PHP中的正則表達式函數
在PHP中有兩套正則表達式函數庫。一套是由PCRE(Perl Compatible Regular Expression)庫提供的。PCRE庫使用和Perl相同的語法規則實現了正則表達式的模式匹配,其使用以“preg_”為前綴命名的函數。另一套是由POSIX(Portable Operation System interface)擴展庫提供的。POSIX擴展的正則表達式由POSIX 1003.2定義,一般使用以“ereg_”為前綴命名的函數。
兩套函數庫的功能相似,執行效率稍有不同。一般而言,實現相同的功能,使用PCRE庫的效率略占優勢。下面詳細介紹其使用方法。
正則表達式的匹配
1.preg_match()
函數原型:int preg_match (string $pattern, string $content [, array $matches])
preg_match ()函數在$content字符串中搜索與$pattern給出的正則表達式相匹配的內容。如果提供了$matches,則將匹配結果放入其中。$matches[0]將包含與整個模式匹配的文本,$matches[1]將包含第一個捕獲的與括號中的模式單元所匹配的內容,以此類推。該函數只作一次匹配,最終返回0或1的匹配結果數。代碼6.1給出preg_match()函數的一段代碼示例。
代碼6.1 日期時間的匹配
<?php
//需要匹配的字符串。date函數返回當前時間
$content = "Current date and time is ".date("Y-m-d h:i a").", we are learning PHP together.";
//使用通常的方法匹配時間
if (preg_match ("/\d{4}-\d{2}-\d{2} \d{2}:\d{2} [ap]m/", $content, $m))
{
echo "匹配的時間是:" .$m[0]. "\n";
}
//由於時間的模式明顯,也可以簡單的匹配
if (preg_match ("/([\d-]{10}) ([\d:]{5} [ap]m)/", $content, $m))
{
echo "當前日期是:" .$m[1]. "\n";
echo "當前時間是:" .$m[2]. "\n";
}
?>
這是一個簡單動態文本串匹配實例。假設當前系統時間是“2006年8月17日13點25分”,將輸出如下的內容。
匹配的時間是:2006-08-17 01:25 pm
當前日期是:2006-08-17
當前時間是:01:25 pm
2.ereg()和eregi()
ereg()是POSIX擴展庫中正則表達式的匹配函數。eregi()是ereg()函數的忽略大小寫的版本。二者與preg_match的功能類似,但函數返回的是一個布爾值,表明匹配成功與否。需要說明的是,POSIX擴展庫函數的第一個參數接受的是正則表達式字符串,即不需要使用分界符。例如,代碼6.2是一個關於文件名安全檢驗的方法。
代碼6.2 文件名的安全檢驗
<?php
$username = $_SERVER['REMOTE_USER'];
$filename = $_GET['file'];
//對文件名進行過濾,以保證系統安全
if (!ereg('^[^./][^/]*$', $userfile))
{
die('這不是一個非法的文件名!');
}
//對用戶名進行過濾
if (!ereg('^[^./][^/]*$', $username))
{
die('這不是一個無效的用戶名');
}
//通過安全過濾,拼合文件路徑
$thefile = "/home/$username/$filename";
?>
通常情況下,使用與Perl兼容的正則表達式匹配函數perg_match(),將比使用ereg()或eregi()的速度更快。如果只是查找一個字符串中是否包含某個子字符串,建議使用strstr()或strpos()函數。
3.preg_grep()
函數原型:array preg_grep (string $pattern, array $input)
preg_grep()函數返回一個數組,其中包括了$input數組中與給定的$pattern模式相匹配的單元。對於輸入數組$input中的每個元素,preg_grep()也只進行一次匹配。代碼6.3給出的示例簡單地說明了preg_grep()函數的使用。
代碼6.3 數組查詢匹配
<?php
$subjects = array(
"Mechanical Engineering", "Medicine",
"Social Science", "Agriculture",
"Commercial Science", "Politics"
);
//匹配所有僅由有一個單詞組成的科目名
$alonewords = preg_grep("/^[a-z]*$/i", $subjects);
?>
6.3.2 進行全局正則表達式匹配
1.preg_match_all()
與preg_match()函數類似。如果使用了第三個參數,將把所有可能的匹配結果放入。本函數返回整個模式匹配的次數(可能為0),如果出錯返回False。下面是一個將文本中的URL鏈接地址轉換為HTML代碼的示例。代碼6.4是preg_match_all()函數的使用范例。
代碼6.4 將文本中的鏈接地址轉成HTML
<?php
//功能:將文本中的鏈接地址轉成HTML
//輸入:字符串
//輸出:字符串
function url2html($text)
{
//匹配一個URL,直到出現空白為止
preg_match_all("/http:\/\/?[^\s]+/i", $text, $links);
//設置頁面顯示URL地址的長度
$max_size = 40;
foreach($links[0] as $link_url)
{
//計算URL的長度。如果超過$max_size的設置,則縮短。
$len = strlen($link_url);
if($len > $max_size)
{
$link_text = substr($link_url, 0, $max_size)."...";
} else {
$link_text = $link_url;
