在任何語言中,函數都是最基本的組成單元。對於php的函數,它具有哪些特點?函數調用是怎麼實現的?php函數的性能如何,有什麼使用建議?本文將從原理出發進行分析結合實際的性能測試嘗試對這些問題進行回答,在了解實現的同時更好的編寫php程序。同時也會對一些常見的php函數進行介紹。
在php中,橫向劃分的話,函數分為兩大類:user function(內置函數)和internal function(內置函數)。前者就是用戶在程序中自定義的一些函數和方法,後者則是php本身提供的各類庫函數(比如sprintf、array_push等)。用戶也可以通過擴展的方法來編寫庫函數,這個將在後面介紹。對於user function,又可以細分為function(函數)和method(類方法),本文中將就這三種函數分別進行分析和測試。
一個php函數最終是如何執行,這個流程是怎麼樣的呢?
要回答這個問題,我們先來看看php代碼的執行所經過的流程。
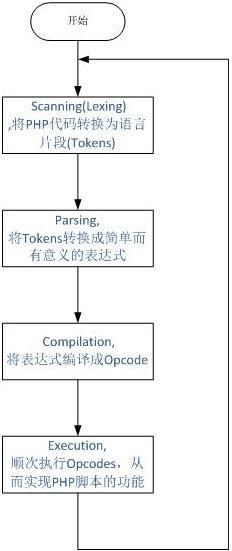
從上圖可以看到,php實現了一個典型的動態語言執行過程:拿到一段代碼後,經過詞法解析、語法解析等階段後,源程序會被翻譯成一個個指令(opcodes),然後ZEND虛擬機順次執行這些指令完成操作。Php本身是用c實現的,因此最終調用的也都是c的函數,實際上,我們可以把php看做是一個c開發的軟件。
通過上面描述不難看出,php中函數的執行也是被翻譯成了opcodes來調用,每次函數調用實際上是執行了一條或多條指令。
對於每一個函數,zend都通過以下的數據結構來描述:
typedef union _zend_function {
zend_uchar type; /* MUST be the first element of this struct! */
struct {
zend_uchar type; /* never used */
char *function_name;
zend_class_entry *scope;
zend_uint fn_flags;
union _zend_function *prototype;
zend_uint num_args;
zend_uint required_num_args;
zend_arg_info *arg_info;
zend_bool pass_rest_by_reference;
unsigned char return_reference;
} common;
zend_op_array op_array;
zend_internal_function internal_function;
} zend_function;
typedef struct _zend_function_state {
HashTable *function_symbol_table;
zend_function *function;
void *reserved[ZEND_MAX_RESERVED_RESOURCES];
} zend_function_state;
其中type標明了函數的類型:用戶函數、內置函數、重載函數。Common中包含函數的基本信息,包括函數名,參數信息,函數標志(普通函數、靜態方法、抽象方法)。
內置函數,其本質上就是真正的c函數,每一個內置函數,php在最終編譯後都會展開成為一個名叫zif_xxxx的function,比如我們常見的sprintf,對應到底層就是zif_sprintf。Zend在執行的時候,如果發現是內置函數,則只是簡單的做一個轉發操作。
Zend提供了一系列的api供調用,包括參數獲取、數組操作、內存分配等。內置函數的參數獲取,通過zend_parse_parameters方法來實現,對於數組、字符串等參數,zend實現的是淺拷貝,因此這個效率是很高的。可以這樣說,對於php內置函數,其效率和相應c函數幾乎相同,唯一多了一次轉發調用。
內置函數在php中都是通過so的方式進行動態加載,用戶也可以根據需要自己編寫相應的so,也就是我們常說的擴展。ZEND提供了一系列的api供擴展使用。
和內置函數相比,用戶通過php實現的自定義函數具有完全不同的執行過程和實現原理。如前文所述,我們知道php代碼是被翻譯成為了一條條opcode來執行的,用戶函數也不例外,實際中每個函數對應到一組opcode,這組指令被保存在zend_function中。於是,用戶函數的調用最終就是對應到一組opcodes的執行。
局部變量的保存及遞歸的實現:我們知道,函數遞歸是通過堆棧來完成的。在php中,也是利用類似的方法來實現。Zend為每個php函數分配了一個活動符號表(active_sym_table),記錄當前函數中所有局部變量的狀態。所有的符號表通過堆棧的形式來維護,每當有函數調用的時候,分配一個新的符號表並入棧。當調用結束後當前符號表出棧。由此實現了狀態的保存和遞歸。
對於棧的維護,zend在這裡做了優化。預先分配一個長度為N的靜態數組來模擬堆棧,這種通過靜態數組來模擬動態數據結構的手法在我們自己的程序中也經常有使用,這種方式避免了每次調用帶來的內存分配、銷毀。ZEND只是在函數調用結束時將當前棧頂的符號表數據clean掉即可。
因為靜態數組長度為N,一旦函數調用層次超過N,程序不會出現棧溢出,這種情況下zend就會進行符號表的分配、銷毀,因此會導致性能下降很多。在zend裡面,N目前取值是32。因此,我們編寫php程序的時候,函數調用層次最好不要超過32。當然,如果是web應用,本身可以函數調用層次的深度。
參數的傳遞:和內置函數調用zend_parse_params來獲取參數不同,用戶函數中參數的獲取是通過指令來完成的。函數有幾個參數就對應幾條指令。具體到實現上就是普通的變量賦值。通過上面的分析可以看出,和內置函數相比,由於是自己維護堆棧表,而且每條指令的執行也是一個c函數,用戶函數的性能相對會差很多,後面會有具體的對比分析。因此,如果一個功能有對應php內置函數實現的盡量不要自己重新寫函數去實現。
類方法其執行原理和用戶函數是相同的,也是翻譯成opcodes順次調用。類的實現,zend用一個數據結構zend_class_entry來實現,裡面保存了類相關的一些基本信息。這個entry是在php編譯的時候就已經處理完成。
在zend_function的common中,有一個成員叫做scope,其指向的就是當前方法對應類的zend_class_entry。關於php中面向對象的實現,這裡就不在做更詳細的介紹,今後將專門寫一篇文章來詳述php中面向對象的實現原理。就函數這一塊來說,method實現原理和function完全相同,理論上其性能也差不多,後面我們將做詳細的性能對比。
count是我們經常用到的一個函數,其功能是返回一個數組的長度。
count這個函數,其復雜度是多少呢?一種常見的說法是count函數會遍歷整個數組然後求出元素個數,因此復雜度是O(n)。那實際情況是不是這樣呢?
