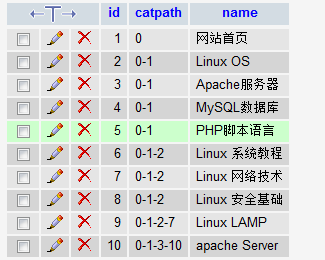
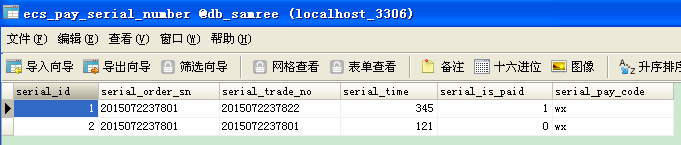
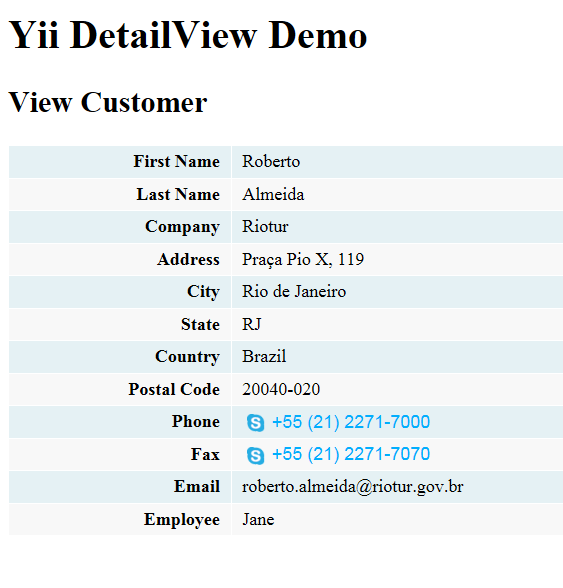
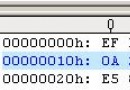
判斷字符串是utf-8 還是gb2312函數
/**
* 判斷字符串是utf-8 還是gb2312
* @param unknown $str
* @param string $default
* @return string
*/
function utf8_gb2312($str, $default = 'gb2312')
{
$str = preg_replace("/[\x01-\x7F]+/", "", $str);
if (empty($str)) return $default;
$preg = array(
"gb2312" => "/^([\xA1-\xF7][\xA0-\xFE])+$/", //正則判斷是否是gb2312
"utf-8" => "/^[\x{4E00}-\x{9FA5}]+$/u", //正則判斷是否是漢字(utf8編碼的條件了),這個范圍實際上已經包含了繁體中文字了
);
if ($default == 'gb2312') {
$option = 'utf-8';
} else {
$option = 'gb2312';
}
if (!preg_match($preg[$default], $str)) {
return $option;
}
$str = @iconv($default, $option, $str);
//不能轉成 $option, 說明原來的不是 $default
if (empty($str)) {
return $option;
}
return $default;
}
utf-8和gb2312自動轉化
/**
* utf-8和gb2312自動轉化
* @param unknown $string
* @param string $outEncoding
* @return unknown|string
*/
function safeEncoding($string,$outEncoding = 'UTF-8')
{
$encoding = "UTF-8";
for($i = 0; $i < strlen ( $string ); $i ++) {
if (ord ( $string {$i} ) < 128)
continue;
if ((ord ( $string {$i} ) & 224) == 224) {
// 第一個字節判斷通過
$char = $string {++ $i};
if ((ord ( $char ) & 128) == 128) {
// 第二個字節判斷通過
$char = $string {++ $i};
if ((ord ( $char ) & 128) == 128) {
$encoding = "UTF-8";
break;
}
}
}
if ((ord ( $string {$i} ) & 192) == 192) {
// 第一個字節判斷通過
$char = $string {++ $i};
if ((ord ( $char ) & 128) == 128) {
// 第二個字節判斷通過
$encoding = "GB2312";
break;
}
}
}
if (strtoupper ( $encoding ) == strtoupper ( $outEncoding ))
return $string;
else
return @iconv ( $encoding, $outEncoding, $string );
}
*