設計您的數據分析,做比簡單原始計數更多的事
對 Web 數據進行有效和多層次的分析是許多面向 Web 企業能夠生存的關鍵因素,數據分析檢驗的設計(和決策)通常是系統管理員和內部應用程序設計人員的工作,而他們可能除了能夠把原始計數制成表格之外,對統計學沒有更多的了解。在本文中,Paul Meagher 向 Web 開發人員傳授了將推論統計學應用到 Web 數據流所需的技能和概念。
動態網站不斷生成大量的數據 — 訪問日志、民意測驗和調查結果、客戶概要信息、訂單及其它,Web 開發人員的工作不僅是創建生成這些數據的應用程序,而且還要開發使這些數據流有意義的應用程序和方法。
通常,對於由管理站點所產生的不斷增長的數據分析需求,Web 開發人員的應對是不夠的。一般而言,除了報告各種描述性統計信息之外,Web 開發人員並沒有其它更好的方法來反映數據流特征。有許多推論統計步驟(根據樣本數據估計總體參數的方法)可以被充分利用,但目前卻沒有應用它們。
例如,Web 訪問統計信息(按當前所編輯的)只不過是以各種方式進行分組的頻率計數。以原始計數和百分比表示民意測驗和調查結果的情況比比皆是。
開發人員用比較淺顯的方法處理數據流的統計分析或許已經足夠了,我們不應期望太多。畢竟,有從事較復雜的數據流分析的專業人士;他們是統計師和受過訓練的分析師。當組織需要的不僅僅是描述性統計時,可以請他們加入。
但另一種應對是承認對推論統計學日益加深的了解正成為 Web 開發人員工作描述的一部分。動態站點正在生成越來越多的數據,事實表明,設法將這些數據變成有用的知識正是 Web 開發人員和系統管理員的責任。
我提倡采取後一種應對;本文旨在幫助 Web 開發人員和系統管理員學習(或重溫,如果知識已遺忘的話)將推論統計學應用到 Web 數據流所需的設計和分析技能。
使 Web 數據與實驗設計相關
將推論統計學應用到 Web 數據流需要的不僅僅是學習作為各種統計檢驗基礎的數學知識。將數據收集過程與實驗設計中的關鍵差別關聯起來的能力同樣很重要:測量尺度是什麼?樣本的代表性如何?總體是什麼?正在檢驗的假設是什麼?
要將推論統計學應用到 Web 數據流,需要先把結果看作是由實驗設計生成的;然後選擇適用於該實驗設計的分析過程。即使您可能認為將 Web 民意測驗和訪問日志數據看作實驗的結果是多此一舉,但這樣做確實很重要。為什麼?
1.這將幫助您選擇適當的統計檢驗方法。
2.這將幫助您從收集的數據中得出適當的結論。
在確定要使用哪些適當的統計檢驗時,實驗設計的一個重要方面是選擇數據收集的衡量尺度。
衡量標准的示例
測量尺度只是指定了一個對所感興趣的現象分配符號、字母或數字的步驟。例如,千克尺度允許您給一個物體分配數字,根據測量儀器的標准化的偏移量指示該物體的重量。
有四種重要的衡量標准:
定比尺度(ratio)— 千克尺度是定比尺度的一個示例 ? 分配給物體屬性的符號具有數字意義。您可以對這些符號執行各種運算(如計算比率),而對於通過使用功能不那麼強大的衡量標准獲得的數值,您不能使用這些運算。
定距尺度(interval)— 在定距尺度中,任意兩個相鄰測量單位之間的距離(也稱為間距)是相等的,但零點是任意的。定距尺度的示例包括對經度和潮汐高度的度量,以及不同年份始末的度量。定距尺度的值可以加減,但乘除則沒有意義。
定序尺度(rank)— 定序尺度可應用於一組有順序的數據,有順序指的是屬於該尺度的值和觀察值可以按順序排列或附帶有評級尺度。常見的示例包括“好惡”民意測驗,其中將數字分配給各個屬性(從 1 = 非常厭惡到 5 = 非常喜歡)。通常,一組有序數據的類別有自然的順序,但尺度上相鄰點之間的差距不必總是相同的。對於有順序的數據,您可以計數和排序,但不能測量。
定類尺度(nominal)— 衡量標准的定類尺度是衡量標准中最弱的一種形式,主要指將項目分配給組或類別。這種測量不帶數量信息,並且不表示對項目進行排序。對定類尺度數據執行的主要數值運算是每一類別中項目的頻率計數。
下表對比了每種衡量標准的特征:
衡量標准尺度 屬性具有絕對的數字含義嗎? 能執行大多數數學運算嗎?