}
//生成HTML文字
$text = str_replace($link_url,"<a href='$link_url'>$link_text</a>",$text);
}
return $text;
}
//運行實例
$str = “這是一個包含多個URL鏈接地址的多行文字。歡迎訪問http://www.taoboor.com”;
print url2html($str);
/*輸出結果
這是一個包含多個URL鏈接地址的多行文字。歡迎訪問<a href='http://www.taoboor.com'>
http://www.taoboor.com</a>
*/
?>
2.多行匹配
僅僅使用POSIX下的正則表式函數,很難進行復雜的匹配操作。例如,對整個文件(尤其是多行文本)進行匹配查找。使用ereg()對此進行操作的一個方法是分行處理。代碼6.5的示例演示了ereg()如何將INI文件的參數賦值到數組之中。
代碼6.5 文件內容的多行匹配
<?php
$rows = file('php.ini'); //將php.ini文件讀到數組中
//循環遍歷
foreach($rows as $line)
{
If(trim($line))
{
//將匹配成功的參數寫入數組中
if(eregi("^([a-z0-9_.]*) *=(.*)", $line, $matches))
{
$options[$matches[1]] = trim($matches[2]);
}
unset($matches);
}
}
//輸出參數結果
print_r($options);
?>
提示
這裡只是為了方便說明問題。解析一個*.ini文件,最佳方法是使用函數parse_ini_file()。該函數直接將*.ini文件解析到一個大數組中。
6.3.3 正則表達式的替換
1.ereg_replace()和eregi_replace()
函數原型:string ereg_replace (string $pattern, string $replacement, string $string)
string eregi_replace (string $pattern, string $replacement, string $string)
ereg_replace()在$string中搜索模式字符串$pattern,並將所匹配結果替換為$replacement。當$pattern中包含模式單元(或子模式)時,$replacement中形如“\1”或“$1”的位置將依次被這些子模式所匹配的內容替換。而“\0”或“$0”是指整個的匹配字符串的內容。需要注意的是,在雙引號中反斜線作為轉義符使用,所以必須使用“\\0”,“\\1”的形式。
eregi_replace()和ereg_replace()的功能一致,只是前者忽略大小寫。代碼6.6是本函數的應用實例,這段代碼演示了如何對程序源代碼做簡單的清理工作。
代碼6.6 源代碼的清理
<?php
$lines = file('source.php'); //將文件讀入數組中
for($i=0; $i<count($lines); $i++)
{
//將行末以“\\”或“#”開頭的注釋去掉
$lines[$i] = eregi_replace("(\/\/|#).*$", "", $lines[$i]);
//將行末的空白消除
$lines[$i] = eregi_replace("[ \n\r\t\v\f]*$", "\r\n", $lines[$i]);
}
//整理後輸出到頁面
echo htmlspecialchars(join("",$lines));
?>
2.preg_replace()
函數原型:mixed preg_replace (mixed $pattern, mixed $replacement, mixed $subject [, int $limit])
preg_replace較ereg_replace的功能更加強大。其前三個參數均可以使用數組;第四個參數$limit可以設置替換的次數,默認為全部替換。代碼6.7是一個數組替換的應用實例。
代碼6.7 數組替換
<?php
//字符串
$string = "Name: {Name}<br>\nEmail: {Email}<br>\nAddress: {Address}<br>\n";
//模式
$patterns =array(
"/{Address}/",
"/{Name}/",
"/{Email}/"
);
//替換字串
$replacements = array (
"No.5, Wilson St., New York, U.S.A",
"Thomas Ching",
"[email protected]",
);
//輸出模式替換結果
print preg_replace($patterns, $replacements, $string);
?>
輸出結果如下。
Name: Thomas Ching",
Email: [email protected]
Address: No.5, Wilson St., New York, U.S.A
在preg_replace的正則表達式中可以使用模式修正符“e”。其作用是將匹配結果用作表達式,並且可以進行重新運算。例如:
<?php
$html_body = “<HTML><Body><H1>TEST</H1>My Picture<Img src=”my.gif”></Body></HTML>”;
//輸出結果中HTML標簽將全部為小寫字母
echo preg_replace (
"/(<\/?)(\w+)([^>]*>)/e",
"'\\1'.strtolower('\\2').'\\3'", //此處的模式變量\\2將被strtolower轉換為小寫字符
$html_body);
?>
提示
preg_replace函數使用了Perl兼容正則表達式語法,通常是比ereg_replace更快的替代方案。如果僅對字符串做簡單的替換,可以使用str_replace函數。
6.3.4 正則表達式的拆分
1.split()和spliti()
函數原型:array split (string $pattern, string $string [, int $limit])
