無論你要構建自己的論壇,在你的網站上發布消息還是書寫自己的CMS程序,你都會遇到要在數據庫中存儲層次數據的情況。同時,除非你使用一種像XML的數據庫,否則關系數據庫中的表都不是層次結構的,他們只是一個平坦的列表。所以你必須找到一種把層次數據庫轉化的方法。
存儲樹形結構是一個很常見的問題,他有好幾種解決方案。主要有兩種方法:鄰接列表模型和改進前序遍歷樹算法
在本文中,我們將探討這兩種保存層次數據的方法。我將舉一個在線食品店樹形圖的例子。這個食品店通過類別、顏色和品種來組織食品。樹形圖如下:
 本文包含了一些代碼的例子來演示如何保存和獲取數據。我選擇PHP來寫例子,因為我常用這個語言,而且很多人也都使用或者知道這個語言。你可以很方便地把它們翻譯成你自己用的語言。
本文包含了一些代碼的例子來演示如何保存和獲取數據。我選擇PHP來寫例子,因為我常用這個語言,而且很多人也都使用或者知道這個語言。你可以很方便地把它們翻譯成你自己用的語言。
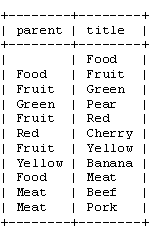
如你所見,對每個節點保存一個“父”節點。我們可以看到“Pear”是“Green”的一個子節點,而後者又是“Fruit”的子節點,如此類推。 根節點,“Food”,則他的父節點沒有值。為了簡單,我只用了“title”值來標識每個節點。當然,在實際的數據庫中,你要使用數字的ID。
顯示樹
現在我們已經把樹放入數據庫中了,得寫一個顯示函數了。這個函數將從根節點開始——沒有父節點的節點——同時要顯示這個節點所有的子節點。對於這些子節點,函數也要獲取並顯示這個子節點的子節點。然後,對於他們的子節點,函數還要再顯示所有的子節點,然後依次類推。
也許你已經注意到了,這種函數的描述,有一種普遍的模式。我們可以簡單地只寫一個函數,用來獲得特定節點的子節點。這個函數然後要對每個子節點調用自身來再次顯示他們的子節點。這就是“遞歸”機制,因此稱這種方法叫“遞歸方法”。
 要實現整個樹,我們只要調用函數時用一個空字符串作為 $parent 和 $level = 0: display_children('',0); 函數返回了我們的食品店的樹狀圖如下:
要實現整個樹,我們只要調用函數時用一個空字符串作為 $parent 和 $level = 0: display_children('',0); 函數返回了我們的食品店的樹狀圖如下:
Food
Fruit
Red
Cherry
Yellow
Banana
Meat
Beef
Pork
注意如果你只想看一個子樹,你可以告訴函數從另一個節點開始。例如,要顯示“Fruit”子樹,你只要display_children('Fruit',0);
The Path to a Node節點的路徑
利用差不多的函數,我們也可以查詢某個節點的路徑如果你只知道這個節點的名字或者ID。例如,“Cherry”的路徑是“Food”> “Fruit”>“Red”。要獲得這個路徑,我們的函數要獲得這個路徑,這個函數必須從最深的層次開始:“Cheery”。但後查找這個節點的父 節點,並添加到路徑中。在我們的例子中,這個父節點是“Red”。如果我們知道“Red”是“Cherry”的父節點。

