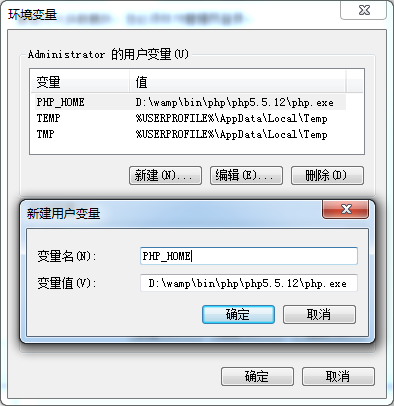
前言:
第一次寫教程,其實算不得教程,只是想總結個轉換的手記。如果中間有錯誤,或者辦法不夠理想,大家回貼研究下。
另外,我也希望我們論壇不僅僅作為閒聊的地方,也希望大家能活躍我們論壇的學習氣氛,畢竟我們都來自一個應該給我們知識的地方,不論你從那裡獲得了多少你需要的知識。
好了,言歸正傳。
一准備:
環境:MySQL4.1.x及以上版本。
Convertz——文本編碼轉換工具,molyx上介紹的,我采用的。其實這類工具很多。
二理論:
MySQL從4.1版本開始內部存儲字符集支持了UTF-8,這個我也是這幾天才看到的。因為升級論壇過程中,服務器數據庫環境為4.0.26當時不知道並不支持utf-8字符集,還廢了些周折。這樣如果涉及到UTF-8轉儲還要升級MySQL版本到4.1以上。
轉換的大概思路是——備份(有備無緩)→修復數據庫→mysqldump導出→Convertz轉換編碼→修改轉換後文件→mysqldump導入恢復
三實踐:
1、備份。這個不需要太多說了你可以采用任何一種常規的備份方式只要你自己恢復的了。
2、修復。mysqlcheck -r -u user -p 如果全OK那就OK了,如果不全OK,再來遍。還沒全OK,不知道怎麼弄了。
3、導出。由於latin1為默認存儲,所以你需要事先確定你數據庫的編碼格式。舉例,lncz.net原為gbk編碼,但存儲為latin1,這樣導出時應該指定編碼為latin1,導出後才能以ANSI形式正確顯示gbk的文字。
導出命令:mysqldump database_name field > path --default-character-set=latin1 -u user -p
數據庫大需要分段,不然接下來的操作會很麻煩。我是單獨把每個表導出來的。當時想法比較簡單,因為數據庫有壞表,只想在恢復的時候知道哪個表出錯單獨修復。
4、轉換。Convertz用這個軟件很簡單,不必多說了。
5、修改。我在嘗試直接導入恢復數據庫時,失敗了N次,每次都亂碼。仔細想過之後才明白,如果你直接導回去,數據庫還是用默認的latin1去存儲,而你的現在的編碼是utf-8所以它會再進行一次轉換便出錯了。這裡MySQL到底怎麼處理的我還不是十分清楚,誰知道麻煩相告。這時我們需要對轉換好的文件加入語句 “set names utf8;”注意不是utf-8;並且需要將文件中“CHARSET=latin1;”改為“CHARSET=utf8;”來指定表的存儲編碼。
6、恢復。恢復過程按道理應該是很簡單的,都是mysqldump處理。需要注意一點就是如果你的數據庫大,要做全局變量的修改max_allowed_packet默認為1M,看你數據庫表的大小,相應修改my.ini文件。
導入命令:mysqldump database_name < path -u user -p 導入順利的話你的數據庫編碼就已經轉換為utf-8了。
在下比較菜,如果有錯誤請指正,表笑我。以上僅供參考。