, this is the current character. */
private char curChar;
private int curCharIndex;
/** Indicates parsing is complete. */
private static final int EOF = 0;
/**
* Entry point into this API.
*
* @throws IllegalArgumentException if pattern contains any syntax errors.
*/
public static Phrase from(Fragment f, int patternResourceId) {
return from(f.getResources(), patternResourceId);
}
/**
* Entry point into this API.
*
* @throws IllegalArgumentException if pattern contains any syntax errors.
*/
public static Phrase from(View v, int patternResourceId) {
return from(v.getResources(), patternResourceId);
}
/**
* Entry point into this API.
*
* @throws IllegalArgumentException if pattern contains any syntax errors.
*/
public static Phrase from(Context c, int patternResourceId) {
return from(c.getResources(), patternResourceId);
}
/**
* Entry point into this API.
*
* @throws IllegalArgumentException if pattern contains any syntax errors.
*/
public static Phrase from(Resources r, int patternResourceId) {
return from(r.getText(patternResourceId));
}
/**
* Entry point into this API; pattern must be non-null.
*
* @throws IllegalArgumentException if pattern contains any syntax errors.
*/
public static Phrase from(CharSequence pattern) {
return new Phrase(pattern);
}
/**
* Replaces the given key with a non-null value. You may reuse Phrase instances and replace
* keys with new values.
*
* @throws IllegalArgumentException if the key is not in the pattern.
*/
public Phrase put(String key, CharSequence value) {
if (!keys.contains(key)) {
throw new IllegalArgumentException("Invalid key: " + key);
}
if (value == null) {
throw new IllegalArgumentException("Null value for '" + key + "'");
}
keysToValues.put(key, value);
// Invalidate the cached formatted text.
formatted = null;
return this;
}
/** @see #put(String, CharSequence) */
public Phrase put(String key, int value) {
if (!keys.contains(key)) {
throw new IllegalArgumentException("Invalid key: " + key);
}
keysToValues.put(key, Integer.toString(value));
// Invalidate the cached formatted text.
formatted = null;
return this;
}
/**
* Silently ignored if the key is not in the pattern.
*
* @see #put(String, CharSequence)
*/
public Phrase putOptional(String key, CharSequence value) {
return keys.contains(key) ? put(key, value) : this;
}
/** @see #put(String, CharSequence) */
public Phrase putOptional(String key, int value) {
return keys.contains(key) ? put(key, value) : this;
}
/**
* Returns the text after replacing all keys with values.
*
* @throws IllegalArgumentException if any keys are not replaced.
*/
public CharSequence format() {
if (formatted == null) {
if (!keysToValues.keySet().containsAll(keys)) {
Set missingKeys = new HashSet(keys);
missingKeys.removeAll(keysToValues.keySet());
throw new IllegalArgumentException("Missing keys: " + missingKeys);
}
// Copy the original pattern to preserve all spans, such as bold, italic, etc.
SpannableStringBuilder sb = new SpannableStringBuilder(pattern);
for (Token t = head; t != null; t = t.next) {
t.expand(sb, keysToValues);
}
formatted = sb;
}
return formatted;
}
/**
* Returns the raw pattern without expanding keys; only useful for debugging. Does not pass
* through to {@link #format()} because doing so would drop all spans.
*/
@Override public String toString() {
return pattern.toString();
}
private Phrase(CharSequence pattern) {
curChar = (pattern.length() > 0) ? pattern.charAt(0) : EOF;
this.pattern = pattern;
// A hand-coded lexer based on the idioms in "Building Recognizers By Hand".
// http://www.antlr2.org/book/byhand.pdf.
Token prev = null;
Token next;
while ((next = token(prev)) != null) {
// Creates a doubly-linked list of tokens starting with head.
if (head == null) head = next;
prev = next;
}
}
/** Returns the next token from the input pattern, or null when finished parsing. */
private Token token(Token prev) {
if (curChar == EOF) {
return null;
}
if (curChar == '{') {
char nextChar = lookahead();
if (nextChar == '{') {
return leftCurlyBracket(prev);
} else if (nextChar >= 'a' && nextChar <= 'z') {
return key(prev);
} else {
throw new IllegalArgumentException(
"Unexpected character '" + nextChar + "'; expected key.");
}
}
return text(prev);
}
/** Parses a key: "{some_key}". */
private KeyToken key(Token prev) {
// Store keys as normal Strings; we don't want keys to contain spans.
