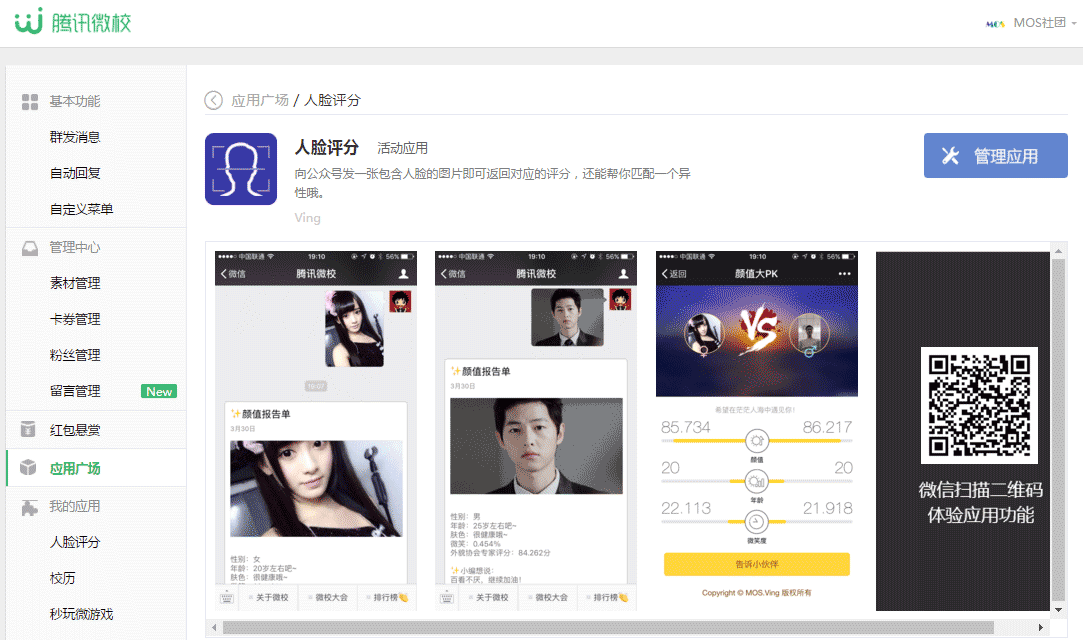
Pattern ModifIErs - 規則表達式的修飾符
下面是當前規則表達式裡可用的修飾. 括號內的名字是那些修飾符的內部 PCRE 名字.
i (PCRE_CASELESS)
如果設置了這個修飾符, 則表達式不區分大小寫.
m (PCRE_MULTILINE)
默認的, PCRE 認為目標字符串值是單行字符串 (即使他確實包含多行). 行開始標記 (^) 只匹配字符串的開始部分, 而行結束標記 ($) 只匹配字符串的尾部,或者一個結束行(除非指定 E 修飾符). 這個和 Perl 裡面一樣.
如果設定了這個修飾符, 行開始和行結束結構分別匹配在目標字符串任何新行的當前位置後面的或者以前的, 和每一個開始和結束一樣. 這個等於 Perl 裡面的 /m 修飾符. 如果目標字符串沒有 "n" 字符, 或者模式裡沒有 ^ 或 $ ,這個修飾符不起作用.
s (PCRE_DOTALL)
如果設置這個修飾符, 模式裡的一個"點"將匹配所有字符, 包括換行. 沒有他, 換行將被排除在外. 這個修飾符等同於 Perl 裡面的 /s 修飾符. 一個相反的類型,例如 [^a] 將總是匹配換行字符,而不管這個修飾符的限制.
x (PCRE_EXTENDED)
如果設置這個修飾符, 模式裡面的空格數句將會被全部忽略,除非用轉義符或者一個字符的內部類型,還有所有字符類型外的未轉義的 # 號之間的也被忽略. 這個等同於 Perl 裡面的 /x 修飾符, 這樣可以復雜的模式裡面加入注釋. 注意,只適用於數據字符. 空格字符將不會在指定的模式字符指定順序中出現。
e
如果設置這個修飾符, preg_replace() 將在替換值裡進行正常的涉及到 \ 的替換, 等同於在 PHP 代碼裡面一樣, 然後用於替換搜索到的字符串.
只在 preg_replace() 裡使用這個修飾符; 其它 PCRE 函數忽略他.
A (PCRE_ANCHORED)
如果設置這個修飾符, 模式被強制為錨(anchored), 也就是說, 他將值匹配搜索字符串的開始. 這個效果可以通過恰當的模式結構自身來實現,那是在 Perl 裡面的唯一途徑.
D (PCRE_DOLLAR_ENDONLY)
如果設置這個修飾符,則模式裡的 $ 修飾符將僅匹配目標字符串裡的尾部. 沒有這個修飾符, $ 字符也匹配新行的尾部 (但是不再新行的前面). 如果設置了 m 修飾符則忽略這個修飾符. 在 Perl 裡面沒有類似的.
S
如果一個模式將被使用多次, 使用長些時間分析他來來提高匹配的速度. 如果使用這個修飾符,則進行額外的分析. 目前, 研究模式僅用於非錨模式,沒有一個固定的開始字符.
U (PCRE_UNGREEDY)
這個修飾符翻轉數量的 "greediness" ,使得默認不被 greedy,但是如果你緊跟問號(?),則可以 greedy. 這個和 Perl 不兼容. 這個也可以通過在模式裡面的(?U) 修飾符得到.
X (PCRE_EXTRA)
這個修飾符打開額外的功能,這些和 Perl 不兼容. 任何模式裡面的後面帶字符但沒有特殊意義的反斜槓將引起錯誤, 從而儲備這些聯合用於將來的擴充. 默認的, 在 Perl 裡面, 反斜槓後面有無意義的字符被當成正常的 literal. 目前還沒有其他的控制特征