本函數返回一個字符串數組,每個單元為$string經正則表達式$pattern作為邊界分割出的子串。如果設定了$limit,則返回的數組最多包含$limit個單元。而其中最後一個單元包含了$string中剩余的所有部分。spliti是split的忽略大小版本。代碼6.8是一個經常用到關於日期的示例。
代碼6.8 日期的拆分
<?php
$date = "08/30/2006";
//分隔符可以是斜線,點,或橫線
list($month, $day, $year) = split ('[/.-]', $date);
//輸出為另一種時間格式
echo "Month: $month; Day: $day; Year: $year<br />\n";
?>
2.preg_split()
本函數與split函數功能一致。代碼6.9是一個查找文章中單詞數量的示例。
代碼6.9 查找文章中單詞數量
<?php
$seek = array();
$text = "I have a dream that one day I can make it. So just do it, nothing is impossible!";
//將字符串按空白,標點符號拆分(每個標點後也可能跟有空格)
$words = preg_split("/[.,;!\s']\s*/", $text);
foreach($words as $val)
{
$seek[strtolower($val)] ++;
}
echo "共有大約" .count($words). "個單詞。";
echo "其中共有" .$seek['i']. "個單詞“I”。";
?>
提示
preg_split()函數使用了Perl兼容正則表達式語法,通常是比split()更快的替代方案。使用正則表達式的方法分割字符串,可以使用更廣泛的分隔字符。例如,上面對日期格式和單詞處理的分析。如果僅用某個特定的字符進行分割,建議使用explode()函數,它不調用正則表達式引擎,因此速度是最快的。
下面是一些講解和例子,僅供大家參考和修改使用:
2. "^\d+$" //非負整數(正整數 + 0)
3. "^[0-9]*[1-9][0-9]*$" //正整數
4. "^((-\d+)|(0+))$" //非正整數(負整數 + 0)
5. "^-[0-9]*[1-9][0-9]*$" //負整數
6. "^-?\d+$" //整數
7. "^\d+(\.\d+)?$" //非負浮點數(正浮點數 + 0)
8. "^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$" //正浮點數
9. "^((-\d+(\.\d+)?)|(0+(\.0+)?))$" //非正浮點數(負浮點數 + 0)
10. "^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$" //負浮點數
11. "^(-?\d+)(\.\d+)?$" //浮點數
12. "^[A-Za-z]+$" //由26個英文字母組成的字符串
13. "^[A-Z]+$" //由26個英文字母的大寫組成的字符串
14. "^[a-z]+$" //由26個英文字母的小寫組成的字符串
15. "^[A-Za-z0-9]+$" //由數字和26個英文字母組成的字符串
16. "^\w+$" //由數字、26個英文字母或者下劃線組成的字符串
17. "^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$" //email地址
18. "^[a-zA-z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$" //url
19. /^(d{2}|d{4})-((0([1-9]{1}))|(1[1|2]))-(([0-2]([1-9]{1}))|(3[0|1]))$/ // 年-月-日
20. /^((0([1-9]{1}))|(1[1|2]))/(([0-2]([1-9]{1}))|(3[0|1]))/(d{2}|d{4})$/ // 月/日/年
21. "^([w-.]+)@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.)|(([w-]+.)+))([a-zA-Z]{2,4}|[0-9]{1,3})(]?)$" //Emil
22. /^((\+?[0-9]{2,4}\-[0-9]{3,4}\-)|([0-9]{3,4}\-))?([0-9]{7,8})(\-[0-9]+)?$/ //電話號碼
23. "^(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5])$" //IP地址
24.
25. 匹配中文字符的正則表達式: [\u4e00-\u9fa5]
26. 匹配雙字節字符(包括漢字在內):[^\x00-\xff]
27. 匹配空行的正則表達式:\n[\s| ]*\r
28. 匹配HTML標記的正則表達式:/<(.*)>.*<\/\1>|<(.*) \/>/
29. 匹配首尾空格的正則表達式:(^\s*)|(\s*$)
30. 匹配Email地址的正則表達式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
31. 匹配網址URL的正則表達式:^[a-zA-z]+://(\\w+(-\\w+)*)(\\.(\\w+(-\\w+)*))*(\\?\\S*)?$
32. 匹配帳號是否合法(字母開頭,允許5-16字節,允許字母數字下劃線):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
33. 匹配國內電話號碼:(\d{3}-|\d{4}-)?(\d{8}|\d{7})?
34. 匹配騰訊QQ號:^[1-9]*[1-9][0-9]*$
35.
36.
37. 元字符及其在正則表達式上下文中的行為:
38.
39. \ 將下一個字符標記為一個特殊字符、或一個原義字符、或一個後向引用、或一個八進制轉義符。
40.
