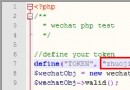
原理很簡單,因為gb2312/gbk是中文兩字節,這兩個字節是有取值范圍的,而utf-8中漢字是三字節,同樣每個字節也有取值范圍。而英文不 管在何種編碼情況下,都是小於128,只占用一個字節(全角除外)。
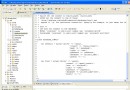
如果是文件形式的編碼檢查,還可以直接check utf-8的BOM信息。話不多說,直接上函數,這個函數是用來對字符串進行檢查和轉碼的。
<?php
function safeEncoding($string,$outEncoding ='UTF-8')
{
$encoding = "UTF-8";
for($i=0;$i<strlen($string);$i++)
{
if(ord($string{$i})<128)
continue;
if((ord($string{$i})&224)==224)
{
//第一個字節判斷通過
$char = $string{++$i};
if((ord($char)&128)==128)
{
//第二個字節判斷通過
$char = $string{++$i};
if((ord($char)&128)==128)
{
$encoding = "UTF-8";
break;
}
}
}
if((ord($string{$i})&192)==192)
{
//第一個字節判斷通過
$char = $string{++$i};
if((ord($char)&128)==128)
{
// 第二個字節判斷通過
$encoding = "GB2312";
break;
}
}
}
if(strtoupper($encoding) == strtoupper($outEncoding))
return $string;
else
return iconv($encoding,$outEncoding,$string);
}
?>