很多人覺得機器學習高不可攀,認為這是一門只有少數專業學者才了解的神秘技術。
畢竟,你是在讓運行在二進制世界裡的機器得出它自己對現實世界的認識。你正在教它們如何思考。然而,本文幾乎不是你所認為的晦澀難懂、復雜而充滿數學公式的文章。正如所有幫助我們認識世界的基本常識一樣(例如:牛頓運動定律、工作需要去完成、供需關系等等),機器學習最佳的方法和概念也應該是簡潔明了的。可惜的是,絕大多數關於機器學習的文獻都充斥著復雜難懂的符號、艱澀晦暗的數學公式和不必要的廢話。正是這給機器學習簡單基礎的思想圍上了一堵厚厚的牆。
現在看一個實際的例子,我們需要在一篇文章的末尾增加一個“你可能喜歡”的推薦功能,那麼我們該如何實現呢?
為了實現這個想法,我們有一個簡單的解決方案:
def similar_posts(post) title_keywords = post.title.split(' ') Post.all.to_a.sort |post1, post2| post1_title_intersection = post1.body.split(' ') & title_keywords post2_title_intersection = post2.body.split(' ') & title_keywords post2_title_intersection.length <=> post1_title_intersection.length end[0..9]end采用這種方法去找出與博文“支持團隊如何提高產品質量”相似的文章,我們由此得到下列相關度前十的文章:
正如你所看到的,標桿文章是關於如何有效率地進行團隊支持,而這與客戶群組分析、討論設計的優點都沒有太大的關系,其實我們還可以采取更好的方法。
現在,我們嘗試用一種真正意義上的機器學習方法來解決這個問題。分兩步進行:
1.將文章用數學的形式表示
如果我們可以將文章以數學的形式展示,那麼可以根據文章之前的相似程度作圖,並識別出不同簇群:
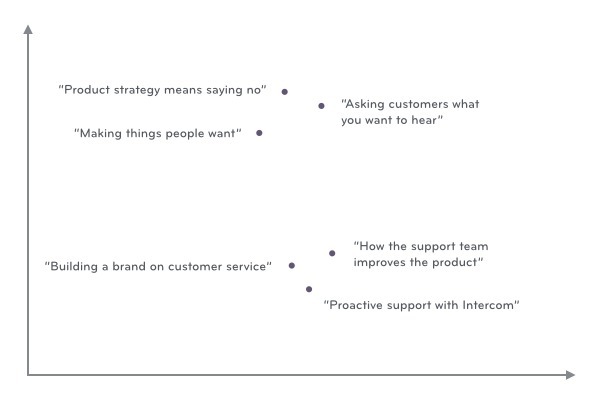
如上圖所示,將每篇文章映射成坐標系上的一個坐標點並不難,可以通過如下兩步實現:
Ruby代碼如下:
@posts = Post.all@words = @posts.map do |p| p.body.split(' ')end.flatten.uniq@vectors = @posts.map do |p| @words.map do |w| p.body.include?(w) ? 1 : 0 endend假設@words 的值為:
[“你好”,”內部”,”內部交流”,”讀者”,”博客”,”發布”]
如果某篇文章的內容是“你好 博客 發布 讀者”,那麼其對應的數組即為:
[1,0,0,1,1,1]
當然,我們現在沒法使用簡單的工具像二維坐標系一樣展示這個六維度的坐標點,但是這其中涉及的基本概念,例如兩點之間的距離都是互通的,可以通過二維推廣到更高維度(因此使用二維的例子來說明問題還是行得通的)。
2.用K均值(K-means)聚類算法對數據點進行聚類分析
現在我們得到了一系列文章的坐標,可以嘗試找出相似文章的群簇。這裡我們采用使用一個相當簡單聚類算法-K均值算法,概括起來有五個步驟:
我們接下來用圖的形式形象化地展示這些步驟。首先我們從一系列文章坐標中隨機選擇兩個點(K=2):

我們將每篇文章指派到離它最近的群簇中:

