在這之前,我曾經嘗試過一個項目,就是將我們的PHP代碼自動生成so擴展,
編譯到PHP中,我叫它 phptoc。
但是由於各種原因,暫停了此項目。
寫這篇文章一是因為這方面資料太少,二是把自己的收獲總結下來,以便以後參考,如果能明白PHP語法分析
那對PHP源碼的研究會更上一層樓地 ^.^…
我盡可能寫的通俗易懂些。
這個項目思路源於facebook的開源項目 HipHop .
其實我對這個項目的性能提高50%-60%持懷疑態度,從根本來講,如果PHP用到APC緩存,它的性能是否低
於HipHop,我還沒有做測試,不敢斷言。
PHPtoc,我只是想把C程序員解放出來,希望能達到,讓PHPer用PHP代碼就可以寫出接近於PHP擴展性能的一個擴展,
它的流程如下,讀取PHP文件,解析PHP代碼,對其進行語法分析器,生成對應的ZendAPI,編譯成擴展。
進入正題
這裡最難的就是語法分析器了,大家應該都知道,PHP也有自己的語法分析器,現在版本用到的是re2c 和 Bison。
所以,我自然也用到了這個組合。
如果要用PHP的語法分析器就不太現實了,因為需要修改zend_language_parser.y和 zend_language_scanner.l 並重新編譯,這難度大不說,還可能影響PHP自身。
所以決定重新寫一套自己的語法分析規則,這個功能就等於是重寫了PHP的語法分析器,當然會捨棄一些不常用的。
re2c && yacc/bison,通過引用自己的對應文件,然後將他們統一編譯成一個*.c文件,最後再gcc編譯就會生
成我們自己的程序。所以說,他們從根本來講不是語法分析程序,他們只是將我們的規則生成一個獨立的c文
件,這個c文件才是真正的我們需要的語法分析程序,我更願意叫它 語法生成器。如下圖:
注:圖中a.c是 掃描器生成的最終代碼。。
re2c掃描器,假如我們寫的掃描規則文件叫scanner.l,它會將我們寫的PHP文件內容,進行掃描,然後根據
我們寫的規則,生成不同的token傳遞給parse。
我們寫的(f)lex語法規則,比如我們叫他Parse.y
會通過 yacc/bison編譯成一個parse.tab.h,parse.tab.c的文件,parse根據不同的token進行不同的操作
比如我們PHP代碼是 “echo 1″;
掃描其中有一個規則:
"echo" {
return T_ECHO;
}
掃描器函數scan會拿到”echo 1″字符串,它對這一段代碼進行循環,如果發現有echo字符串,那麼它就作為關鍵字返回token:T_ECHO,
parse.y和scanner.l會分別生成兩個c文件,scanner.c和parse.tab.c,用gcc編譯到一起,就成了。
下面會具體的說一說
感興趣的可以去看看,我也翻譯了一個中文版本,
還麼有結束,稍後我會放上來。
re2c提供了一些宏接口,方面我們使用,我簡單做了翻譯,英語水平不好,可能有誤,需要原文的可以去上面那個地址查看。
接口代碼:
不像其他的掃描器程序,re2c 不會生成完整的掃描器:用戶必須提供一些接口代碼。用戶必須定義下面的宏或者是其他相應的配置。
YYCONDTYPE
用-c 模式你可以使用-to參數用來生成一個文件:使用包含枚舉類型的作為條件。每個值都會在規則集合裡面作為條件來使用。
YYCTYPE
用來維持一個輸入符號。通常是 char 或者unsigned char。
YYCTXMARKER
*YYCTYPE類型的表達式,生成的代碼回溯信息的上下文會保存在 YYCTXMARKER。如果掃描器規則需要使用上下文中的一個或多個正則表達式則用戶需要定義這個宏。
YYCURSOR
*YYCTYPE類型的表達式指針指向當前輸入的符號,生成的代碼作為符號相匹配,在開始的地方,YYCURSOR假定指向當前token的第一個字符。結束時,YYCURSOR將會指向下一個token的第一個字符。
YYDEBUG(state,current)
這個只有指定-d標示符的時候才會需要。調用用戶定義的函數時可以非常容易的調試生成的代碼。
這個函數應該有以下簽名:void YYDEBUG(int state,char current)。第一個參數接受 state ,默認值為-1第二個參數接受輸入的當前位置。
YYFILL(n)
當緩沖器需要填充的時候,生成的代碼將會調用YYFILL(n):至少提供n個字符。YYFILL(n)將會根據需要調整YYCURSOR,YYLIMIT,YYMARKER 和 YYCTXMARKER。注意在典型的程序語言當中,n等於最長的關鍵詞的長度加一。用戶可以在/*!max:re2c*/一次定義YYMAXFILL來指定最長長度。如果使用了-1,YYMAXFILL將會在/*!re2c*/之後調用一次阻塞。