定比尺度 是。 是。
定距尺度 對於定距尺度是這樣;零點是任意的。 加和減。
定序尺度 不是。 計數和排序。
定類尺度 不是。 只能計數。
在本文中,我將主要討論通過使用測量的定類尺度收集的數據,以及適用於定類數據的推論技術。
使用定類尺度
幾乎所有 Web 用戶 — 設計人員、客戶和系統管理員 — 都熟悉定類尺度。Web 民意測驗和訪問日志類似,因為它們常常使用定類尺度作為衡量標准。在 Web 民意測驗中,用戶常常通過請求人們選擇回答選項(如“您偏愛品牌 A、品牌 B,還是品牌 C?”)來衡量人們的偏好。通過對各類回答的頻率進行計數來匯總數據。
類似的,測量網站流量的常用方法是對一個星期內一天之中的每次點擊或訪問都劃分給這一天,然後對每一天出現的點擊或訪問的數目計數。另外,您可以(也確實可以)通過浏覽器類型、操作系統類型和訪問者所在的國家或地區 — 以及任何您想得到的分類尺度 — 對點擊計數。
因為 Web 民意測驗和訪問統計信息都需要對數據歸入某一特定性質類別的次數進行計數,所以可以用相似的無參數統計檢驗(允許您根據分布形狀而不是總體參數作出推論的檢驗)來分析它們。
David Sheskin 在他的 Handbook of Parametric and Non-Parametric Statistical Procedures 一書(第 19 頁, 1997)中,是這樣區分參數檢驗和非參數檢驗的:
本書中將過程分類為參數檢驗和非參數檢驗所使用的區別主要基於被分析數據所代表的測量級別。作為通用規則,評估類別/定類尺度數據和順序/等級-順序數據的推論統計檢驗被歸類為非參數檢驗,而那些評估定距尺度數據或定比尺度數據的檢驗則被歸類為參數檢驗。
當作為參數檢驗基礎的某些假設值得懷疑時,非參數檢驗也很有用;當不滿足參數假設時,非參數檢驗在檢測總體差異時有很大的作用。對於 Web 民意測驗的示例,我使用了非參數分析過程,因為 Web 民意測驗通常使用定類尺度來記錄投票者的偏好。
我並不是在建議 Web 民意測驗和 Web 訪問統計信息應該始終使用定類尺度衡量標准,或者說非參數統計檢驗是唯一可用於分析這類數據的方法。不難設想有(譬如)這樣的民意測驗和調查,它們要求用戶對每個選項提供數值評分(從 1 到 100),對此,參數性的統計檢驗就比較合適。
盡管如此,許多 Web 數據流包括編輯類別計數數據,而且通過定義定距尺度(譬如從 17 到 21)並將每個數據點分配給一個定距尺度(如“年輕人”),可以將這些數據(通過使用功能更強大的衡量標准測量)變成定類尺度數據。頻率數據的普遍存在(已經是 Web 開發人員經驗的一部分),使得專注於非參數統計學成為學習如何將推論技術應用到數據流的良好起點。
為了使本文保持合理的篇幅,我將把對 Web 數據流分析的討論局限於 Web 民意測驗。但是請記住,許多 Web 數據流都可以用定類計數數據表示,而我討論的推論技術將使您能做比報告簡單的計數數據更多的事情。
從抽樣開始
假設您在您的站點 www·NovaScotiaBeerDrinkers.com 上進行每周一次的民意測驗,詢問成員對各種主題的意見。您已經創建了一個民意測驗,詢問成員喜愛的啤酒品牌(在加拿大新斯科捨省(Nova Scotia)有三種知名的啤酒品牌:Keiths、Olands 和 Schooner)。為了使調查盡可能范圍廣泛,您在回答中包括“其它”。
您收到 1,000 條回答,請觀察到表 1 中的結果。(本文顯示的結果只作為演示之用,並不基於任何實際調查。)
表 1. 啤酒民意測驗Keiths Olands Schooner 其它
285(28.50%) 250(25.00%) 215(21.50%) 250(25.00%)
這些數據看上去支持這樣的結論:Keiths 是最受新斯科捨省居民歡迎的品牌。根據這些數字,您能得出這一結論嗎?換句話說,您能根據從樣本獲得的結果對新斯科捨省的啤酒消費者總體作出推論嗎?
