在PHP中有兩套正則表達式函數庫。一套是由PCRE(Perl Compatible Regular Expression)庫提供的。PCRE庫使用和Perl相同的語法規則實現了正則表達式的模式匹配,其使用以“preg_”為前綴命名的函數。另一套是由POSIX(Portable Operation System interface)擴展庫提供的。POSIX擴展的正則表達式由POSIX 1003.2定義,一般使用以“ereg_”為前綴命名的函數。
兩套函數庫的功能相似,執行效率稍有不同。一般而言,實現相同的功能,使用PCRE庫的效率略占優勢。下面詳細介紹其使用方法。
6.3.1 正則表達式的匹配
1.preg_match()
函數原型:int preg_match (string $pattern, string $content [, array $matches])
preg_match
()函數在$content字符串中搜索與$pattern給出的正則表達式相匹配的內容。如果提供了$matches,則將匹配結果放入其
中。$matches[0]將包含與整個模式匹配的文本,$matches[1]將包含第一個捕獲的與括號中的模式單元所匹配的內容,以此類推。該函數只
作一次匹配,最終返回0或1的匹配結果數。代碼6.1給出preg_match()函數的一段代碼示例。
代碼6.1 日期時間的匹配
這是一個簡單動態文本串匹配實例。假設當前系統時間是“2006年8月17日13點25分”,將輸出如下的內容。
匹配的時間是:2006-08-17 01:25 pm
當前日期是:2006-08-17
當前時間是:01:25 pm
2.ereg()和eregi()
ereg()是POSIX擴展庫中正則表達式的匹配函數。eregi()是ereg()函數的忽略大小寫的版
本。二者與preg_match的功能類似,但函數返回的是一個布爾值,表明匹配成功與否。需要說明的是,POSIX擴展庫函數的第一個參數接受的是正則
表達式字符串,即不需要使用分界符。例如,代碼6.2是一個關於文件名安全檢驗的方法。
代碼6.2 文件名的安全檢驗
通常情況下,使用與Perl兼容的正則表達式匹配函數perg_match(),將比使用ereg()或eregi()的速度更快。如果只是查找一個字符串中是否包含某個子字符串,建議使用strstr()或strpos()函數。
3.preg_grep()
函數原型:array preg_grep (string $pattern,
array $input)
preg_grep()函數返回一個數組,其中包括了$input數組中與給定的$pattern模式相匹配的單元。對於輸入數組$input中的每個元素,preg_grep()也只進行一次匹配。代碼6.3給出的示例簡單地說明了preg_grep()函數的使用。
代碼6.3 數組查詢匹配
6.3.2 進行全局正則表達式匹配
1.preg_match_all()
與preg_match()函數類似。如果使用了第三個參數,將把所有可能的匹配結果放入。本函數返回整個模
式匹配的次數(可能為0),如果出錯返回False。下面是一個將文本中的URL鏈接地址轉換為HTML代碼的示例。代碼6.4是
preg_match_all()函數的使用范例。
代碼6.4 將文本中的鏈接地址轉成HTML
2.多行匹配
僅僅使用POSIX下的正則表式函數,很難進行復雜的匹配操作。例如,對整個文件(尤其是多行文本)進行匹配查找。使用ereg()對此進行操作的一個方法是分行處理。代碼6.5的示例演示了ereg()如何將INI文件的參數賦值到數組之中。
代碼6.5 文件內容的多行匹配
提示
這裡只是為了方便說明問題。解析一個*.ini文件,最佳方法是使用函數parse_ini_file()。該函數直接將*.ini文件解析到一個大數組中。
6.3.3 正則表達式的替換
1.ereg_replace()和eregi_replace()
函數原型:string ereg_replace (string $pattern, string $replacement, string
$string)
string eregi_replace (string $pattern, string $replacement, string
$string)
ereg_replace()在$string中搜索模式字符串$pattern,並將所匹配結果替換
為$replacement。當$pattern中包含模式單元(或子模式)時,$replacement中形如“\1”或“$1”的位置將依次被這些子
模式所匹配的內容替換。而“\0”或“$0”是指整個的匹配字符串的內容。需要注意的是,在雙引號中反斜線作為轉義符使用,所以必須使用“\\0”,“ \\1”的形式。
eregi_replace()和ereg_replace()的功能一致,只是前者忽略大小寫。代碼6.6是本函數的應用實例,這段代碼演示了如何對程序源代碼做簡單的清理工作。
代碼6.6 源代碼的清理
2.preg_replace()
函數原型:mixed preg_replace
(mixed $pattern, mixed $replacement, mixed $subject [, int $limit])
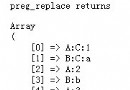
preg_replace較ereg_replace的功能更加強大。其前三個參數均可以使用數組;第四個參數$limit可以設置替換的次數,默認為全部替換。代碼6.7是一個數組替換的應用實例。
代碼6.7 數組替換
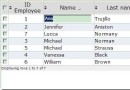
輸出結果如下。
Name: Thomas Ching",
Email:
tom@emailaddress.com
Address: No.5, Wilson St., New York, U.S.A
在preg_replace的正則表達式中可以使用模式修正符“e”。其作用是將匹配結果用作表達式,並且可以進行重新運算。例如:
提示
preg_replace函數使用了Perl兼容正則表達式語法,通常是比ereg_replace更快的替代方案。如果僅對字符串做簡單的替換,可以使用str_replace函數。
6.3.4 正則表達式的拆分
1.split()和spliti()
函數原型:array split
(string $pattern, string $string [, int $limit])
本函數返回一個字符串數組,每個單元為$string經正則表達式$pattern作為邊界分割出的子串。如
果設定了$limit,則返回的數組最多包含$limit個單元。而其中最後一個單元包含了$string中剩余的所有部分。spliti是split的
忽略大小版本。代碼6.8是一個經常用到關於日期的示例。
代碼6.8 日期的拆分
2.preg_split()
本函數與split函數功能一致。代碼6.9是一個查找文章中單詞數量的示例。
代碼6.9 查找文章中單詞數量
提示
preg_split()
函數使用了Perl兼容正則表達式語法,通常是比split()更快的替代方案。使用正則表達式的方法分割字符串,可以使用更廣泛的分隔字符。例如,上面
對日期格式和單詞處理的分析。如果僅用某個特定的字符進行分割,建議使用explode()函數,它不調用正則表達式引擎,因此速度是最快的。