我們計算各個群簇中所有對象的坐標均值,作為該群簇新的中心。
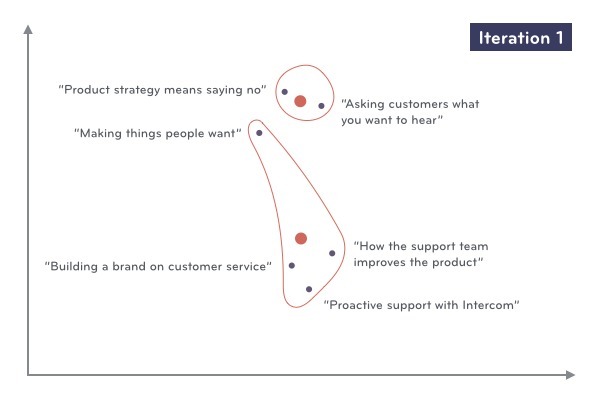
這樣我們就完成了第一次的數據迭代,現在我們將文章根據新的群簇中心重新指派到對應的群簇中去。
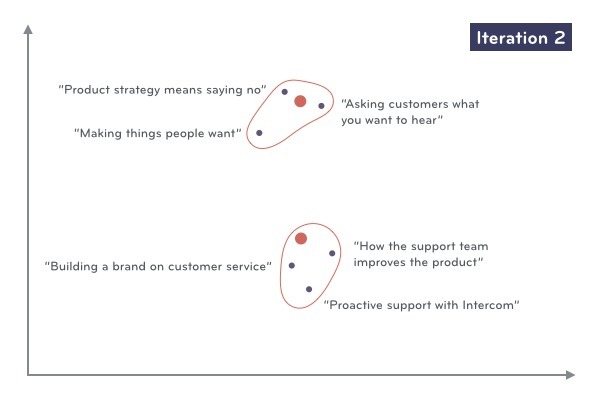
至此,我們找到了每篇文章對應的群簇!很明顯,即使繼續進行迭代群簇中心不會改變,每篇文章對應的群簇也不會改變了。
上述過程的Ruby代碼如下:
@cluster_centers = [rand_point(), rand_point()]15.times do @clusters = [[], []] @posts.each do |post| min_distance, min_point = nil, nil @cluster_centers.each.with_index do |center, i| if distance(center, post) < min_distance min_distance = distance(center, post) min_point = i end end @clusters[min_point] << post end @cluster_centers = @clusters.map do |post| average(posts) endend下面是由這個方法得到的與博文“支持團隊如何提高產品質量”相似性排在前十位的文章:
結果不言自明。
我們僅僅用了不到40行的代碼以及簡單的算法介紹就實現了這個想法,然而如果你看學術論文你永遠不會知道這本該有多簡單。下面是一篇介紹K均值算法論文的摘要(並不知道K均值算法是誰提出的,但這是首次提出“K均值”這個術語的文章)。

如果你喜歡以數學符號去表達思想,毫無疑問學術論文是很有用處的。然而,其實有更多優質的資源可以替換掉這些繁雜數學公式,它們更實際、更平易近人。
試一試
如何為你的項目管理應用推薦標簽?如何設計你的客戶支持工具?或者是社交網絡中用戶如何分組?這些都可以通過簡答的代碼、簡單的算法來實現,是練習的好機會!所以,如果你認為項目中面臨的問題可以通過機器學習來解決,那為什麼還要猶豫呢?
機器學習其實比你想象得更簡單!
原文鏈接: Intercom 翻譯: 伯樂在線 - zhibinzeng
譯文鏈接: http://blog.jobbole.com/53546/
======================================================
PPC微信平台開通啦!
微信搜索“PHPChina”,點擊關注按鈕,即可獲得PPC為您推送的最新最專業的業界信息,更有更多專題欄目為您獻上
【PPC挖掘】: 不定時為您獻上經典產品與產品人的故事。
【PPC外文】: 每日分享一篇外文翻譯文章
【PPCoder】: 每日集中回復關注用戶的提問