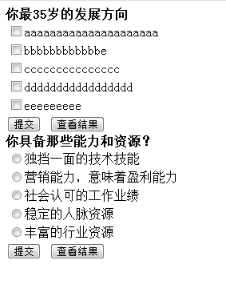
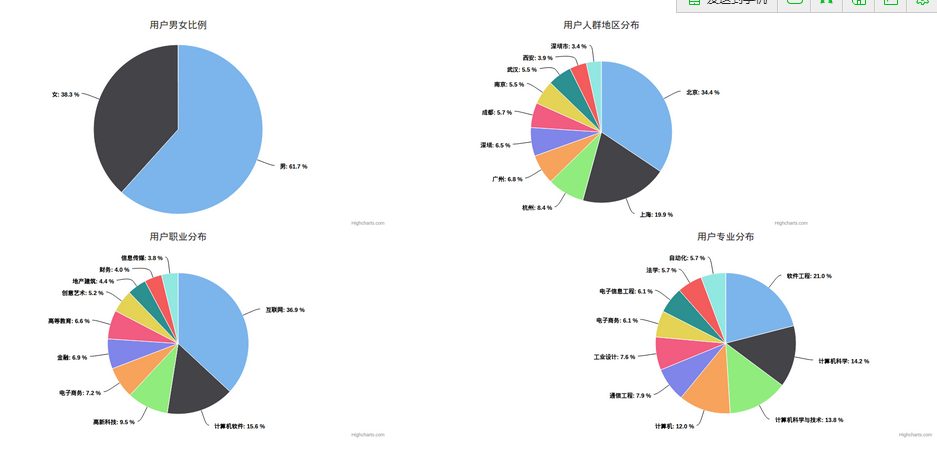
這次抓取了110萬的用戶數據,數據分析結果如下:
開發前的准備
安裝Linux系統(Ubuntu14.04),在VMWare虛擬機下安裝一個Ubuntu;
安裝PHP5.6或以上版本;
安裝curl、pcntl擴展。
使用PHP的curl擴展抓取頁面數據
PHP的curl擴展是PHP支持的允許你與各種服務器使用各種類型的協議進行連接和通信的庫。
本程序是抓取知乎的用戶數據,要能訪問用戶個人頁面,需要用戶登錄後的才能訪問。當我們在浏覽器的頁面中點擊一個用戶頭像鏈接進入用戶個人中心頁面的時候,之所以能夠看到用戶的信息,是因為在點擊鏈接的時候,浏覽器幫你將本地的cookie帶上一齊提交到新的頁面,所以你就能進入到用戶的個人中心頁面。因此實現訪問個人頁面之前需要先獲得用戶的cookie信息,然後在每次curl請求的時候帶上cookie信息。在獲取cookie信息方面,我是用了自己的cookie,在頁面中可以看到自己的cookie信息:
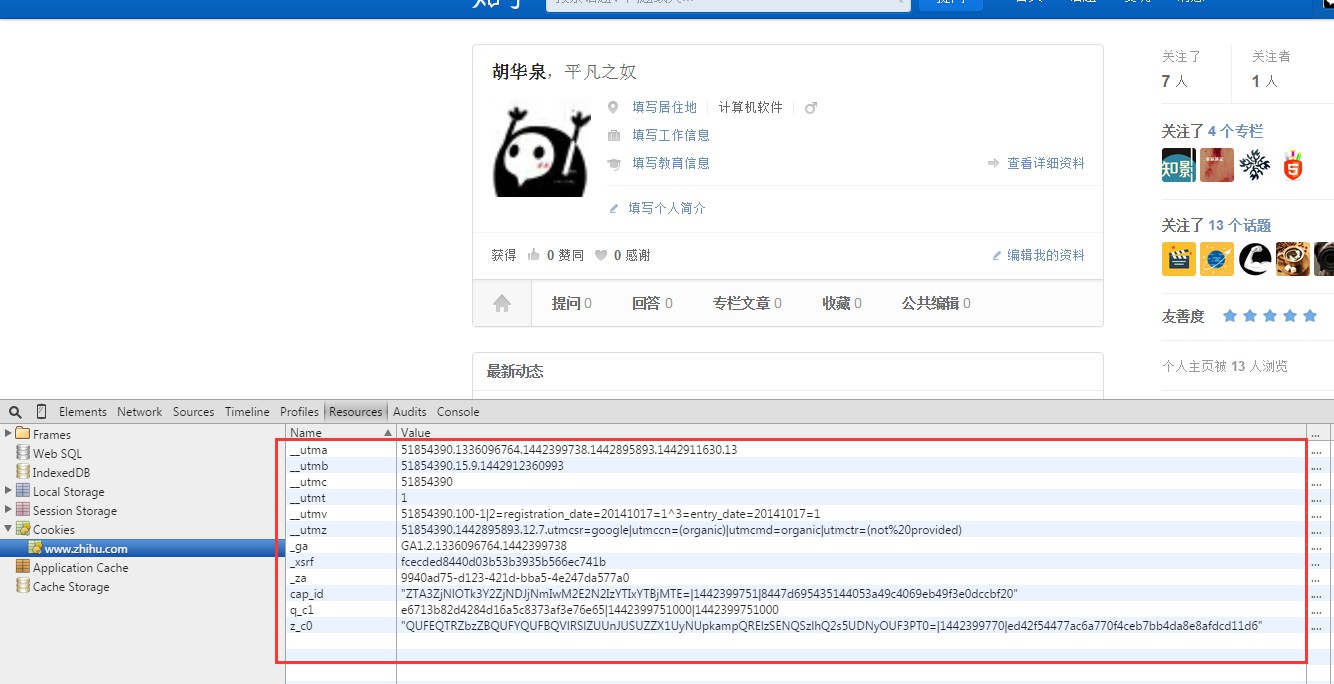
一個個地復制,以"__utma=?;__utmb=?;"這樣的形式組成一個cookie字符串。接下來就可以使用該cookie字符串來發送請求。
初始的示例:
$url = 'http://www.zhihu.com/people/mora-hu/about'; //此處mora-hu代表用戶ID $ch = curl_init($url); //初始化會話 curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_COOKIE, $this->config_arr['user_cookie']); //設置請求COOKIE curl_setopt($ch, CURLOPT_USERAGENT, $_SERVER['HTTP_USER_AGENT']); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //將curl_exec()獲取的信息以文件流的形式返回,而不是直接輸出。 curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); $result = curl_exec($ch); return $result; //抓取的結果
運行上面的代碼可以獲得mora-hu用戶的個人中心頁面。利用該結果再使用正則表達式對頁面進行處理,就能獲取到姓名,性別等所需要抓取的信息。
圖片防盜鏈
在對返回結果進行正則處理後輸出個人信息的時候,發現在頁面中輸出用戶頭像時無法打開。經過查閱資料得知,是因為知乎對圖片做了防盜鏈處理。解決方案就是請求圖片的時候在請求頭裡偽造一個referer。
在使用正則表達式獲取到圖片的鏈接之後,再發一次請求,這時候帶上圖片請求的來源,說明該請求來自知乎網站的轉發。具體例子如下:
function getImg($url, $u_id)
{
if (file_exists('./images/' . $u_id . ".jpg"))
{
return "images/$u_id" . '.jpg';
}
if (empty($url))
{
return '';
}
$context_options = array(
'http' =>
array(
'header' => "Referer:http://www.zhihu.com"//帶上referer參數
)
);
$context = stream_context_create($context_options);
$img = file_get_contents('http:' . $url, FALSE, $context);
file_put_contents('./images/' . $u_id . ".jpg", $img);
return "images/$u_id" . '.jpg';
}
抓取了自己的個人信息後,就需要再訪問用戶的關注者和關注了的用戶列表獲取更多的用戶信息。然後一層一層地訪問。可以看到,在個人中心頁面裡,有兩個鏈接如下:
這裡有兩個鏈接,一個是關注了,另一個是關注者,以“關注了”的鏈接為例。用正則匹配去匹配到相應的鏈接,得到url之後用curl帶上cookie再發一次請求。抓取到用戶關注了的用於列表頁之後,可以得到下面的頁面:
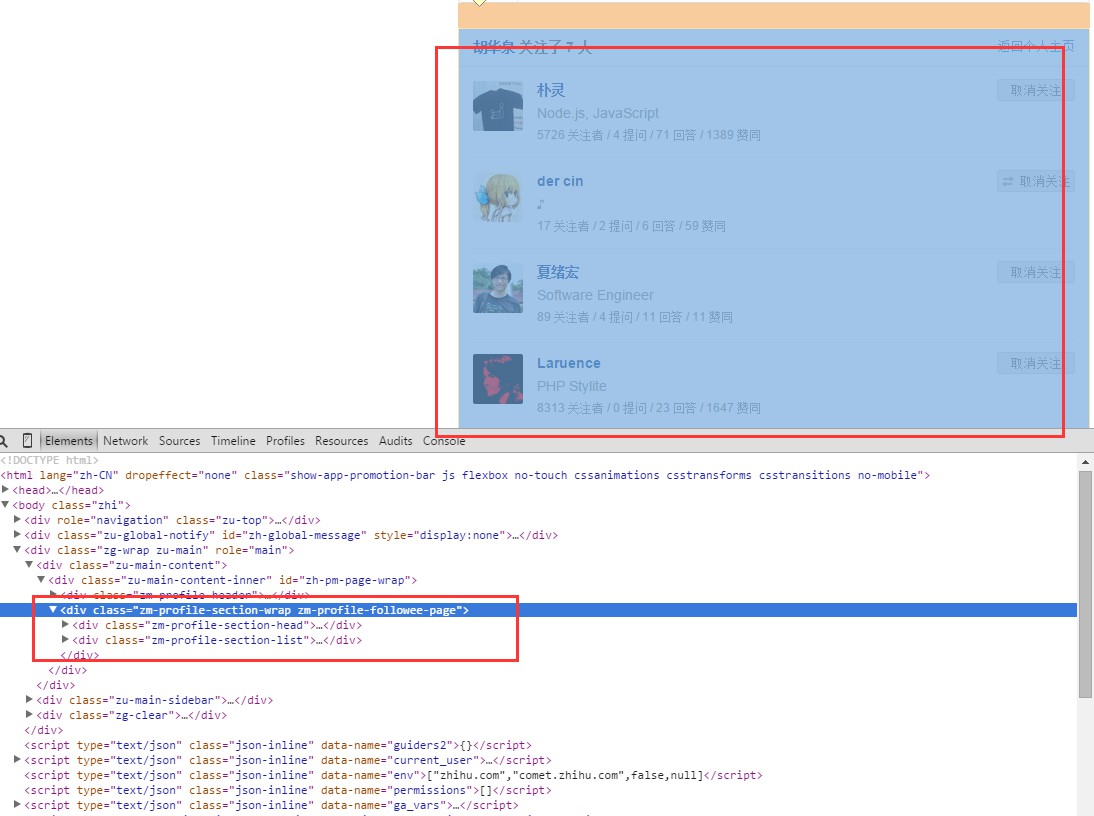
分析頁面的html結構,因為只要得到用戶的信息,所以只需要框住的這一塊的div內容,用戶名都在這裡面。可以看到,用戶關注了的頁面的url是:

不同的用戶的這個url幾乎是一樣的,不同的地方就在於用戶名那裡。用正則匹配拿到用戶名列表,一個一個地拼url,然後再逐個發請求(當然,一個一個是比較慢的,下面有解決方案,這個稍後會說到)。進入到新用戶的頁面之後,再重復上面的步驟,就這樣不斷循環,直到達到你所要的數據量。
Linux統計文件數量
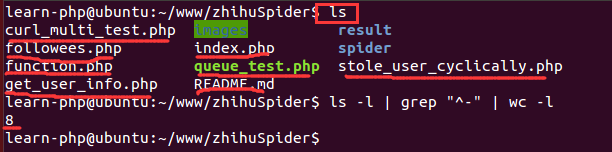
腳本跑了一段時間後,需要看看究竟獲取了多少圖片,當數據量比較大的時候,打開文件夾查看圖片數量就有點慢。腳本是在Linux環境下運行的,因此可以使用Linux的命令來統計文件數量:
復制代碼 代碼如下:
ls -l | grep "^-" | wc -l
其中, ls -l 是長列表輸出該目錄下的文件信息(這裡的文件可以是目錄、鏈接、設備文件等); grep "^-" 過濾長列表輸出信息, "^-" 只保留一般文件,如果只保留目錄是 "^d" ; wc -l 是統計輸出信息的行數。下面是一個運行示例:
插入MySQL時重復數據的處理
程序運行了一段時間後,發現有很多用戶的數據是重復的,因此需要在插入重復用戶數據的時候做處理。處理方案如下:
1)插入數據庫之前檢查數據是否已經存在數據庫;
2)添加唯一索引,插入時使用 INSERT INTO ... ON DUPLICATE KEY UPDATE...