41. ^ 匹配輸入字符串的開始位置。如果設置了 RegExp 對象的Multiline 屬性,^ 也匹配 ’\n’ 或 ’\r’ 之後的位置。
42.
43. $ 匹配輸入字符串的結束位置。如果設置了 RegExp 對象的Multiline 屬性,$ 也匹配 ’\n’ 或 ’\r’ 之前的位置。
44.
45. * 匹配前面的子表達式零次或多次。
46.
47. + 匹配前面的子表達式一次或多次。+ 等價於 {1,}。
48.
49. ? 匹配前面的子表達式零次或一次。? 等價於 {0,1}。
50.
51. {n} n 是一個非負整數,匹配確定的n 次。
52.
53. {n,} n 是一個非負整數,至少匹配n 次。
54.
55. {n,m} m 和 n 均為非負整數,其中n <= m。最少匹配 n 次且最多匹配 m 次。在逗號和兩個數之間不能有空格。
56.
57. ? 當該字符緊跟在任何一個其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 後面時,匹配模式是非貪婪的。非貪婪模式盡可能少的匹配所搜索的字符串,而默認的貪婪模式則盡可能多的匹配所搜索的字符串。
58.
59. . 匹配除 "\n" 之外的任何單個字符。要匹配包括 ’\n’ 在內的任何字符,請使用象 ’[.\n]’ 的模式。
60. (pattern) 匹配pattern 並獲取這一匹配。
61.
62. (?:pattern) 匹配pattern 但不獲取匹配結果,也就是說這是一個非獲取匹配,不進行存儲供以後使用。
63.
64. (?=pattern) 正向預查,在任何匹配 pattern 的字符串開始處匹配查找字符串。這是一個非獲取匹配,也就是說,該匹配不需要獲取供以後使用。
65.
66. (?!pattern) 負向預查,與(?=pattern)作用相反
67.
68. x|y 匹配 x 或 y。
69.
70. [xyz] 字符集合。
71.
72. [^xyz] 負值字符集合。
73.
74. [a-z] 字符范圍,匹配指定范圍內的任意字符。
75.
76. [^a-z] 負值字符范圍,匹配任何不在指定范圍內的任意字符。
77.
78. \b 匹配一個單詞邊界,也就是指單詞和空格間的位置。
79.
80. \B 匹配非單詞邊界。
81.
82. \cx 匹配由x指明的控制字符。
83.
84. \d 匹配一個數字字符。等價於 [0-9]。
85.
86. \D 匹配一個非數字字符。等價於 [^0-9]。
87.
88. \f 匹配一個換頁符。等價於 \x0c 和 \cL。
89.
90. \n 匹配一個換行符。等價於 \x0a 和 \cJ。
91.
92. \r 匹配一個回車符。等價於 \x0d 和 \cM。
93.
94. \s 匹配任何空白字符,包括空格、制表符、換頁符等等。等價於[ \f\n\r\t\v]。
95.
96. \S 匹配任何非空白字符。等價於 [^ \f\n\r\t\v]。
97.
98. \t 匹配一個制表符。等價於 \x09 和 \cI。
99.
100. \v 匹配一個垂直制表符。等價於 \x0b 和 \cK。
101.
102. \w 匹配包括下劃線的任何單詞字符。等價於’[A-Za-z0-9_]’。
103.
104. \W 匹配任何非單詞字符。等價於 ’[^A-Za-z0-9_]’。
105.
106. \xn 匹配 n,其中 n 為十六進制轉義值。十六進制轉義值必須為確定的兩個數字長。
107.
108. \num 匹配 num,其中num是一個正整數。對所獲取的匹配的引用。
109.
110. \n 標識一個八進制轉義值或一個後向引用。如果 \n 之前至少 n 個獲取的子表達式,則 n 為後向引用。否則,如果 n 為八進制數字 (0-7),則 n 為一個八進制轉義值。
111.
112. \nm 標識一個八進制轉義值或一個後向引用。如果 \nm 之前至少有is preceded by at least nm 個獲取得子表達式,則 nm 為後向引用。如果 \nm 之前至少有 n 個獲取,則 n 為一個後跟文字 m 的後向引用。如果前面的條件都不滿足,若 n 和 m 均為八進制數字 (0-7),則 \nm 將匹配八進制轉義值 nm。
113.
114. \nml 如果 n 為八進制數字 (0-3),且 m 和 l 均為八進制數字 (0-7),則匹配八進制轉義值 nml。
115.
116. \un 匹配 n,其中 n 是一個用四個十六進制數字表示的Unicode字符。
117.
118. 匹配中文字符的正則表達式: [u4e00-u9fa5]
119.
120. 匹配雙字節字符(包括漢字在內):[^x00-xff]
121.
122. 匹配空行的正則表達式:n[s| ]*r
123.
124. 匹配HTML標記的正則表達式:/<(.*)>.*</1>|<(.*) />/
125.