YYGETCONDITION()
如果使用了-c模式,這個定義將會在掃描器代碼之前獲取條件集。這個值,必須初始化為枚舉YYCONDTYPE的類型。
YYGETSTATE()
如果-f模式指定了,用戶就需要定義這個宏。如果這樣,掃描器在開始時為了獲取保存的狀態,生成的代碼將會調用YYGETSTATE(),YYGETSTATE()必須返回一個帶符號的整數,這個值如果是-1,告訴掃描器這是第一次執行,否則這個值等於以前YYSETSTATE(s) 保存的狀態。否則,掃描器將會恢復操作之後立即調用YYFILL(n)。
YYLIMIT
表達式的類型 *YYCTYPE 標記緩沖器的結尾(YYLIMIT(-1)是緩沖區的最後一個字符)。生成的代碼將會不斷的比較YYCORSUR 和 YYLIMIT 以決定 什麼時候填充緩沖區。
YYSETCONDITION(c)
這個宏用來在轉換規則中設置條件,它只會在指定-c模式 和 使用轉換規則時有用。
YYSETSTATE(s)
用戶只需要在指定-f模式時定義這個宏,如果是這樣,生成的代碼將會在YYFILL(n)之前調用YYSETSTATE(s),YYSETSTATE的參數是一個有符號整型,被稱為唯一的標示特定的YYFILL(n)實例。
YYMARKER
類型為*YYCTYPE的表達式,生成的代碼保存回溯信息到YYMARKER。一些簡單的掃描器可能用不到。
掃描器,顧名思義,就是對文件掃描,找出關鍵代碼來。
掃描器文件結構:
/* #include 文件*/
/*宏定義*/
//掃描函數
int scan(char *p){
/*掃描器規則區*/
}
//執行scan掃描函數,返回token到yacc/bison中。
int yylex(){
int token;
char *p=YYCURSOR;//YYCURSOR是一個指針,指向我們的PHP文本內容
while(token=scan(p)){//這裡會移動指針p,一個一個判斷是不是我們上面定義好的scanner...
return token;
}
}
int main(int argc,char**argv){
BEGIN(INITIAL);//
YYCURSOR=argv[1];//YYCURSOR是一個指針,指向我們的PHP文本內容,
yyparse();
}
BEGIN 是定義的宏
#define YYCTYPE char //輸入符號的類型
#define STATE(name) yyc##name
#define BEGIN(n) YYSETCONDITION(STATE(n))
#define LANG_SCNG(v) (sc_globals.v)
#define SCNG LANG_SCNG
#define YYGETCONDITION() SCNG(yy_state)
#define YYSETCONDITION(s) SCNG(yy_state)=s
yyparse函數是在yacc 中定義的,
裡面有一個關鍵宏: YYLEX
#define YYLEX yylex()
它會執行scaner掃描器的yylex
可能會有點繞,重新縷一縷:
在scanner.l中,通過調用parse.y解析器函數yyparse,該函數調用scanner.l的yylex生成關鍵代碼token,yylex
將掃描器返回的
token返回給parse.y,parse根據不同的token執行不同的代碼.
舉例:
scanner.l
#include "scanner.h"
#include "parse.tab.h"
int scan(char *p){
/*!re2c
<INITIAL>"<?php"([ \t]|{NEWLINE})? {
BEGIN(ST_IN_SCRIPTING);
return T_OPEN_TAG;
}
"echo" {
return T_ECHO;
}
[0-9]+ {
return T_LNUMBER;
}
*/
}
int yylex(){
int c;
// return T_STRING;
int token;
char *p=YYCURSOR;
while(token=scan(p)){
return token;
}
}
int main (int argc,char ** argv){
BEGIN(INITIAL);//初始化
YYCURSOR=argv[1];//將用戶輸入的字符串放到YYCURSOR
yyparse();//yyparse() -》yylex()-》yyparse()
return 0;
}
這樣一個簡單的掃描器就做成了,
那解析器呢?