3)添加唯一索引,插入時使用 INSERT INGNORE INTO...
4)添加唯一索引,插入時使用 REPLACE INTO...
使用curl_multi實現多線程抓取頁面
剛開始單進程而且單個curl去抓取數據,速度很慢,掛機爬了一個晚上只能抓到2W的數據,於是便想到能不能在進入新的用戶頁面發curl請求的時候一次性請求多個用戶,後來發現了curl_multi這個好東西。curl_multi這類函數可以實現同時請求多個url,而不是一個個請求,這類似於linux系統中一個進程開多條線程執行的功能。下面是使用curl_multi實現多線程爬蟲的示例:
$mh = curl_multi_init(); //返回一個新cURL批處理句柄
for ($i = ; $i < $max_size; $i++)
{
$ch = curl_init(); //初始化單個cURL會話
curl_setopt($ch, CURLOPT_HEADER, );
curl_setopt($ch, CURLOPT_URL, 'http://www.zhihu.com/people/' . $user_list[$i] . '/about');
curl_setopt($ch, CURLOPT_COOKIE, self::$user_cookie);
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/. (Windows NT .; WOW) AppleWebKit/. (KHTML, like Gecko) Chrome/... Safari/.');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, );
$requestMap[$i] = $ch;
curl_multi_add_handle($mh, $ch); //向curl批處理會話中添加單獨的curl句柄
}
$user_arr = array();
do {
//運行當前 cURL 句柄的子連接
while (($cme = curl_multi_exec($mh, $active)) == CURLM_CALL_MULTI_PERFORM);
if ($cme != CURLM_OK) {break;}
//獲取當前解析的cURL的相關傳輸信息
while ($done = curl_multi_info_read($mh))
{
$info = curl_getinfo($done['handle']);
$tmp_result = curl_multi_getcontent($done['handle']);
$error = curl_error($done['handle']);
$user_arr[] = array_values(getUserInfo($tmp_result));
//保證同時有$max_size個請求在處理
if ($i < sizeof($user_list) && isset($user_list[$i]) && $i < count($user_list))
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_HEADER, );
curl_setopt($ch, CURLOPT_URL, 'http://www.zhihu.com/people/' . $user_list[$i] . '/about');
curl_setopt($ch, CURLOPT_COOKIE, self::$user_cookie);
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/. (Windows NT .; WOW) AppleWebKit/. (KHTML, like Gecko) Chrome/... Safari/.');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, );
