前幾天有一朋友要我幫做一個采集新聞信息的程序,抽了點時間寫了個PHP版本的,隨筆記錄下。
說到采集,無非就是遠程獲取信息->提取所需內容->分類存儲->讀取->展示
也算是簡單"小偷程序"的加強版吧
下面是對應核心代碼(別拿去做壞事哦^_^)
所要采集的內容是某游戲網站上的公告,如下圖:
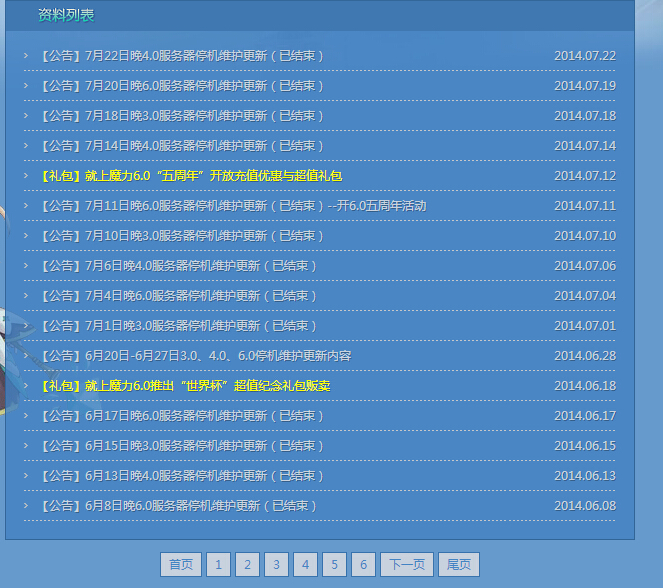
可先利用file_get_contents和簡單正則獲取基本頁面信息

整理下基本信息,采集入庫:
<?php
include_once("conn.php");
if($_GET['id']<=8&&$_GET['id']){
$id=$_GET['id'];
$conn=file_get_contents("http://www.93moli.com/news_list_4_$id.html");//獲取頁面內容
$pattern="/<li><a title=\"(.*)\" target=\"_blank\" href=\"(.*)\">/iUs";//正則
preg_match_all($pattern, $conn, $arr);//匹配內容到arr數組
//print_r($arr);die;
foreach ($arr[1] as $key => $value) {//二維數組[2]對應id和[1]剛好一樣,利用起key
$url="http://www.93moli.com/".$arr[2][$key];
$sql="insert into list(title,url) value ('$value', '$url')";
mysql_query($sql);
//echo "<a href='content.php?url=http://www.93moli.com/$url'>$value</a>"."<br/>";
}
$id++;
echo "正在采集URL數據列表$id...請稍後...";
echo "<script>window.location='list.php?id=$id'</script>";
}else{
echo "采集數據結束。";
}
?>
conn.php是數據庫連接文件
list.php是本頁面
由於要采集的數據是分頁顯示的,且頁面地址是規律遞增,所以我用了js跳轉代碼,利用id傳值控制采集的頁數,也避免了for循環數目過大。

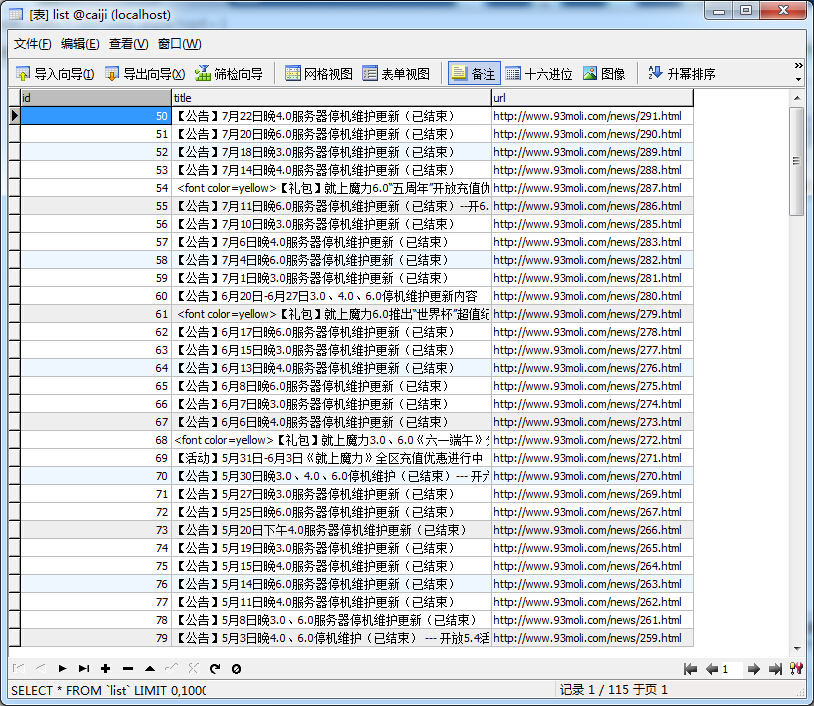
輕輕松松數據入庫,下篇博客寫關於具體url采集信息的過程。
php數據采集常見技術要領:
1、熟練正則表達式提取數據技術:提取內容關鍵步驟
2、熟練字符編碼轉換分析技術:兼容性管理以及數據有效性控制
3、熟練數據出庫入庫整理技術:對已采集內容的存儲管理,包括數據庫以及文件和進度
4、發掘數據以及網站爬行技術:分析網站結構,簡化爬行手法,提高效率
5、反反采集處理技術:對於存在反采集的目標對象而設計的反反采集技術
6、多服務器並發采集管理技術:提高效率的工作方法
7、數據整理分析技術:查漏驗證數據正確性有效性
8、自我身份保護技術:自身信息的保護
phpquery 用這個,自己再寫個入庫,