許多與樣本收集方式有關的因素會使相對受歡迎程度的推論不正確。可能樣本中包含了過多 Keiths 釀酒廠的雇員;可能您沒有完全預防一個人投多次票的情況,而這個人可能使結果出現偏差;或許被挑選出來投票的人與沒有被挑選出來投票的人不同;或許上網的投票人與不上網的投票人不同。
大多數 Web 民意測驗都存在這些解釋上的困難。當您試圖從樣本統計數據得出有關總體參數的結論時,就會出現這些解釋上的困難。從實驗設計觀點看,在收集數據之前首先要問的一個問題是:能否采取步驟幫助確保樣本能夠代表所研究的總體。
如果對所研究的總體得出結論是您做 Web 民意測驗的動機(而不是為站點訪問者提供的消遣),那麼您應該實現一些技術,以確保一人一票(所以,他們必須用唯一的標識登錄才能投票),並確保隨機選擇投票者樣本(例如,隨機選擇成員的子集,然後給他們發電子郵件,鼓勵他們投票)。
最終,目標是消除(至少減少)各種偏差,它們可能會削弱對所研究總體得出結論的能力。
檢驗假設
假設新斯科捨省啤酒消費者統計樣本沒有發生偏差,您現在能夠得出 Keiths 是最受歡迎品牌這一結論嗎?
要回答這個問題,請考慮一個相關的問題:如果您要獲得另一個新斯科捨省啤酒消費者的樣本,您希望看到完全相同的結果嗎?實際上,您會希望不同樣本中所觀察到的結果有一定的變化。
考慮這個預期的抽樣可變性,您可能懷疑通過隨機抽樣可變性是否比反映所研究總體中的實際差異能更好地說明觀察到的品牌偏好。在統計學術語中,這個抽樣可變性說明被稱為虛假設(null hypothesis)。(虛假設由符號 Ho 表示)在本例中,用公式將它表示成這樣的語句:在作出回答的所有類別中,各種回答的期望數目相同。
Ho:# Keiths = # Olands = # Schooner = # Other
如果您能夠排除虛假設,那麼您在回答 Keiths 是否是最受歡迎品牌這個最初的問題上取得了一些進展。那麼,另一個可接受的假設是在所研究的總體中,各種回答所占比例不同。
這個“先檢驗虛假設”邏輯在民意測驗數據分析中的多個階段都適用。排除這一虛假設,這樣數據就不會完全不同,隨後您可以繼續檢驗一個更具體的虛假設,即 Keiths 和 Schooner,或者 Keiths 與其它所有品牌之間沒有差別。
您繼續檢驗虛假設而不是直接評估另一假設,是因為對於在虛假設條件下人們希望觀察到的事物進行統計建模更容易。接下來,我將演示如何對在虛假設下所期望的事物建模,這樣我就可以將觀察結果與在虛假設條件下所期望的結果加以比較。
對虛假設建模:X 平方分布統計
到目前為止,您已經使用一個報告每種回答選項頻率計數(和百分比)的表匯總了 Web 民意測驗的結果。要檢驗虛假設(表單元頻率之間不存在差別),計算每個表單元與您在虛假設條件下所期望值的總體偏差度量要容易得多。
在這個啤酒歡迎度民意測驗的示例中,在虛假設條件下的期望頻率如下:
期望頻率 = 觀察數目 / 回答選項的數目
期望頻率 = 1000 / 4
期望頻率 = 250
要計算每個單元中回答的內容與期望頻率相差多少的總體度量,您可以將所有的差別總計到一個反映觀察頻率與期望頻率相差多少的總體度量中:(285 - 250) + (250 - 250) + (215 - 250) + (250 - 250)。
如果您這麼做,您會發現期望頻率是 0,因為平均值的偏差的和永遠是 0。要解決這個問題,應當取所有差值的平方(這就是X 平方分布(Chi Square)中平方的由來)。最後,為了使各樣本(這些樣本具有不同的觀察數)的這個值具有可比性(換句話說,使它標准化),將該值除以期望頻率。因此,X 平方分布統計的公式如下所示(“O”表示“觀察頻率”,“E”等於“期望頻率”):