126. 匹配首尾空格的正則表達式:(^s*)|(s*$)
127.
128. 匹配Email地址的正則表達式:w+([-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*
129.
130. 匹配網址URL的正則表達式:http://([w-]+.)+[w-]+(/[w- ./?%&=]*)?
131.
132. 利用正則表達式限制網頁表單裡的文本框輸入內容:
133.
134. 用正則表達式限制只能輸入中文:onkeyup="value=value.replace(/[^u4E00-u9FA5]/g,'')" onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^u4E00-u9FA5]/g,''))"
135.
136. 用正則表達式限制只能輸入全角字符: onkeyup="value=value.replace(/[^uFF00-uFFFF]/g,'')" onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^uFF00-uFFFF]/g,''))"
137.
138. 用正則表達式限制只能輸入數字:onkeyup="value=value.replace(/[^d]/g,'') "onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^d]/g,''))"
139.
140. 用正則表達式限制只能輸入數字和英文:onkeyup="value=value.replace(/[W]/g,'') "onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^d]/g,''))"
141.
142. =========常用正則式
143.
144.
145.
146. 匹配中文字符的正則表達式: [\u4e00-\u9fa5]
147.
148. 匹配雙字節字符(包括漢字在內):[^\x00-\xff]
149.
150. 匹配空行的正則表達式:\n[\s| ]*\r
151.
152. 匹配HTML標記的正則表達式:/<(.*)>.*<\/\1>|<(.*) \/>/
153.
154. 匹配首尾空格的正則表達式:(^\s*)|(\s*$)
155.
156. 匹配IP地址的正則表達式:/(\d+)\.(\d+)\.(\d+)\.(\d+)/g //
157.
158. 匹配Email地址的正則表達式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
159.
160. 匹配網址URL的正則表達式:http://(/[\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?
161.
162. sql語句:^(select|drop|delete|create|update|insert).*$
163.
164. 1、非負整數:^\d+$
165.
166. 2、正整數:^[0-9]*[1-9][0-9]*$
167.
168. 3、非正整數:^((-\d+)|(0+))$
169.
170. 4、負整數:^-[0-9]*[1-9][0-9]*$
171.
172. 5、整數:^-?\d+$
173.
174. 6、非負浮點數:^\d+(\.\d+)?$
175.
176. 7、正浮點數:^((0-9)+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
177.
178. 8、非正浮點數:^((-\d+\.\d+)?)|(0+(\.0+)?))$
179.
180. 9、負浮點數:^(-((正浮點數正則式)))$
181.
182. 10、英文字符串:^[A-Za-z]+$
183.
184. 11、英文大寫串:^[A-Z]+$
185.
186. 12、英文小寫串:^[a-z]+$
187.
188. 13、英文字符數字串:^[A-Za-z0-9]+$
189.
190. 14、英數字加下劃線串:^\w+$
191.
192. 15、E-mail地址:^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$
193.
194. 16、URL:^[a-zA-Z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\s*)?$
195. 或:^http:\/\/[A-Za-z0-9]+\.[A-Za-z0-9]+[\/=\?%\-&_~`@[\]\':+!]*([^<>\"\"])*$
196.
197. 17、郵政編碼:^[1-9]\d{5}$
198.
199. 18、中文:^[\u0391-\uFFE5]+$
200.
201. 19、電話號碼:^((\(\d{2,3}\))|(\d{3}\-))?(\(0\d{2,3}\)|0\d{2,3}-)?[1-9]\d{6,7}(\-\d{1,4})?$
202.
203. 20、手機號碼:^((\(\d{2,3}\))|(\d{3}\-))?13\d{9}$
204.
205. 21、雙字節字符(包括漢字在內):^\x00-\xff
206.
207. 22、匹配首尾空格:(^\s*)|(\s*$)(像vbscript那樣的trim函數)
208.
209. 23、匹配HTML標記:<(.*)>.*<\/\1>|<(.*) \/>
210.
211. 24、匹配空行:\n[\s| ]*\r
212.
213. 25、提取信息中的網絡鏈接:(h|H)(r|R)(e|E)(f|F) *= *('|")?(\w|\\|\/|\.)+('|"| *|>)?
214.
215. 26、提取信息中的郵件地址:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
216.
217. 27、提取信息中的圖片鏈接:(s|S)(r|R)(c|C) *= *('|")?(\w|\\|\/|\.)+('|"| *|>)?
218.
219. 28、提取信息中的IP地址:(\d+)\.(\d+)\.(\d+)\.(\d+)
220.
221. 29、提取信息中的中國手機號碼:(86)*0*13\d{9}
222.
223. 30、提取信息中的中國固定電話號碼:(\(\d{3,4}\)|\d{3,4}-|\s)?\d{8}
224.
225. 31、提取信息中的中國電話號碼(包括移動和固定電話):(\(\d{3,4}\)|\d{3,4}-|\s)?\d{7,14}
226.
