Split它會根據給定的模式拆分字符串,對於使用制表符、冒號、空白符或任意符號分隔不同字段的字符串來說,用這個操作符分解提取字段相當方便。只要你能將分隔符寫成模式(通常是很簡單的正則表達式),就可以用Split分解數據。它的用法如下:
my @fields = split /separator/, $string;
這裡的Split操作符用拆分模式掃描指定的字符串並返回字段(也就是子字符串)列表。期間只要模式在某處匹配成功,該處就是當前字段的結尾、下一字段的開頭。所以,任何匹配模式的內容都不會出現在返回字段中。下面就是典型的以冒號作為分隔符的Split模式:
my @fields = split /:/, “abc:def:g:h”; #得到(“abc”,“def”,“g”,“h”)
如果兩個分隔符連在一起,就會產生空字段:
my @fields = split /:/, “abc:def::g:h”; #得到(“abc”,“def”,“”,“g”,“h”)
這裡有個規則,它乍看之下很古怪,但很少造成問題:Split會保留開頭處的空字段,卻捨去結尾處的空字段。例如:
my @fields = split /:/, “:::a:b:c:::”; #得到(“”,“”,“”,“a”,“b”,“c”)
利用Split的/\s+/模式根據空白符分隔字符也是比較常見的做法。該模式把所有連續空白都視作單個空格並以此切分數據:
my $some_input = “This is a \t test.\n”;
my @args = split /\s+/, $some_input; #得到(“This”,“is”,“a”,“test.”)
默認Split會以空白符分隔$_中的字符串:
my @fields = split; #等效於split /\s+/,$_;
這幾乎就等於以/\s+/為模式,只是它會省略開頭的空字段。所以,即使該行以空白開頭,你也不會在返回列表的開頭處看到空字段。若你想以這種方式來分解用空格分隔的字符串,則可以用一個空格來作為模式:split ‘’, $other_string用一個空格來作為模式是split的特殊用法。
一般來說,用在Split中的模式就像之前看到的這樣簡單。但如果你用到更復雜的模式,請避免在模式裡使用捕獲圓括號,因為這會啟動所謂的“分隔符保留模式(詳情請參見Perlfunc文檔)。如果需要在模式中使用分組匹配,請在Split裡使用非捕獲圓括號(?:)的寫法,以避免意外。
進一步加深對Split分解提取字段帶來的方便。下面給出一段我實際工作中未使用Split操作符分解提取字段的代碼(後面還將給出使用Split操作符的代碼)對比從中感受一下它的強大:
任務:從passwd文件中提取用戶名、用戶主目錄信息;
我們先看一下passwd文件中記錄格式(圖1-1 部份摘錄):
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/bin/sh
……
可以看出每個字段都用冒號(:)進行分隔,以第一條記錄從左向右為例我們要提取第一個冒號前面的root(用戶名)和第六個冒號前面的/root(用戶主目錄)。
[php]
#代碼1.1 未使用Split操作符提取字段代碼;
#!/usr/bin/perl -w
use strict;
open (FH, '/etc/passwd') or die "Can't open file: $!";
while (<FH>){
my ($Pos,$endPos,$length,$Name,$Dir);
#############
# 取用戶名稱
#############
$length = index ($_, ":");
$Name = substr ($_, 0, $length);
#####################
# 取用戶HOME目錄位置
#####################
$endPos = rindex ($_, ":");
# $endPos-1跳過當前位置(冒號)
$Pos = rindex ($_, ":", $endPos - 1);
# $Pos+1跳過當前位置(冒號)
# 查找方向從左向右。所以+1
$Pos += 1;
$length = $endPos - $Pos;
$Dir = substr ($_, $Pos, $length);
print "$Name\t$Dir\n";
}
close (FH);
程序運行後輸出如下(圖1-2):
root /root
bin /bin
……
現在我們來分析一下這段代碼的算法,提取用戶名很簡單只需要找到第一個冒號位置通過substr($_,0,$length)函數返回的子字符串即是需要的用戶名。算法比較復雜的部份是提取用戶主目錄,通過圖1-1可見passwd文件本身是有著固定格式的,記錄從後向前(從右向左)倒數第二個冒號後面的/root就是用戶主目錄信息。
提取用戶主目錄算法思想:
1、 略過記錄最後一個字段;
2、 找到倒數第二個字段起始位置;
3、 倒數第一個字段的起始(冒號)位置減去倒數第二個字段字符的開始位置(/號),得出來的結果就是用戶主目錄字段中的字符長度;
4、 substr($_,$Pos,$length);返回用戶主目錄信息;
5、完成。
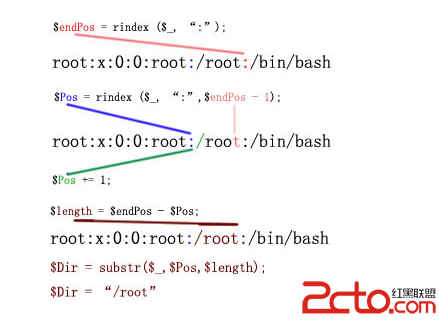 (圖 1-3 提取用戶目錄算法)
總結,通過Perl字符串處理函定位、提取字段信息可以完成我們的任務,可預見當我們要提取多個不相連字段,步驟將更繁瑣,代碼更長,也更加容易出錯,如果,記錄各字段位置發生改變,你將不得不重新設計你的算法。
現在,我們再看使用Split操作符分解提取字段的例子:
[php]
#代碼1.2 使用Split操作符提取字段代碼;
#!/usr/bin/perl -w
use strict;
open (FH, '/etc/passwd') or die "Can't open file: $!";
while (<FH>){
###########
# 取用戶信息
###########
my($Name,$Dir) = (split /:/,$_)[0,5];
print "$Name\t$Dir\n";
}
close (FH);
。
(圖 1-3 提取用戶目錄算法)
總結,通過Perl字符串處理函定位、提取字段信息可以完成我們的任務,可預見當我們要提取多個不相連字段,步驟將更繁瑣,代碼更長,也更加容易出錯,如果,記錄各字段位置發生改變,你將不得不重新設計你的算法。
現在,我們再看使用Split操作符分解提取字段的例子:
[php]
#代碼1.2 使用Split操作符提取字段代碼;
#!/usr/bin/perl -w
use strict;
open (FH, '/etc/passwd') or die "Can't open file: $!";
while (<FH>){
###########
# 取用戶信息
###########
my($Name,$Dir) = (split /:/,$_)[0,5];
print "$Name\t$Dir\n";
}
close (FH);
。