這兩天項目開發中,需要實現一些比較實用的功能,用了兩個使用的sql,總結一下,怕下次忘記了。
1. 檢索數據庫中跟提交的內容相匹配的內容
比如:提交的數據是“游泳”,那麼數據庫中有“我喜歡游泳”字樣的就算是匹配,但是這樣一來,還是不夠,比如我提交的是“周末去游泳”,數據庫中有“游泳”的內容,其實意思類似,但是卻使用like找不到的,於是想到下面的sql,已經封裝成函數了:
function getRelationTags($tagTitle,$cols="*")
{
$titleFeildStrLen = 24; //3*8 四個漢字或者24個字符.
if ("" == $tagTitle) return false;
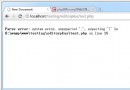
$sql = "select $cols from ".$TableName." where title != '' and (LOCATE(title,'$tagTitle') or ((issystem = 1 or LENGTH(title) <= $titleFeildStrLen) and title like '%".$tagTitle."%' )) order by LENGTH(title) ";
$data =& $db->getAll($sql);
if(DB::isError($data)){
return $this->returnValue($data->getMessage());
}else{
return $data;
}
}
看sql:
select $cols from ".$TableName." where title != '' and (LOCATE(title,'$tagTitle') or ((issystem = 1 or LENGTH(title) <= $titleFeildStrLen) and title like '%".$tagTitle."%' )) order by LENGTH(title)
其實就是兩次匹配,一次是正向匹配,就是把提交的標簽跟數據庫中標簽進行匹配,第二次是把數據庫中的標簽跟提交的標簽進行匹配。
要害在LOCATE()函數,同時也限制了長度,因為mysql中的編碼是:
set names 'utf8'
就是是utf8的,那麼一個漢字要占用3個字節,字符只占用1個字節,所以上面的:
$titleFeildStrLen = 24;
就是8個漢字和24個字符范圍那的標簽進行匹配。
2. 同類排序
數據庫中比如是這樣的內容:
北京 1023 1
天津 2301 1
上海 3450 1
天津 4520 1
北京 3902 1
那麼我要提取所有的城市數據,並且把每種城市數據的總數跟別的城市總數進行比較後排序。
函數代碼如下:
function getMostCity($num)
{
$sql = "select count(id) as num,city from ".$TableName." where city != '' group by city order by num desc limit 0,$num;";
$data =& $db->getAll($sql);
if($db->isError($data))
return false;
else
return $data;
}
我們關注一下上面的sql語句:
select count(id) as num,city from ".$TableName." where city != '' group by city order by num desc limit 0,$num
核心就是 group by city 把類似城市集中起來後按照多到少排序。