圖 1. X 平方分布統計的公式
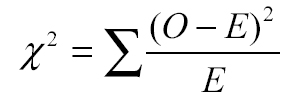
如果計算啤酒歡迎度民意測驗數據的 X 平方分布統計,會得到值 9.80。要檢驗虛假設,需要知道在假設存在隨機抽樣可變性的情況下獲得這麼一個極限值的概率。要得出這一概率,需要理解 X 平方分布的抽樣分布是什麼樣的。
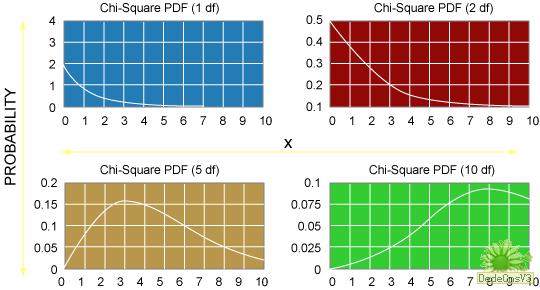
在每幅圖中,橫軸表示所得到的 X 平方分布值大小(圖中所示范圍從 0 到 10)。縱軸顯示各 X 平方分布值的概率(或稱為出現的相對頻率)。 當您研究這些 X 平方分布圖時,請注意,當您在實驗中改變自由度(即 df)時,概率函數的形狀會改變。對於民意測驗數據的示例,自由度是這樣計算的:記下民意測驗中的回答選項(k)的數目,然後用這個值減 1(df = k - 1)。
通常,當您在實驗中增加回答選項的數目時,獲得較大 X 平方分布值的概率會下降。這是因為當增加回答選項時,就增加了方差值的數目 — (觀察值 - 期望值)2 — 您可以求它的總數。因此,當您增加回答選項時,獲得大的 X 平方分布值的統計概率應該增加,而獲得較小 X 平方分布值的概率會減少。這就是為什麼 X 平方分布的抽樣分布的形狀隨著 df 值的不同而變化的原因。
此外,要注意到通常人們對 X 平方分布結果的小數點部分不感興趣,而是對位於所獲得的值右邊曲線的總計部分感興趣。該尾數概率告訴您獲取一個象您觀察到的極限值是可能(如一個大的尾數區域)還是不可能(小的尾數區域)。(實際上,我不使用這些圖來計算尾數概率,因為我可以實現數學函數來返回給定 X 平方分布值的尾數概率。我在本文後面討論的 X 平方分布程序中會采用這種做法。)
要進一步了解這些圖是如何派生出來的,可以看看如何模擬與 df = 2(它表示 k = 3)對應的圖的內容。想象把數字 1、2 和 3 放進帽子裡,搖一搖,選一個數字,然後記錄所選的數字作為一次嘗試。對這個實驗進行 300 次嘗試,然後計算 1、2 和 3 出現的頻率。
每次您做這個實驗時,都應當期望結果有稍微不同的頻率分布,這一分布反映了抽樣的可變性,同時,這個分布又不會真正偏離可能的概率范圍。
下面的 Multinomial 類實現了這一想法。您可以用以下值初始化該類:要做實驗的次數、每個實驗中所做嘗試的次數,以及每次試驗的選項數目。每個實驗的結果記錄在一個名為 Outcomes 的數組中。
清單 1. Multinomial 類的內容
<?php
// Multinomial.php
// Copyright 2003, Paul Meagher
// Distributed under LGPL
class Multinomial {
var $NExps;
var $NTrials;
var $NOptions;
var $Outcomes = array();
function Multinomial($NExps, $NTrials, $NOptions) {
$this->NExps = $NExps;
$this->NTrials = $NTrials;
$this->NOptions = $NOptions;
for ($i=0; $i < $this->NExps; $i++) {
