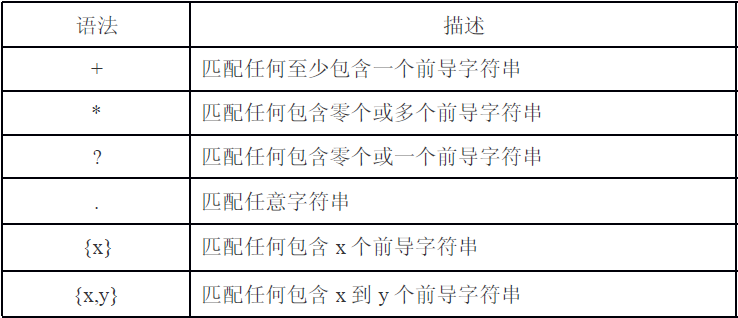
懶得翻譯了,大意:
在有合適的索引的時候,Top n和set rowcount n是一樣快的。但是對於一個無序堆來說,top n更快。
原理自己看英文去。
Q. Is using the TOP N clause faster than using SET ROWCOUNT N to return a specific number of rows from a query?
A. With proper indexes, the TOP N clause and SET ROWCOUNT N statement are equally fast, but with unsorted input from a heap, TOP N is faster. With unsorted input, the TOP N operator uses a small internal sorted temporary table in which it replaces only the last row. If the input is nearly sorted, the TOP N engine must delete or insert the last row only a few times. Nearly sorted means you're dealing with a heap with ordered inserts for the initial population and without many updates, deletes, forwarding pointers, and so on afterward.
A nearly sorted heap is more efficient to sort than sorting a huge table. In a test that used TOP N to sort a table with the same number of rows but with unordered inserts, TOP N was not as efficient anymore. Usually, the I/O time is the same both with an index and without; however, without an index SQL Server must do a complete table scan. Processor time and elapsed time show the efficiency of the nearly sorted heap. The I/O time is the same because SQL Server must read all the rows either way.