因為工作中我們經常會需要使用到Curl多線程來處理一些事情,不得己就深入了對Curl多線程研究了,下面小編來給各位同學介紹一下Curl多線程實例與原理吧。
相信許多人對php手冊中語焉不詳的curl_multi一族的函數頭疼不已,它們文檔少,給的例子 更是簡單的讓你無從借鑒,我也曾經找了許多網頁,都沒見一個完整的應用例子。
curl_multi_add_handle
curl_multi_close
curl_multi_exec
curl_multi_getcontent
curl_multi_info_read
curl_multi_init
curl_multi_remove_handle
curl_multi_select
一般來說,想到要用這些函數時,目的顯然應該是要同時請求多個url,而不是一個一個依次請求,否則不如自己循環去調curl_exec好了。
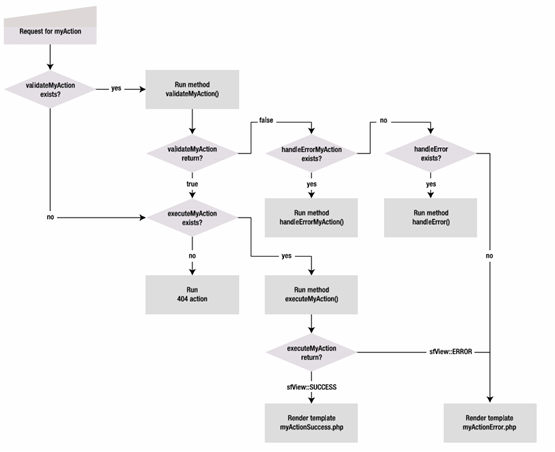
步驟總結如下:
第一步:調用curl_multi_init
第二步:循環調用curl_multi_add_handle
這一步需要注意的是,curl_multi_add_handle的第二個參數是由curl_init而來的子handle。
第三步:持續調用curl_multi_exec
第四步:根據需要循環調用curl_multi_getcontent獲取結果
第五步:調用curl_multi_remove_handle,並為每個字handle調用curl_close
第六步:調用curl_multi_close
這裡有PHP手冊上的例子:
<?php
// 創建一對cURL資源
$ch1 = curl_init();
$ch2 = curl_init();
// 設置URL和相應的選項
curl_setopt($ch1, CURLOPT_URL, "http://lxr.php.net/");
curl_setopt($ch1, CURLOPT_HEADER, 0);
curl_setopt($ch2, CURLOPT_URL, "http://www.php.net/");
curl_setopt($ch2, CURLOPT_HEADER, 0);
// 創建批處理cURL句柄
$mh = curl_multi_init();
// 增加2個句柄
curl_multi_add_handle($mh,$ch1);
curl_multi_add_handle($mh,$ch2);
$active = null;
// 執行批處理句柄
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
while ($active && $mrc == CURLM_OK) {
if (curl_multi_select($mh) != -1) {
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
}
}
// 關閉全部句柄
curl_multi_remove_handle($mh, $ch1);
curl_multi_remove_handle($mh, $ch2);
curl_multi_close($mh);
?>
整個使用過程差不多就是這樣,但是,這個簡單代碼有個致命弱點,就是在do循環的那段,在整個url請求期間是個死循環,它會輕易導致CPU占用100%。
現在我們來改進它,這裡要用到一個幾乎沒有任何文檔的函數curl_multi_select了,雖然C的curl庫對select有說明,但是,php裡的接口和用法確與C中有不同。
把上面do的那段改成下面這樣:
代碼如下 復制代碼
do {
$mrc = curl_multi_exec($mh,$active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
while ($active and $mrc == CURLM_OK) {
if (curl_multi_select($mh) != -1) {
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
}
}
因為$active要等全部url數據接受完畢才變成false,所以這裡用到了curl_multi_exec的返回值判斷是否還有數據,當有數據的時候就不停調用curl_multi_exec,暫時沒有數據就進入select階段,新數據一來就可以被喚醒繼續執行。這裡的好處就是CPU的無謂消耗沒有了。
另外:還有一些細節的地方可能有時候要遇到:
控制每一個請求的超時時間,在curl_multi_add_handle之前通過curl_setopt去做:
curl_setopt($ch, CURLOPT_TIMEOUT, $timeout);
判斷是否超時了或者其他錯誤,在curl_multi_getcontent之前用:curl_error($conn[$i]);
本類的特點:
運行非常穩定。
設置一個並發就會始終以這個並發數進行工作,即使通過回調函數添加任務也不影響。
CPU占用極低,絕大部分CPU消耗在用戶的回調函數上。
內存利用率高,任務數量較多(15W個任務占用內存會超過256M)可以使用回調函數添加任務,個數自定。
能夠最大限度的占用帶寬。
鏈式任務,比如一個任務需要從多個不同的地址采集數據,可以通過回調一氣呵成。
能夠對CURL錯誤進行多次嘗試,次數自定(大並發一開始容易產生CURL錯誤,網絡狀況或對方服務器穩定性也有可能產生CURL錯誤)。
回調函數相當靈活,可以多種類型任務同時進行(比如下載文件,抓取網頁,分析404可以在一個PHP進程中同時進行)。
可以非常容易的定制任務類型,比如檢查404,獲取redirect的最後url等。
可以設置緩存,挑戰產品節操。
不足:
不能充分利用多核CPU(可以開多個進程解決,需要自己處理任務分割等邏輯)。
最大並發500(或512?),經過測試是CURL 內部限制,超過最大並發會導致總是返回失敗。
目前沒有斷點續傳功能。
目前任務是原子性的,不能對一個大文件分為幾部分分別開線程下載。