StringBuilder sb = new StringBuilder();
// Consume the opening '{'.
consume();
while ((curChar >= 'a' && curChar <= 'z') || curChar == '_') {
sb.append(curChar);
consume();
}
// Consume the closing '}'.
if (curChar != '}') {
throw new IllegalArgumentException("Missing closing brace: }");
}
consume();
// Disallow empty keys: {}.
if (sb.length() == 0) {
throw new IllegalArgumentException("Empty key: {}");
}
String key = sb.toString();
keys.add(key);
return new KeyToken(prev, key);
}
/** Consumes and returns a token for a sequence of text. */
private TextToken text(Token prev) {
int startIndex = curCharIndex;
while (curChar != '{' && curChar != EOF) {
consume();
}
return new TextToken(prev, curCharIndex - startIndex);
}
/** Consumes and returns a token representing two consecutive curly brackets. */
private LeftCurlyBracketToken leftCurlyBracket(Token prev) {
consume();
consume();
return new LeftCurlyBracketToken(prev);
}
/** Returns the next character in the input pattern without advancing. */
private char lookahead() {
return curCharIndex < pattern.length() - 1 ? pattern.charAt(curCharIndex + 1) : EOF;
}
/**
* Advances the current character position without any error checking. Consuming beyond the
* end of the string can only happen if this parser contains a bug.
*/
private void consume() {
curCharIndex++;
curChar = (curCharIndex == pattern.length()) ? EOF : pattern.charAt(curCharIndex);
}
private abstract static class Token {
private final Token prev;
private Token next;
protected Token(Token prev) {
this.prev = prev;
if (prev != null) prev.next = this;
}
/** Replace text in {@code target} with this token's associated value. */
abstract void expand(SpannableStringBuilder target, Map data);
/** Returns the number of characters after expansion. */
abstract int getFormattedLength();
/** Returns the character index after expansion. */
final int getFormattedStart() {
if (prev == null) {
// The first token.
return 0;
} else {
// Recursively ask the predecessor node for the starting index.
return prev.getFormattedStart() + prev.getFormattedLength();
}
}
}
/** Ordinary text between tokens. */
private static class TextToken extends Token {
private final int textLength;
TextToken(Token prev, int textLength) {
super(prev);
this.textLength = textLength;
}
@Override void expand(SpannableStringBuilder target, Map data) {
// Don't alter spans in the target.
}
@Override int getFormattedLength() {
return textLength;
}
}
/** A sequence of two curly brackets. */
private static class LeftCurlyBracketToken extends Token {
LeftCurlyBracketToken(Token prev) {
super(prev);
}
@Override void expand(SpannableStringBuilder target, Map data) {
int start = getFormattedStart();
target.replace(start, start + 2, "{");
}
@Override int getFormattedLength() {
// Replace {{ with {.
return 1;
}
}
private static class KeyToken extends Token {
/** The key without { and }. */
private final String key;
private CharSequence value;
KeyToken(Token prev, String key) {
super(prev);
this.key = key;
}
@Override void expand(SpannableStringBuilder target, Map data) {
value = data.get(key);
int replaceFrom = getFormattedStart();
// Add 2 to account for the opening and closing brackets.
int replaceTo = replaceFrom + key.length() + 2;
target.replace(replaceFrom, replaceTo, value);
}
@Override int getFormattedLength() {
// Note that value is only present after expand. Don't error check because this is all
// private code.
return value.length();
}
}
}
2、字符串格式化原理:
通過閱讀Phrase.java的代碼可知,它用"{"和"}"將需要格式化的內容包起來,然後用鍵值對給需要改變的內容傳值,包起來的內容為鍵,值為動態設置的內容,比如:
"Hi {first_name}, you are {age} years old."我們要最終的顯示內容為:“Hi UperOne, you are 26 years old.”這裡的first_name和age是鍵,值為UperOne和26。
二、使用方法:
Phrase.java的類名上面的注釋已經告訴了我們具體的使用方法:
/**
* A fluent API for formatting Strings. Canonical usage:
*
* CharSequence formatted = Phrase.from("Hi {first_name}, you are {age} years old.")
* .put("first_name", firstName)
* .put("age", age)
* .format();
*
*
* - Surround keys with curly braces; use two {{ to escape.
* - Keys start with lowercase letters followed by lowercase letters and underscores.
* - Spans are preserved, such as simple HTML tags found in strings.xml.
* - Fails fast on any mismatched keys.
*
* The constructor parses the original pattern into a doubly-linked list of {@link Token}s.
* These tokens do not modify the original pattern, thus preserving any spans.
*
* The {@link #format()} method iterates over the tokens, replacing text as it iterates. The
* doubly-linked list allows each token to ask its predecessor for the expanded length.
*/
public final class Phrase
比如:
CharSequence parseStr = Phrase.from("Hi {first_name}, you are {age} years old.")
.put("first_name", "UperOne")
.put("age", "26")
.format();
mParseTxt.setText( parseStr );用起來非常簡單。