227. 32、提取信息中的中國郵政編碼:[1-9]{1}(\d+){5}
228.
229. 33、提取信息中的浮點數(即小數):(-?\d*)\.?\d+
230.
231. 34、提取信息中的任何數字 :(-?\d*)(\.\d+)?
232.
233. 35、IP:(\d+)\.(\d+)\.(\d+)\.(\d+)
234.
235. 36、電話區號:/^0\d{2,3}$/
236.
237. 37、騰訊QQ號:^[1-9]*[1-9][0-9]*$
238.
239. 38、帳號(字母開頭,允許5-16字節,允許字母數字下劃線):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
240.
241. 39、中文、英文、數字及下劃線:^[\u4e00-\u9fa5_a-zA-Z0-9]+$
js正則函數match、exec、test、search、replace、split使用介紹集合
js: pattern = /\-+.*/
pattern.test(’你的字符‘) 返回bool值
pattern.exec('你的字符') 返回數組
str.replace(param1,param2) 注意這裡的param1可以是直接的字符也可以是正則表達式, param2是你要替換成的字符 一定要注意是有返回值的你的最終替換結 果是返回值
以下為一些方法的詳細介紹:
match 方法
使用正則表達式模式對字符串執行查找,並將包含查找的結果作為數組返回。
stringObj.match(rgExp)
參數
stringObj
必選項。對其進行查找的 String 對象或字符串文字。
rgExp
必選項。為包含正則表達式模式和可用標志的正則表達式對象。也可以是包含正則表達式模式和可用標志的變量名或字符串文字。
其余說明與exec一樣,不同的是如果match的表達式匹配了全局標記g將出現所有匹配項,而不用循環,但所有匹配中不會包含子匹配項。
例子1:
function MatchDemo(){ var r, re; // 聲明變量。 var s = "The rain in Spain falls mainly in the plain"; re = /(a)in/ig; // 創建正則表達式模式。 r = s.match(re); // 嘗試去匹配搜索字符串。 document.write(r); // 返回的數組包含了所有 "ain" 出現的四個匹配,r[0]、r[1]、r[2]、r[3]。 // 但沒有子匹配項a。}輸出結果:ain,ain,ain,ain
exec 方法
用正則表達式模式在字符串中查找,並返回該查找結果的第一個值(數組),如果匹配失敗,返回null。
rgExp.exec(str)
參數
rgExp
必選項。包含正則表達式模式和可用標志的正則表達式對象。
str
必選項。要在其中執行查找的 String 對象或字符串文字。
返回數組包含:
input:整個被查找的字符串的值;
index:匹配結果所在的位置(位);
lastInput:下一次匹配結果的位置;
arr:結果值,arr[0]全匹配結果,arr[1,2...]為表達式內()的子匹配,由左至右為1,2...。
例子2:
代碼如下:
function RegExpTest(){
var src="http://sumsung753.blog.163.com/blog/I love you!";
var re = /\w+/g; // 注意g將全文匹配,不加將永遠只返回第一個匹配。
var arr;
while((arr = re.exec(src)) !=null){ //exec使arr返回匹配的第一個,while循環一次將使re在g作用尋找下一個匹配。
document.write(arr.index + "-" + arr.lastIndex + ":" + arr + "<br/>");
for(key in arr){
document.write(key + "=>" + arr[key] + "<br/>");
}
document.write("<br/>");
}
}
window.onload = RegExpTest();
輸出結果:
0-1:I //0為index,i所在位置,1為下一個匹配所在位置
input=>I love you!
index=>0
lastIndex=>1
0=>I
2-6:love
input=>I love you!
index=>2
lastIndex=>6
0=>love
7-10:you
input=>I love you!