$requestMap[$i] = $ch;
curl_multi_add_handle($mh, $ch);
$i++;
}
curl_multi_remove_handle($mh, $done['handle']);
}
if ($active)
curl_multi_select($mh, );
} while ($active);
curl_multi_close($mh);
return $user_arr;
HTTP 429 Too Many Requests
使用curl_multi函數可以同時發多個請求,但是在執行過程中使同時發200個請求的時候,發現很多請求無法返回了,即發現了丟包的情況。進一步分析,使用 curl_getinfo 函數打印每個請求句柄信息,該函數返回一個包含HTTP response信息的關聯數組,其中有一個字段是http_code,表示請求返回的HTTP狀態碼。看到有很多個請求的http_code都是429,這個返回碼的意思是發送太多請求了。我猜是知乎做了防爬蟲的防護,於是我就拿其他的網站來做測試,發現一次性發200個請求時沒問題的,證明了我的猜測,知乎在這方面做了防護,即一次性的請求數量是有限制的。於是我不斷地減少請求數量,發現在5的時候就沒有丟包情況了。說明在這個程序裡一次性最多只能發5個請求,雖然不多,但這也是一次小提升了。
使用Redis保存已經訪問過的用戶
抓取用戶的過程中,發現有些用戶是已經訪問過的,而且他的關注者和關注了的用戶都已經獲取過了,雖然在數據庫的層面做了重復數據的處理,但是程序還是會使用curl發請求,這樣重復的發送請求就有很多重復的網絡開銷。還有一個就是待抓取的用戶需要暫時保存在一個地方以便下一次執行,剛開始是放到數組裡面,後來發現要在程序裡添加多進程,在多進程編程裡,子進程會共享程序代碼、函數庫,但是進程使用的變量與其他進程所使用的截然不同。不同進程之間的變量是分離的,不能被其他進程讀取,所以是不能使用數組的。因此就想到了使用Redis緩存來保存已經處理好的用戶以及待抓取的用戶。這樣每次執行完的時候都把用戶push到一個already_request_queue隊列中,把待抓取的用戶(即每個用戶的關注者和關注了的用戶列表)push到request_queue裡面,然後每次執行前都從request_queue裡pop一個用戶,然後判斷是否在already_request_queue裡面,如果在,則進行下一個,否則就繼續執行。
在PHP中使用redis示例:
<?php
$redis = new Redis();
$redis->connect('127.0.0.1', '6379');
$redis->set('tmp', 'value');
if ($redis->exists('tmp'))
{
echo $redis->get('tmp') . "\n";
}
使用PHP的pcntl擴展實現多進程
改用了curl_multi函數實現多線程抓取用戶信息之後,程序運行了一個晚上,最終得到的數據有10W。還不能達到自己的理想目標,於是便繼續優化,後來發現php裡面有一個pcntl擴展可以實現多進程編程。下面是多編程編程的示例:
//PHP多進程demo
//fork10個進程
for ($i = 0; $i < 10; $i++) {
$pid = pcntl_fork();
if ($pid == -1) {
echo "Could not fork!\n";
exit(1);
}
if (!$pid) {
echo "child process $i running\n";
//子進程執行完畢之後就退出,以免繼續fork出新的子進程
