我們經常會在發現頁面中無故多了一些空白行了,但在編輯器中又看到到,這個我們知道是由BOM(UTF-8)導致的,下面小編來給大家分享幾種關於BOM(UTF-8)檢測與刪除方法。
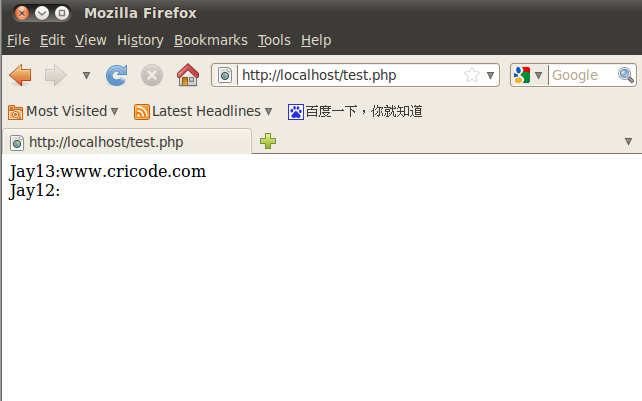
下圖是出現前面說的情況後用firebug看到的HTML代碼。
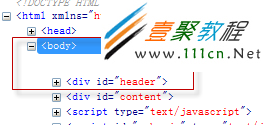
圖1
裡面莫名其妙多出了一個空白行,而我們看源代碼裡面卻沒有。
我最常用的辦法,利用php替換
BOM: 萬國碼檔案簽名 BOM (Byte Order Mark, U+FEFF)
BOM 的內容可以表示 UNICODE 是哪種編碼, 但是在接收到的檔案, 要拆解後寫入 DB, 看到 BOM 就覺得有點 ooxx.
在 utf8_encode 看到兩段程式可以來測試 寫入/移除 BOM.
將寫入的檔案內容前加 BOM
代碼如下 復制代碼<?php
function writeUTF8File($filename,$content)
{
$f = fopen($filename, 'w');
fwrite($f, pack("CCC", 0xef,0xbb,0xbf));
fwrite($f,$content);
fclose($f);
}
?>
移除 BOM function
代碼如下 復制代碼<?php
function removeBOM($str = '')
{
if (substr($str, 0,3) == pack("CCC",0xef,0xbb,0xbf)) {
$str = substr($str, 3);
}
return $str;
}
?>
由此上述 BOM = pack("CCC",0xef,0xbb,0xbf), 所以移除 BOM 的寫法可用上面的 removeBOM function 或 下述其一:
■str_replace("锘�", '', $bom_content);
■preg_replace("/^锘�/", '', $bom_content);
另外看到 判斷此字串是不是 UTF-8 的 function:
function isUTF8($string)
{
return (utf8_encode(utf8_decode($string)) == $string);
}
linux系統中使用shell來解決
在詳細討論UTF-8編碼中BOM的檢測與刪除問題前,不妨先通過一個例子熱熱身:
代碼如下 復制代碼 shell> curl -s http://www.bKjia.c0m/ | head -1 | sed -n l如上所示,前三個字節分別是357、273、277,這就是八進制的BOM。
代碼如下 復制代碼 shell> curl -s http://www.111cn.Net/ | head -1 | hexdump -C如上所示,前三個字節分別是EF、BB、BF,這就是十六進制的BOM。 注:用到了第三方網站的頁面,不能保證例子始終可用。 實際做項目開發時,可能會面對成百上千個文本文件,如果有幾個文件混入了BOM,那麼很難察覺,如果沒有帶BOM的UTF-8文本文件,可以用vi杜撰幾個,相關命令如下:
設置UTF-8編碼:
代碼如下 復制代碼 :set fileencoding=utf-8添加BOM:
代碼如下 復制代碼 :set bomb刪除BOM:
代碼如下 復制代碼 :set nobomb查詢BOM:
代碼如下 復制代碼 :set bomb?如何檢測UTF-8編碼中的BOM呢?
代碼如下 復制代碼shell> grep -r -I -l $'^锘�' /path如何刪除UTF-8編碼中的BOM呢?
shell> grep -r -I -l $'^锘�' /path | xargs sed -i 's/^锘�//;q'
推薦:如果你使用SVN的話,可以在pre-commit鉤子裡加上相關代碼用以杜絕BOM。
代碼如下 復制代碼#!/bin/bash
REPOS="$1"
TXN="$2"
SVNLOOK=/usr/bin/svnlook
for FILE in $($SVNLOOK changed -t "$TXN" "$REPOS" | awk '/^[AU]/ {print $NF}'); do
if $SVNLOOK cat -t "$TXN" "$REPOS" "$FILE" | grep -q $'^锘�'; then
echo "Byte Order Mark be found in $FILE" 1>&2
exit 1
fi
done
本文用到了很多shell命令
方法三,利用ultraedit編輯器直接修改文檔
把出現空行的文檔另存沒沒有BOM的格式就行了。
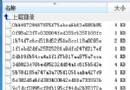
下圖是ultraedit保存文檔時的編碼格式:

圖2
選擇裡面的UTF8-無BOM,一切解決