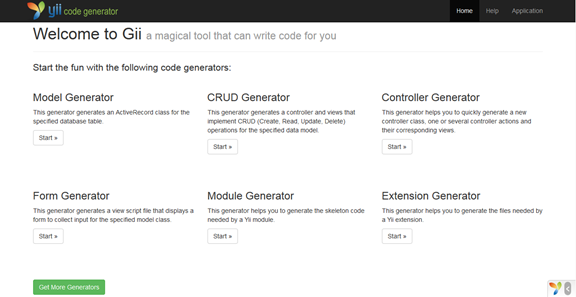
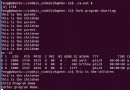
最近php機器頻繁出現過載後再也無法提供服務的現象,只要一有請求發過去,負責處理該請求的php進程就是cpu占用100%。本來的負載均衡策略是一旦某機器的php請求出現連接超時就將該機器的權重降低,發向該機器的請求概率就會降低,雖然有一定滯後效應,但是最終應該能夠降壓並且最後恢復服務,但是這個策略在最近突然失效了。出現這個情況之後無法發送什麼請求到php-fpm都會cpu100%,即使請求的是一個空的php文件。於是猜想可能是eaccelerator造成的。 我們的Php-fpm的request_terminate_timeout設置的是5s,於是只要是有請求執行超過5s就會被php-fpm將執行進程干掉,在出問題的前後出現了大量的5s超時,初步猜想可能是因為eaccelerator的共享內存造成的,子進程被干掉時共享內存被寫錯了,導致所有請求過來都會出錯,但是這解釋不了新文件也會被卡住的問題,於是去看eacceleraotr的代碼,發現如下代碼 [cpp] #define spinlock_try_lock(rw) asm volatile("lock ; decl %0" :"=m" ((rw)->lock) : : "memory") #define _spinlock_unlock(rw) asm volatile("lock ; incl %0" :"=m" ((rw)->lock) : : "memory") static int mm_do_lock(mm_mutex* lock, int kind) { while (1) { spinlock_try_lock(lock); if (lock->lock == 0) { lock->pid = getpid(); lock->locked = 1; return 1; } _spinlock_unlock(lock); sched_yield(); } return 1; } static int mm_do_unlock(mm_mutex* lock) { if (lock->locked && (lock->pid == getpid())) { lock->pid = 0; lock->locked = 0; _spinlock_unlock(lock); } return 1; } [cpp] 其中mm_mutex是指向共享內存的,也就是說eac用了共享內存來當作進程間的鎖,並且使用的spinlock方式,那這樣一來一切都能解釋的通了。設想如下一種情況,某個進程拿到鎖之後被php-fpm干掉了,它沒有unlock,這樣一來所有的php-fpm子進程都拿不到鎖,於是大家就都在這個while(1)循環裡卡死了。猜想有了,怎麼去證實呢?原來的想法是直接去讀那片共享內存,結果發現php時IPC_PRIVATE的,所以沒辦法讀了。於是只能等到線上出問題後gdb上去看內存,今天終於有了確鑿的證據 [html] (gdb) p *mm->lock $8 = {lock = 4294966693, pid = 21775, locked = 1} 這裡可以看到內存已經被進程號為21775的進程拿到了,但事實是,這個進程在很早以前就已經被干掉了。 問題得到證實了,那麼再回頭看一下這個問題發生的條件 1、請求執行時間很長,長到會被php-fpm干掉 2、進程被干掉時,php正在require文件,並且eac拿到了鎖 從這裡可以看到,有一些特定情形會將這個概率放大 1、request_terminate_timeout時間很短 2、使用auoload方式,或者在執行邏輯裡require文件,因為如果在請求開始前就將所有的文件加載,那除非光require文件就已經超時,否則不應該會在require文件時被干掉。但是同樣的使用autload方式也有一個比較丑陋的辦法可以避過這個問題,那就是在autload函數裡判斷一下,如果執行時間過長了就直接exit而不是require 個人覺得,解決這個問題的最好辦法是request_terminate_timeout時間設置的足夠長,比如30s, 300s,而將超時判斷全部放在應用層,不能通過php-fpm來處理這種問題,php-fpm事實只能用作最後一重保險,不得不使用的保險。另外php裡還有一個超時設置max_execution_time,但是這個超時在cgi模式下是cpu時間,所以作用不大