exit($i);
}
}
//等待子進程執行完畢,避免出現僵屍進程
while (pcntl_waitpid(0, $status) != -1) {
$status = pcntl_wexitstatus($status);
echo "Child $status completed\n";
}
在Linux下查看系統的cpu信息
實現了多進程編程之後,就想著多開幾條進程不斷地抓取用戶的數據,後來開了8調進程跑了一個晚上後發現只能拿到20W的數據,沒有多大的提升。於是查閱資料發現,根據系統優化的CPU性能調優,程序的最大進程數不能隨便給的,要根據CPU的核數和來給,最大進程數最好是cpu核數的2倍。因此需要查看cpu的信息來看看cpu的核數。在Linux下查看cpu的信息的命令:
復制代碼 代碼如下:
cat /proc/cpuinfo
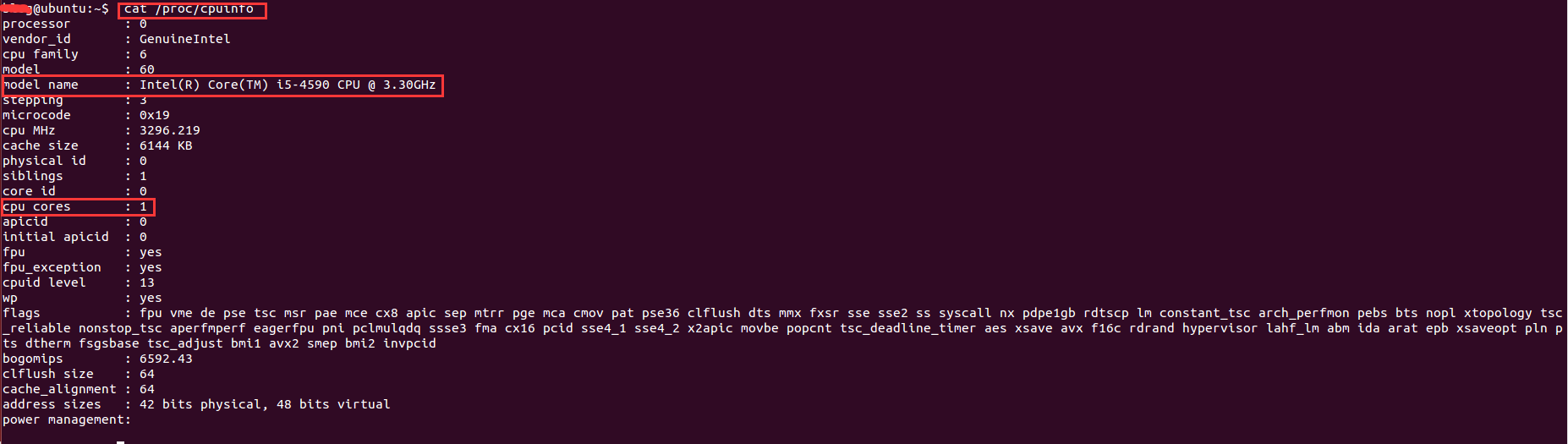
其中,model name表示cpu類型信息,cpu cores表示cpu核數。這裡的核數是1,因為是在虛擬機下運行,分配到的cpu核數比較少,因此只能開2條進程。最終的結果是,用了一個周末就抓取了110萬的用戶數據。
多進程編程中Redis和MySQL連接問題
在多進程條件下,程序運行了一段時間後,發現數據不能插入到數據庫,會報mysql too many connections的錯誤,redis也是如此。
下面這段代碼會執行失敗:
<?php
for ($i = 0; $i < 10; $i++) {
$pid = pcntl_fork();
if ($pid == -1) {
echo "Could not fork!\n";
exit(1);
}
if (!$pid) {
$redis = PRedis::getInstance();
// do something
exit;
}
}
根本原因是在各個子進程創建時,就已經繼承了父進程一份完全一樣的拷貝。對象可以拷貝,但是已創建的連接不能被拷貝成多個,由此產生的結果,就是各個進程都使用同一個redis連接,各干各的事,最終產生莫名其妙的沖突。
解決方法:
程序不能完全保證在fork進程之前,父進程不會創建redis連接實例。因此,要解決這個問題只能靠子進程本身了。試想一下,如果在子進程中獲取的實例只與當前進程相關,那麼這個問題就不存在了。於是解決方案就是稍微改造一下redis類實例化的靜態方式,與當前進程ID綁定起來。
改造後的代碼如下:
<?php
public static function getInstance() {
static $instances = array();
$key = getmypid();//獲取當前進程ID
if ($empty($instances[$key])) {
$inctances[$key] = new self();
}
return $instances[$key];
}
PHP統計腳本執行時間
因為想知道每個進程花費的時間是多少,因此寫個函數統計腳本執行時間:
function microtime_float()
{
list($u_sec, $sec) = explode(' ', microtime());
return (floatval($u_sec) + floatval($sec));
}
$start_time = microtime_float();
//do something
usleep(100);
$end_time = microtime_float();
$total_time = $end_time - $start_time;
$time_cost = sprintf("%.10f", $total_time);
echo "program cost total " . $time_cost . "s\n";