index=>7
lastIndex=>10
0=>you
說明:根據手冊,exec只返回匹配結果的第一個值,比如上例如果不用while循環,將只返回'I'(盡管i空格後的love和you都符合表達式),無論re表達式用不用全局標記g。但是如果為正則表達式設置了全局標記g,exec 從以 lastIndex 的值指示的位置開始查找。如果沒有設置全局標志,exec 忽略 lastIndex 的值,從字符串的起始位置開始搜索。利用這個特點可以反復調用exec遍歷所有匹配,等價於match具有g標志。
當然,如果正則表達式忘記用g,而又用循環(比如:while、for等),exec將每次都循環第一個,造成死循環。
exec的輸出將包含子匹配項。
例子3:
代碼如下:
function execDemo(){
var r, re; // 聲明變量。
var s = "The rain in Spain falls mainly in the plain";
re = /[\w]*(ai)n/ig;
r = re.exec(s);
document.write(r + "<br/>");
for(key in r){
document.write(key + "-" + r[key] + "<br/>");
}
}
window.onload = execDemo();
輸出:
rain,ai
input-The rain in Spain falls mainly in the plain
index-4
lastIndex-8
0-rain
1-ai
test 方法
返回一個 Boolean 值,它指出在被查找的字符串中是否匹配給出的正則表達式。
rgexp.test(str)
參數
rgexp
必選項。包含正則表達式模式或可用標志的正則表達式對象。
str
必選項。要在其上測試查找的字符串。
說明
test 方法檢查字符串是否與給出的正則表達式模式相匹配,如果是則返回 true,否則就返回 false。
例子4:
代碼如下:
function TestDemo(re, s){
var s1;
if (re.test(s))
s1 = " 匹配正則式 ";
else
s1 = " 不匹配正則式 ";
return("'" + s + "'" + s1 + "'"+ re.source + "'");
}
window.onload = document.write(TestDemo(/ab/,'cdef'));
輸出結果:'cdef' 不匹配正則式 'ab'
注意:test()繼承正則表達式的lastIndex屬性,表達式在匹配全局標志g的時候須注意。
例子5:
代碼如下:
function testDemo(){
var r, re; // 聲明變量。
var s = "I";
re = /I/ig; // 創建正則表達式模式。
document.write(re.test(s) + "<br/>"); // 返回 Boolean 結果。
document.write(re.test(s) + "<br/>");
document.write(re.test(s));
}
testDemo();
輸出結果:
true
false
true
當第二次調用test()的時候,lastIndex指向下一次匹配所在位置1,所以第二次匹配不成功,lastIndex重新指向0,等於第三次又重新匹配。下例顯示test的lastIndex屬性:
例子6:
代碼如下:
function testDemo(){
var r, re; // 聲明變量。
var s = "I";
re = /I/ig; // 創建正則表達式模式。
document.write(re.test(s) + "<br/>"); // 返回 Boolean 結果。
document.write(re.lastIndex); // 返回 Boolean 結果。
}
testDemo();
輸出:
true
1
解決方法:將test()的lastIndex屬性每次重新指向0,re.lastIndex = 0;
search 方法
返回與正則表達式查找內容匹配的第一個子字符串的位置(偏移位)。
stringObj.search(rgExp)
參數
stringObj
必選項。要在其上進行查找的 String 對象或字符串文字。
rgExp
必選項。包含正則表達式模式和可用標志的正則表達式對象。
說明:如果找到則返回子字符至開始處的偏移位,否則返回-1。
例子6:
代碼如下:
function SearchDemo(){
var r, re; // 聲明變量。
var s = "The rain in Spain falls mainly in the plain.";
re = /falls/i; // 創建正則表達式模式。
re2 = /tom/i;
r = s.search(re); // 查找字符串。
r2 = s.search(re2);
return("r:" + r + ";r2:" + r2); // 返回 Boolean 結果。
}
document.write(SearchDemo());
輸出:r:18;r2:-1
replace 方法
返回根據正則表達式進行文字替換後的字符串的復制。
stringObj.replace(rgExp, replaceText)
參數
stringObj
必選項。要執行該替換的 String 對象或字符串文字。該字符串不會被 replace 方法修改。
rgExp
必選項。為包含正則表達式模式或可用標志的正則表達式對象。也可以是 String 對象或文字。如果 rgExp 不是正則表達式對象,它將被轉換為字符串,並進行精確的查找;不要嘗試將字符串轉化為正則表達式。
replaceText
必選項。是一個String 對象或字符串文字,對於stringObj 中每個匹配 rgExp 中的位置都用該對象所包含的文字加以替換。在 Jscript 5.5 或更新版本中,replaceText 參數也可以是返回替換文本的函數。
說明
replace 方法的結果是一個完成了指定替換的 stringObj 對象的復制。意思為匹配的項進行指定替換,其它不變作為StringObj的原樣返回。
