超級負載均衡旨在為解決服務不斷擴展、機器不斷增多、機器性能差異等問題,以增強系統的穩定性,自動分配請求壓力。算法實現了多個模型和均衡策略,能通過配置實現隨機、輪詢、一致hash等。同時也能實現跨機房的相關分配。現已經在多個系統中使用。
TAG
負載均衡
內容
現有系統中存在的問題:
1. 慢連接、瞬時訪問慢。
場景一:
如果後端新增加機器,cache命中率低,因此響應速度慢,但是能連接上且不超時。如果ui持續訪問就會把ui夯住。
場景二:
如果後端模塊某一台機器響應較慢。如果前端持續訪問就會被夯住。
2. 死機。
場景一:
能斷斷續續響應請求,不過速度很慢。造成ui夯住。
3. 混合部署。
場景一:
多個模塊在同一機器上,項目影響。
4. 機器權重。
場景一:
老機器,性能差;新機器,性能彪悍。因此他們應該承載不同的壓力。
5. 跨機房冗余。
場景一:
後端對cache依賴很高的模塊,因為采用的是一致hash算法,如果掛掉一台機器,對另外的機器cache命中率沖擊很大。因此希望將對這個機器的請求均衡到另外一個機房。
6. php和c使用同樣的策略。
現在php和c希望能使用的策略實際上是有很大的一致。為了避免重復開發,php和c希望采用同樣的負載均衡庫。
要解決的問題:
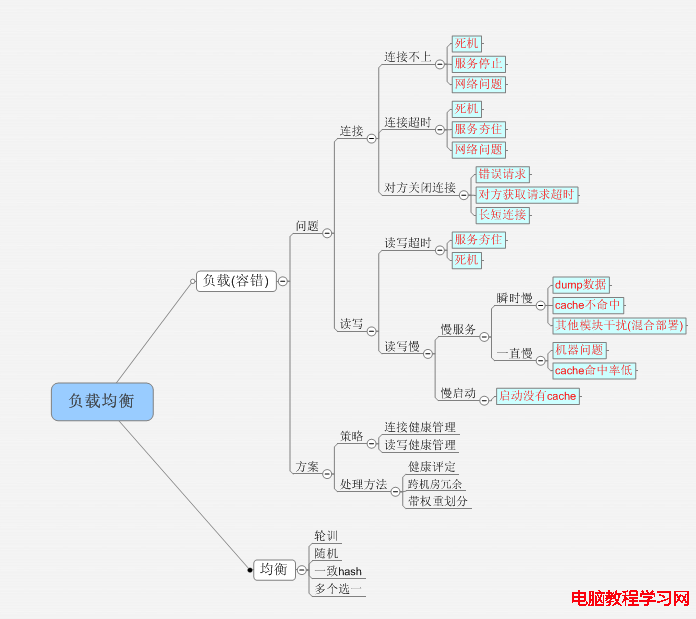
設計思路:
1. 根據均衡策略計算出的均衡值對Server進行逆序排序。
2. 負載選擇。對步驟1排序後的Server按以下順序進行選擇:
a、按連接失敗概率進行選擇。
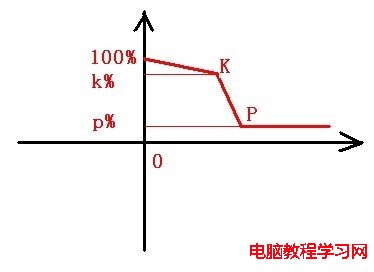
注:橫軸代表失敗次數,縱軸代表選擇的概率。
Cconn:一段區間內失敗次數
f(Cconn):連接概率,取值范圍在(0,100]
b、按健康狀態選擇。
整個模型基於服務處理時間的收斂性。
分析:
1) 如果機器狀態良好,則平均處理時間會保持在一個穩定水平;即使是小波動,也會較快平穩在一個狀態。
2) 如果機器開始出現問題,處理時間會開始增長。如果增長持續超過一段時間,則說明有可能會影響服務;如果一段時間後穩定了,說明對請求沒有太多影響。
f(healthy):機器健康狀態,取值范圍[0,1]
select(healthy):機器選擇概率,取值范圍[R,1]
c、如果所有機器都沒選中,則隨機選擇一台機器進行服務。
3. 機器流量均分。
不同的機器處理能力是不一樣的。當按照步驟2選擇了某台機器,需要將其他處理時間為他的1/T(T>=2)的機器也選取出來,將部分壓力分給對應的機器。
設k台機器的處理時間分別是t1, t2,…,tk, 選中的機器id=i,比該機器處理能力高的機器時間分別為p1,p2,..,pr, (其中pj × T <= ti)。設一段時間總訪問量為Y,每台機器理論上的訪問量應該為Vg=Y/k。而實際的Vr=Y/(ti * (1/t1+1/t2+…+1/tk))。則應該分出Vg-Vr的流量給pj。pj的流量比例為1/p1:1/p2:…:1/pr
算法設計:
A、均衡算法
1. 一致hash算法。
將每個server的ip和port加上balance_key三者做字符串拼接後,做md5簽名。
value(server) = md5(server_ip + server_port + balance_key)
2. 隨機算法。
value(server) = random();
3. 輪詢算法。
value(server) =((server.id – (rounds % server_count)) + server_count) % server_count
4. 多個選一算法。
rank初始化為1, 如果默認的server失敗,則rank+1
value(server) =((server.id – (rank % server_count)) + server_count) % server_count
B、負載算法
1. 連接狀態算法。
a、對每一個server開辟一個狀態隊列。bool queue[K] 用來統計失敗次數。每次有壞狀態進隊,計數加一。如果有壞狀態出隊,則計數減一。
b、按照f(Cconn)公式計算出選擇概率。
c、利用rand()%100是否在[0,f(Cconn)]來決定是否選擇該機器。
2. 健康狀態算法。
a、每台機器維持一個一秒鐘內的處理時間T和次數C。
b、當一秒過去以後,將T、C計算為平均處理時間R。
c、每M秒,統計每台機器最近一段時間的平均處理時間, 按照公式select(healthy)算出選擇概率。
d、利用rand()%100是否在[0, select(healthy)*100]來決定是否選擇該機器。
C、流量均分
按照策略選出滿足要求的機器,按照流量均分公式進行流量分配。
分配時按照balance_key+server方式和random()來分配機器, 盡量保證請求落在同一台機器。