$this->Outcomes[$i] = $this->runExperiment();
}
}
function runExperiment() {
$Outcome = array();
for ($i = 0; $i < $this->NExps; $i++){
$choice = rand(1,$this->NOptions);
$Outcome[$choice]++;
}
return $Outcome;
}
}
?>
請注意,runExperiment 方法是該腳本中非常重要的一部分,它保證在每次實驗中所做出的選擇是隨機的,並且跟蹤到目前為止在模擬實驗中做出了哪些選擇。
為了找到 X 平方分布統計的抽樣分布,只需獲取每次實驗的結果,並且計算該結果的 X 平方分布統計。由於隨機抽樣的可變性,因此這個 X 平方分布統計會隨實驗的不同而不同。
下面的腳本將每次實驗獲得的 X 平方分布統計寫到一個輸出文件以便稍後用圖表表示。
清單 2. 將獲得的 X 平方分布統計寫到輸出文件
<?php
// simulate.php
// Copyright 2003, Paul Meagher
// Distributed under LGPL
// Set time limit to 0 so script doesn't time out
set_time_limit(0);
require_once "../init.php";
require PHP_MATH . "chi/Multinomial.php";
require PHP_MATH . "chi/ChiSquare1D.php";
// Initialization parameters
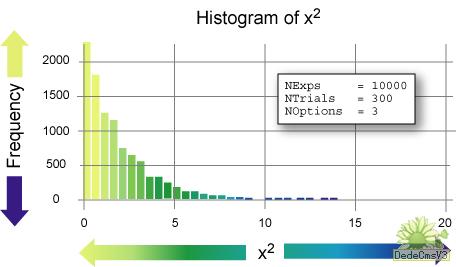
$NExps = 10000;
$NTrials = 300;
$NOptions = 3;
$multi = new Multinomial($NExps, $NTrials, $NOptions);
$output = fopen("./data.txt","w") OR die("file won't open");
for ($i=0; $i<$NExps; $i++) {
// For each multinomial experiment, do chi square analysis
$chi = new ChiSquare1D($multi->Outcomes[$i]);
// Load obtained chi square value into sampling distribution array
$distribution[$i] = $chi->ChiSqObt;
// Write obtained chi square value to file
fputs($output, $distribution[$i]."\n");
}
fclose ($output);
?>
為了使運行該實驗所期望獲得的結果可視化,對我來說,最簡單的方法就是將 data.txt 文件裝入開放源碼統計包 R,運行 histogram 命令,並且在圖形編輯器中編輯該圖表,如下所示:
x = scan("data.txt")
hist(x, 50)
正如您可以看到的,這些 X 平方分布值的直方圖與上面表示的 df = 2 的連續 X 平方分布的分布近似。
圖 3. 與 df=2 的連續分布近似的值