昨天做一個項目,其中有一個需求是每一張圖片對應一小段文字對圖片的說明,普通的做法是新建一個表然後把圖片名與說明文字都記錄到數據庫內。仔細考慮後感覺這個應用不要數據庫也能完成,我實現的方案是把說明文字URLENCODE後當做文件名,這樣當我讀取文件的時候再把文件名URLDECODE就可以後驅圖片的文字說明了。
可是通過浏覽器訪問圖片時卻提示找不到文件,如有一張圖片的說明文字為“瓊台博客”,URLENCODE後生成的文件名如下
復制代碼 代碼如下:
%E7%90%BC%E5%8F%B0%E5%8D%9A%E5%AE%A2.jpg
於是我通過浏覽器訪問圖片,提示找不到
仔細看了一下,發現浏覽器訪問的時候自動把文件名給轉回中文了
火狐
chrome
IE
Safari
IE與Safari從地址欄上沒有看出轉為漢字,但也同樣都提示找不到文件。但我感覺應該是它請求的時候也都自動轉了,只不過地址欄上的沒有顯示轉換後的。從Nginx的訪問記錄看訪問圖片時的請求情況
復制代碼 代碼如下:
192.168.6.30 - - [12/Oct/2012:10:09:44 +0800] "GET /%E7%90%BC%E5%8F%B0%E5%8D%9A%E5%AE%A2.jpg HTTP/1.1" 404 199 "-" "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)"
請求URL處理沒發現什麼異常,最後通過反復研究編碼後的文件名,發現都是由百分號與字母數字組成,我感覺應該是浏覽器在遇到百分號時可能會做些其它轉換處理了,所以導致浏覽器訪問URLENCODE後的文件提示找不到。
於是我把所有URLENCODE後的文件名裡的百分號都用下劃線替換
復制代碼 代碼如下:
%E7%90%BC%E5%8F%B0%E5%8D%9A%E5%AE%A2.jpg
替換為
復制代碼 代碼如下:
_E7_90_BC_E5_8F_B0_E5_8D_9A_E5_AE_A2.jpg
重新使用浏覽器訪問,問題解決
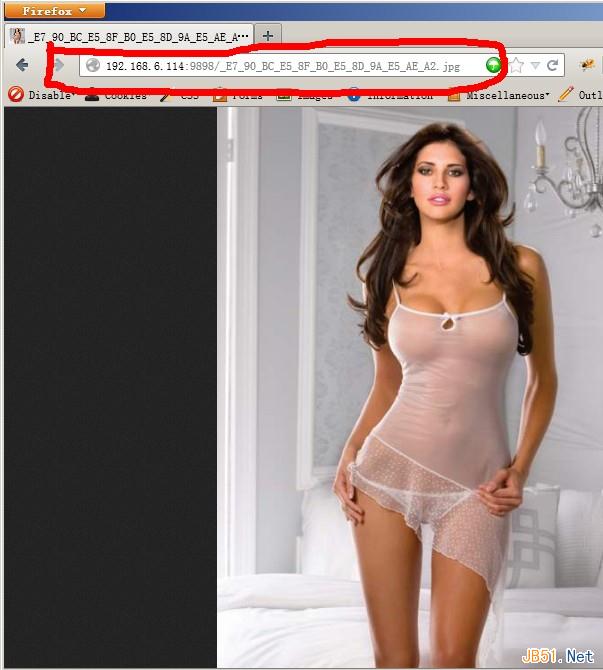
如要獲取圖片的文字說明,直接把文件名的“_”替換回"%”再使用URLDECODE即可。
最後需要注意的是,Linux下文件名跟Win系統一樣都有長度限制,目前最常用的格式為ext3,這中格式允許255個字符長度,扣除大約5個作為拓展名後大約剩余250個長度純文件名,而一個漢字經過URLENCODE後的長度為9個,因此最大可以編碼27個漢字做為文件名。
雖然這種方式存儲的漢字比較少,但可以利用一些加密方法獲得較短的一串密文,再把這段密文URLENCODE即可,具體實現方式我就不一一舉例,動手做做思考一下吧!