解析器我用的是flex和bison。。。
關於flex的文件結構:
%{
/*
C代碼段將逐字拷貝到lex編譯後產生的C源文件中
可以定義一些全局變量,數組,函數例程等...
*/
#include
#include "scanner.h"
extern int yylex();//它在scanner.l中定義的。。
void yyerror(char *);
# define YYPARSE_PARAM tsrm_ls
# define YYLEX_PARAM tsrm_ls
%}
{定義段,也就是token定義的地方}
//這就是關鍵 token程序是根據這是做switch的。
%token T_OPEN_TAG
%token T_ECHO
%token T_LNUMBER
%%
{規則段}
start:
T_OPEN_TAG{printf("start\n"); }
|start statement
;
statement:
T_ECHO expr {printf("echo :%s\n",$3)}
;
expr:
T_LNUMBER {$$=$1;}
%%
{用戶代碼段}
void yyerror(char *msg){
printf("error:%s\n",msg);
}
在規則段中,start是開始的地方,如果 scan識別到PHP開始標簽就會返回T_OPEN_TAG,然後執行括號的代碼,輸出start.
在scanner.l中,調用scan的是個while循環,所以它會檢查到php代碼的末尾,
yyparse會根據scan返回的標記做switch,然後goto到相應的代碼,比如 yyparse.y發現當前的token是T_OPEN_TAG,
它會通過宏 #line 映射到 parse.y所對應 21行,T_OPEN_TAG的位置,然後執行
那,TOKEN返回給yyparse之後做了什麼呢?
為了能直觀一些,我用gdb跟蹤:
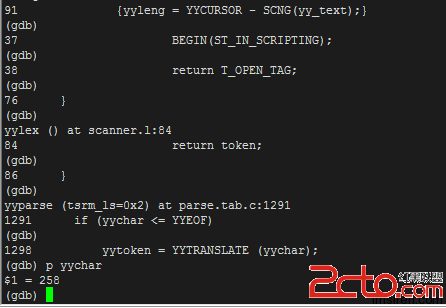
這個時候yychar是258,258是什麼?
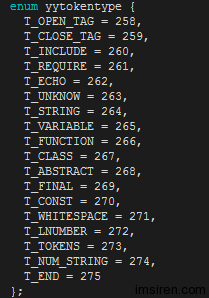
258是bison自動生成的枚舉類型數據。
繼續
YYTRANSLATE宏接受yychar,然後返回所對應的值
#define YYTRANSLATE(YYX) \
((unsigned int) (YYX) <= YYMAXUTOK ? yytranslate[YYX] : YYUNDEFTOK)
/* YYTRANSLATE[YYLEX] -- Bison symbol number corresponding to YYLEX. */
static const yytype_uint8 yytranslate[] =
{
0, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 27, 2,
22, 23, 2, 2, 28, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 21,
2, 26, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 24, 2, 25, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 1, 2, 3, 4,
5, 6, 7, 8, 9, 10, 11, 12, 13, 14,
15, 16, 17, 18, 19, 20
};
yyparse拿到這個值,不斷地translate,
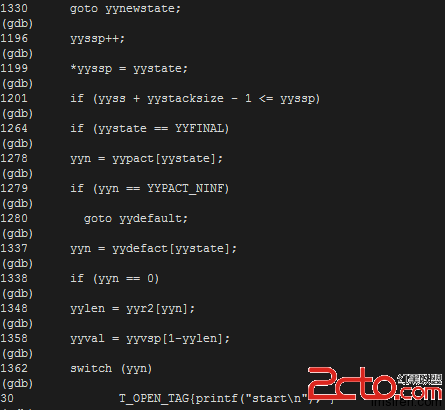
bison會生成很多用來映射的數組,將最終的translate保存到yyn,
這樣bison就能找到token所對應的代碼
switch (yyn)
{
case 2:
/* Line 1455 of yacc.c */
#line 30 "parse.y"
{printf("start\n"); ;}
break;
這樣,不斷循環,生成token逐條執行,然後解析成所對應的zend 函數等,生成對應的op保存在哈希表中,這些不是本文的重點,