本文給大家介紹php截取字符串的常用函數
2. 截取utf8編碼的多字節字符串
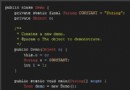
<?php
//截取utf8字符串
function utf8Substr($str, $from, $len)
{
return preg_replace(‘#^(?:[\x00-\x7F]|[\xC0-\xFF][\x80-\xBF]+){0,’.$from.’}’.
‘((?:[\x00-\x7F]|[\xC0-\xFF][\x80-\xBF]+){0,’.$len.’}).*#s’,
‘$1′,$str);
}
?>
3. UTF-8、GB2312都支持的漢字截取函數
<?PHP
/*
Utf-8、gb2312都支持的漢字截取函數
cut_str(字符串, 截取長度, 開始長度, 編碼);
編碼默認為 utf-8
開始長度默認為 0
*/
function cut_str($string, $sublen, $start = 0, $code = ‘UTF-8′)
{
if($code == ‘UTF-8′)
{
$pa = “/[\x01-\x7f]|[\xc2-\xdf][\x80-\xbf]|\xe0[\xa0-\xbf][\x80-\xbf]|[\xe1-\xef][\x80-\xbf][\x80-\xbf]|\xf0[\x90-\xbf][\x80-\xbf][\x80-\xbf]|[\xf1-\xf7][\x80-\xbf][\x80-\xbf][\x80-\xbf]/”;
preg_match_all($pa, $string, $t_string);
if(count($t_string[0]) – $start > $sublen) return join(”, array_slice($t_string[0], $start, $sublen)).”…”;
return join(”, array_slice($t_string[0], $start, $sublen));
}
else
{
$start = $start*2;
$sublen = $sublen*2;
$strlen = strlen($string);
$tmpstr = ”;
for($i=0; $i< $strlen; $i++)
{
if($i>=$start && $i< ($start+$sublen))
{
if(ord(substr($string, $i, 1))>129)
{
$tmpstr.= substr($string, $i, 2);
}
else
{
$tmpstr.= substr($string, $i, 1);
}
}
if(ord(substr($string, $i, 1))>129) $i++;
}
if(strlen($tmpstr)< $strlen ) $tmpstr.= “…”;
return $tmpstr;
}
}
$str = “abcd需要截取的字符串”;
echo cut_str($str, 8, 0, ‘gb2312′);
?>
4. BugFree 的字符截取函數
<?PHP
function sysSubStr($String,$Length,$Append = false)
{
if (strlen($String) < = $Length )
{
return $String;
}
else
{
$I = 0;
while ($I < $Length)
{
$StringTMP = substr($String,$I,1);
if ( ord($StringTMP) >=224 )
{
$StringTMP = substr($String,$I,3);
$I = $I + 3;
}
elseif( ord($StringTMP) >=192 )
{
$StringTMP = substr($String,$I,2);
$I = $I + 2;
}
else
{
$I = $I + 1;
}
$StringLast[] = $StringTMP;
}
$StringLast = implode(“”,$StringLast);
if($Append)
{
$StringLast .= “…”;
}
return $StringLast;
}
}
$String = “book.chinaz.com — 站長書庫、站長教程”;
$Length = “18″;
$Append = false;
echo sysSubStr($String,$Length,$Append);
?>