ECMAScript v3 規定,replace() 方法的參數 replacement 可以是函數而不是字符串。在這種情況下,每個匹配都調用該函數,它返回的字符串將作為替換文本使用。該函數的第一個參數是匹配模式的字符串。接下來的參數是與模式中的子表達式匹配的字符串,可以有 0 個或多個這樣的參數。接下來的參數是一個整數,聲明了匹配在 stringObject 中出現的位置。最後一個參數是 stringObject 本身。結果為將每一匹配的子字符串替換為函數調用的相應返回值的字符串值。函數作參可以進行更為復雜的操作。
例子7:
代碼如下:
function f2c(s) {
var test = /(\d+(\.\d*)?)F\b/g; // 說明華氏溫度可能模式有:123F或123.4F。注意,這裡用了g模式
return(s.replace
(test,
function(Regstr,$1,$2,$3,newstrObj) {
return(("<br/>" + Regstr +"<br/>" + ($1-32) * 1/2) + "C" +"<br/>" + //以下兩行進行替換
$2 +"<br/>" + $3 +"<br/>" + newstrObj +"<br/>" );
}
)
);
}
document.write(f2c("Water: 32.2F and Oil: 20.30F."));
輸出結果:
Water: //不與正則匹配的字符,按原字符輸出
32.2F //與正則相匹配的第一個字符串的原字符串 Regstr
0.10000000000000142C //與正則相匹配的第一個字符串的第一個子模式匹配的替換結果 $1
.2 //與正則相匹配的第一個字符串的第二個子模式匹配項的替換結果,這裡我們沒有將它替換 $2
7 //與正則相匹配的第一個字符串的第一個子匹配出現的偏移量 $3
Water: 32.2F and Oil: 20.30F. //原字符串 newstrObj
and Oil: //不與正則匹配的字符
20.30F //與正則相匹配的第二個字符串的原字符串
-5.85C //與正則相匹配的第二個字符串的第一個子模式與匹配的替換結果
.30 //與正則相匹配的第二個字符串的第二個子模式匹配項的替換結果,這裡我們沒有將它替換
22 //與正則相匹配的第二個字符串的第一個子匹配出現的偏移量
Water: 32.2F and Oil: 20.30F. //原字符串
. //不與正則匹配的字符
上面的函數參數我們全部用到了。在實際中,我們只須用將xxF替換為xxC,根據要求,我們無須寫這麼多參數。
例子8:
代碼如下:
function f2c(s) {
var test = /(\d+(\.\d*)?)F\b/g; // 說明華氏溫度可能模式有:123F或123.4F
return(s.replace
(test,
function(strObj,$1) {
return((($1-32) * 1/2) + "C");
}
)
);
}
document.write(f2c("Water: 32.2F and Oil: 20.30F."));
輸出:Water: 0.10000000000000142C and Oil: -5.85C.
更多的應用:
例子9:
代碼如下:
function f2c(s) {
var test = /([\d]{4})-([\d]{1,2})-([\d]{1,2})/;
return(s.replace
(test,
function($0,$1,$2,$3) {
return($2 +"/" + $1);
}
)
);
}
document.write(f2c("today: 2011-03-29"));
輸出:today: 03/2011
split 方法
將一個字符串分割為子字符串,然後將結果作為字符串數組返回。
stringObj.split([separator[, limit]])
參數
stringObj
必選項。要被分解的 String 對象或文字。該對象不會被 split 方法修改。
separator
可選項。字符串或 正則表達式 對象,它標識了分隔字符串時使用的是一個還是多個字符。如果忽略該選項,返回包含整個字符串的單一元素數組。
limit
可選項。該值用來限制返回數組中的元素個數。
說明
split 方法的結果是一個字符串數組,在 stingObj 中每個出現 separator 的位置都要進行分解。separator 不作為任何數組元素的部分返回。
例子10:
代碼如下:
function SplitDemo(){
var s, ss;
var s = "The rain in Spain falls mainly in the plain.";
// 正則表達式,用不分大不寫的s進行分隔。
ss = s.split(/s/i);
return(ss);
}
document.write(SplitDemo());
輸出:The rain in ,pain fall, mainly in the plain.
js正則表達式之exec()方法、match()方法以及search()方法
先看代碼:
var sToMatch = "test, Tes, tst, tset, Test, Tesyt, sTes";
var reEs = /es/gi;
alert(reEs.exec(sToMatch));
alert(sToMatch.match(reEs));
alert(sToMatch.search(reEs));
三個彈出框內容如下:
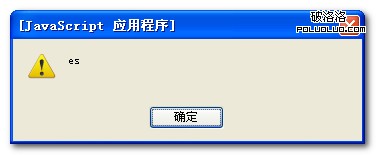
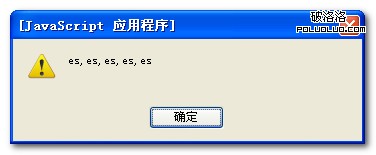
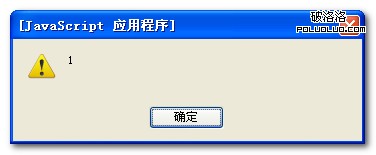
結果分析如下:
1、RegExp的exec()方法,有一個字符串參數,返回一個數組,數組的第一個條目是第一個匹配;其他的是反向引用。所以第一個返回的結果是第一個匹配的值es(不區分大小寫)。www.2cto.com
2、String對象有一個match()方法,它返回一個包含在字符串中所有匹配的數據。這個方法調用string對象,同時傳給它一個RegExp對象。所以第二個彈出語句返回的是所有符合正則表達式的數組。
3、search()的字符串方法與indexOf()有些類似,但是它使用一個RegExp對象而非僅僅一個子字符串。search()方法返回第一個匹配值的位置。所以第三處彈出的是“1”,即第二個字符就匹配了。注意的是search()方法不支持全局匹配正規表達式(帶參數g)。
作者:wjc19911118