我們回到count的實現來看一下,通過源碼可以發現,對於數組的count操作,函數最終的路徑是zif_count-> php_count_recursive-> zend_hash_num_elements,而zend_hash_num_elements的行為是 return ht->nNumOfElements,可見,這是一個O(1)而不是O(n)的操作。實際上,數組在php底層就是一個hash_table,對於hash表,zend中專門有一個元素nNumOfElements記錄了當前元素的個數,因此對於一般的count實際上直接就返回了這個值。由此,我們得出結論: count是O(1)的復雜度,和具體數組的大小無關。
非數組類型的變量,count的行為時怎樣?對於未設置變量返回0,而像int、double、string等則會返回1。
Strlen用於返回一個字符串的長度。那麼,他的實現原理是如何的呢?
我們都知道在c中strlen是一個o(n)的函數,會順序遍歷字符串直到遇到\0,然後出長度。Php中是否也這樣呢?答案是否定的,php裡字符串是用一個復合結構來描述,包括指向具體數據的指針和字符串長度(和c++中string類似),因此strlen就直接返回字符串長度了,是常數級別的操作。
另外,對於非字符串類型的變量調用strlen,它會首先將變量強制轉換為字符串再求長度,這點需要注意。
這兩個函數最常見的用法都是判斷一個key是否在數組中存在。但是前者還可以用於判斷一個變量是否被設置過。如前文所述,isset並非真正的函數,因此它的效率會比後者高很多。推薦用它代替array_key_exists。
兩者都是往數組尾部追加一個元素。不同的是前者可以一次push多個。他們最大的區別在於一個是函數一個是語言結構,因此後者效率要更高。因此如果只是普通的追加元素,建議使用array[]。
兩者都是提供產生隨機數的功能,前者使用libc標准的rand。後者用了 Mersenne Twister 中已知的特性作為隨機數發生器,它可以產生隨機數值的平均速度比 libc 提供的 rand() 快四倍。因此如果對性能要求較高,可以考慮用mt_rand代替前者。
我們都知道,rand產生的是偽隨機數,在C中需要用srand顯示指定種子。但是在php中,rand會自己幫你默認調用一次srand,一般情況下不需要自己再顯示的調用。
需要注意的是,如果特殊情況下需要調用srand時,一定要配套調用。就是說srand對於rand,mt_srand對應srand,切不可混合使用,否則是無效的。
兩者都是用於排序,不同的是前者可以指定排序策略,類似我們C裡面的qsort和C++的sort。
在排序上兩者都是采用標准的快排來實現,對於有排序需求的,如非特殊情況調用php提供的這些方法就可以了,不用自己重新實現一遍,效率會低很多。原因見前文對於用戶函數和內置函數的分析比對。
這兩個都是用於url編碼, 字符串中除了 -_. 之外的所有非字母數字字符都將被替換成百分號(%)後跟兩位十六進制數。兩者唯一的區別在於對於空格,urlencode會編碼為+,而rawurlencode會編碼為%20。
一般情況下除了搜索引擎,我們的策略都是空格編碼為%20。因此采用後者的居多。注意的是encode和decode系列一定要配套使用。
這一系列的函數包括strcmp、strncmp、strcasecmp、strncasecmp,實現功能和C函數相同。但也有不同,由於php的字符串是允許\0出現,因此在判斷的時候底層使用的是memcmp系列而非strcmp,理論上來說更快。
另外由於php直接能獲取到字符串長度,因此會首先這方面的檢查,很多情況下效率就會高很多了。
這兩個函數功能相似又不完全相同,使用的時候一定需要注意他們的區別。
Is_int:判斷一個變量類型是否是整數型,php變量中專門有一個字段表征類型,因此直接判斷這個類型即可,是一個絕對O(1)的操作。
Is_numeric:判斷一個變量是否是整數或數字字符串,也就是說除了整數型變量會返回true之外,對於字符串變量,如果形如”1234”,”1e4”等也會被判為true。這個時候會遍歷字符串進行判斷。
通過對函數實現的原理分析和性能測試,我們總結出以下一些結論:
因此,對於php函數的使用,有如下一些建議: