亂碼產生原因
mysql字符編碼是版本4.1引入的,支持多國語言,而且一些特性已經超過了其他的數據庫系統。
我們可以在MySQL Command Line Client 下輸入如下命令查看mysql的字符集
mysql> SHOW CHARACTER SET;
+----------+-----------------------------+---------------------+--------+
| Charset | Description | Default collation | Maxlen |
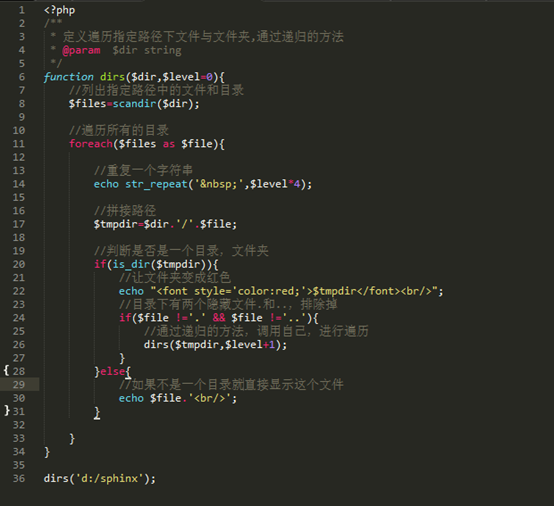
+----------+-----------------------------+---------------------+--------+
| big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 |
| dec8 | DEC West European | dec8_swedish_ci | 1 |
| cp850 | DOS West European | cp850_general_ci | 1 |
| hp8 | HP West European | hp8_english_ci | 1 |
| koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 |
| latin1 | cp1252 West European | latin1_swedish_ci | 1 |
| latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 |
| swe7 | 7bit Swedish | swe7_swedish_ci | 1 |
| ascii | US ASCII | ascii_general_ci | 1 |
| ujis | EUC-JP Japanese | ujis_japanese_ci | 3 |
| sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 |
| hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 |
| tis620 | TIS620 Thai | tis620_thai_ci | 1 |
| euckr | EUC-KR Korean | euckr_korean_ci | 2 |
| koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 |
| gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 |
| greek | ISO 8859-7 Greek | greek_general_ci | 1 |
| cp1250 | Windows Central European | cp1250_general_ci | 1 |
| gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 |
| latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 |
| armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 |
| utf8 | UTF-8 Unicode | utf8_general_ci | 3 |
| ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 |
| cp866 | DOS Russian | cp866_general_ci | 1 |
| keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 |
| macce | Mac Central European | macce_general_ci | 1 |
| macroman | Mac West European | macroman_general_ci | 1 |
| cp852 | DOS Central European | cp852_general_ci | 1 |
| latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 |
| cp1251 | Windows Cyrillic | cp1251_general_ci | 1 |
| cp1256 | Windows Arabic | cp1256_general_ci | 1 |
| cp1257 | Windows Baltic | cp1257_general_ci | 1 |
| binary | Binary pseudo charset | binary | 1 |
| geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 |
| cp932 | SJIS for Windows Japanese | cp932_japanese_ci | 2 |
| eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci | 3 |
+----------+-----------------------------+---------------------+--------+
36 rows in set (0.02 sec)
更多mysql的字符集知識可以參考本論壇的
http://www.phpfans.net/bbs/viewt ... &extra=page%3D1
或者mysql官方的
http://dev.mysql.com/doc/refman/5.1/zh/charset.html
MySQL 4.1的字符集支持(Character Set Support)有兩個方面:字符集(Character set)和排序方式(Collation)。對於字符集的支持細化到四個層次: 服務器(server),數據庫(database),數據表(table)和連接(connection)。
查看系統的字符集和排序方式的設定可以通過下面的兩條命令:
mysql> SHOW VARIABLES LIKE 'character_set_%';
+--------------------------+-------------------------------------------+
| Variable_name | Value |
+--------------------------+-------------------------------------------+
| character_set_client | latin1 |
| character_set_connection | latin1 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | latin1 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | D:\MySQL\MySQL Server 5.0\share\charsets\ |
+--------------------------+-------------------------------------------+
8 rows in set (0.06 sec)
mysql> SHOW VARIABLES LIKE 'collation_%';
+----------------------+-------------------+
| Variable_name | Value |
+----------------------+-------------------+
| collation_connection | latin1_swedish_ci |
| collation_database | latin1_swedish_ci |
| collation_server | latin1_swedish_ci |
+----------------------+-------------------+
3 rows in set (0.02 sec)
上面列出的值就是系統的默認值。latin1默認校對規則是latin1_swedish_ci,默認是latin1的瑞典語排序方式.
為什麼呢默認會是latin1_swedish_ci呢,追溯一下mysql歷史很容易發現
1979年,一家瑞典公司Tcx欲開發一個快速的多線程、多用戶數據庫系統。Tcx 公司起初想利用mSQL和他們自己的快速低級例程 (Indexed Sequential Access Method,ISAM)去連接數據庫表,然而,在一些測試以後得出結論:mSQL對其需求來說不夠快速和靈活。這就產生了一個連接器數據庫的新SQL接口,它使用幾乎和mSQL一樣的API接口。這個API被設計成可以使那些由mSQL而寫的第三方代碼更容易地移植到MySQL。
相信如果mysql是中國開發的,那麼漢語也是默認編碼了
當然我們也可以自己需要修改mysql的默認字符集
在mysql配置文檔my.ini,找到如下兩句:
[mysql]
default-character-set=latin1
和
# created and no character set is defined
default-character-set=latin1
修改後面的值就可以。
這裡不建議改,仍保留默認值
也就是說啟動 mysql時,如果沒指定指定一個默認的的字符集,這個值繼承自配置文件中的;
此時 character_set_server 被設定為這個默認的字符集; 當創建一個新的數據庫時,
除非明確指定,這個數據庫的字符集被缺省設定為 character_set_server; 當選定了一個數據庫時,
character_set_database 被設定為這個數據庫默認的字符集; 在這個數據庫裡創建一張表時,
表默認的字符集被設定為 character_set_database,也就是這個數據庫默認的字符集;
當在表內設置一欄時,除非明確指定,否則此欄缺省的字符集就是表默認的字符集。
這樣問題就隨之而來了,假如一數據庫是gbk編碼。如果訪問數據庫時沒指定其的字符集是gbk。
那麼這個值將繼承系統的latin1,這樣就做成mysql中文亂碼。
亂碼解決方法
要解決亂碼問題,首先必須弄清楚自己數據庫用什麼編碼。如果沒有指明,將是默認的latin1。
我們用得最多的應該是這3種字符集 gb2312,gbk,utf8。
那麼我們如何去指定數據庫的字符集呢?下面也gbk為例
【在MySQL Command Line Client創建數據庫 】
mysql> CREATE TABLE `mysqlcode` (
-> `id` TINYINT( 255 ) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY ,
-> `content` VARCHAR( 255 ) NOT NULL
-> ) TYPE = MYISAM CHARACTER SET gbk COLLATE gbk_chinese_ci;
Query OK, 0 rows affected, 1 warning (0.03 sec)