這個函數現在返回了指定節點的路徑。他把路徑作為數組返回,這樣我們可以使用print_r(get_path('Cherry')); 來顯示,其結果是:
Array
(
[0] => Food
[1] => Fruit
[2] => Red)
不足
正如我們所見,這確實是一個很好的方法。他很容易理解,同時代碼也很簡單。但是鄰接列表模型的缺點在哪裡呢?在大多數編程語言中,他運行很慢,效率很差。這主要是“遞歸”造成的。我們每次查詢節點都要訪問數據庫。
每次數據庫查詢都要花費一些時間,這讓函數處理龐大的樹時會十分慢。
造成這個函數不是太快的第二個原因可能是你使用的語言。不像Lisp這類語言,大多數語言不是針對遞歸函數設計的。對於每個節點,函數都要調用他自 己,產生新的實例。這樣,對於一個4層的樹,你可能同時要運行4個函數副本。對於每個函數都要占用一塊內存並且需要一定的時間初始化,這樣處理大樹時遞歸 就很慢了。
改進前序遍歷樹我們先把樹按照水平方式擺開。從根節點開始(“Food”),然後他的左邊寫上1。然後按照樹的順序(從上到下)給“Fruit”的左邊寫上2。這 樣,你沿著樹的邊界走啊走(這就是“遍歷”),然後同時在每個節點的左邊和右邊寫上數字。最後,我們回到了根節點“Food”在右邊寫上18。下面是標上 了數字的樹,同時把遍歷的順序用箭頭標出來了。
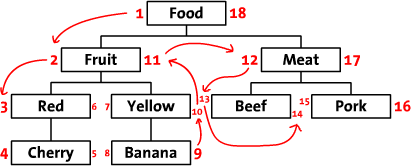
我們稱這些數字為左值和右值(如,“Food”的左值是1,右值是18)。正如你所見,這些數字按時了每個節點之間的關系。因為“Red”有3和6 兩個值,所以,它是有擁有1-18值的“Food”節點的後續。同樣的,我們可以推斷所有左值大於2並且右值小於11的節點,都是有2-11的 “Food”節點的後續。這樣,樹的結構就通過左值和右值儲存下來了。這種數遍整棵樹算節點的方法叫做“改進前序遍歷樹”算法。
在繼續前,我們先看看我們的表格裡的這些值:
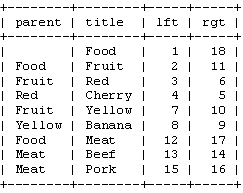
注意單詞“left”和“right”在SQL中有特殊的含義。因此,我們只能用“lft”和“rgt”來表示這兩個列。(譯注——其實Mysql 中可以用“`”來表示,如“`left`”,MSSQL中可以用“[]”括出,如“[left]”,這樣就不會和關鍵詞沖突了。)同樣注意這裡我們已經不需要“parent”列了。我們只需要使用lft和rgt就可以存儲樹的結構。
獲取樹
如果你要通過左值和右值來顯示這個樹的話,你要首先標識出你要獲取的那些節點。例如,如果你想獲得“Fruit”子樹,你要選擇那些左值在2到11的節點。用SQL語句表達:
SELECT * FROM tree WHERE lft BETWEEN 2 AND 11;
這個會返回:
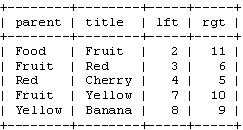
好吧,現在整個樹都在一個查詢中了。現在就要像前面的遞歸函數那樣顯示這個樹,我們要加入一個ORDER BY子句在這個查詢中。如果你從表中添加和刪除行,你的表可能就順序不對了,我們因此需要按照他們的左值來進行排序。
SELECT * FROM tree WHERE lft BETWEEN 2 AND 11 ORDER BY lft ASC;
就只剩下縮進的問題了。
要顯示樹狀結構,子節點應該比他們的父節點稍微縮進一些。我們可以通過保存一個右值的一個棧。每次你從一個節點的子節點開始時,你把這個節點的右值 添加到棧中。你也知道子節點的右值都比父節點的右值小,這樣通過比較當前節點和棧中的前一個節點的右值,你可以判斷你是不是在顯示這個父節點的子節點。當 你顯示完這個節點,你就要把他的右值從棧中刪除。要獲得當前節點的層數,只要數一下棧中的元素。

如果運行這段代碼,你可以獲得和上一部分討論的遞歸函數一樣的結果。而這個函數可能會更快一點:他不采用遞歸而且只是用了兩個查詢
節點的路徑
有了新的算法,我們還要另找一種新的方法來獲得指定節點的路徑。這樣,我們就需要這個節點的祖先的一個列表。
由於新的表結構,這不需要花太多功夫。你可以看一下,例如,4-5的“Cherry”節點,你會發現祖先的左值都小於4,同時右值都大於5。這樣,我們就可以使用下面這個查詢:
SELECT title FROM tree WHERE lft < 4 AND rgt > 5 ORDER BY lft ASC;
注意,就像前面的查詢一樣,我們必須使用一個ORDER BY子句來對節點排序。這個查詢將返回:
+-------+
| title |
+-------+
| Food |
| Fruit |
| Red |
+-------+
我們現在只要把各行連起來,就可以得到“Cherry”的路徑了。
有多少個後續節點?How Many Descendants
如果你給我一個節點的左值和右值,我就可以告訴你他有多少個後續節點,只要利用一點點數學知識。
因為每個後續節點依次會對這個節點的右值增加2,所以後續節點的數量可以這樣計算:
descendants = (right – left - 1) / 2
利用這個簡單的公式,我可以立刻告訴你2-11的“Fruit”節點有4個後續節點,8-9的“Banana”節點只是1個子節點,而不是父節點。
自動化樹遍歷
現在你對這個表做一些事情,我們應該學習如何自動的建立表了。這是一個不錯的練習,首先用一個小的樹,我們也需要一個腳本來幫我們完成對節點的計數。
讓我們先寫一個腳本用來把一個鄰接列表轉換成前序遍歷樹表格。

這是一個遞歸函數。你要從rebuild_tree('Food',1); 開始,這個函數就會獲取所有的“Food”節點的子節點。
如果沒有子節點,他就直接設置它的左值和右值。左值已經給出了,1,右值則是左值加1。如果有子節點,函數重復並且返回最後一個右值。這個右值用來作為“Food”的右值。
遞歸讓這個函數有點復雜難於理解。然而,這個函數確實得到了同樣的結果。他沿著樹走,添加每一個他看見的節點。你運行了這個函數之後,你會發現左值和右值和預期的是一樣的(一個快速檢驗的方法:根節點的右值應該是節點數量的兩倍)。
添加一個節點
我們如何給這棵樹添加一個節點?有兩種方式:在表中保留“parent”列並且重新運行rebuild_tree() 函數——一個很簡單但卻不是很優雅的函數;或者你可以更新所有新節點右邊的節點的左值和右值。
第一個想法比較簡單。你使用鄰接列表方法來更新,同時使用改進前序遍歷樹來查詢。如果你想添加一個新的節點,你只需要把節點插入表格,並且設置好parent列。然後,你只需要重新運行rebuild_tree() 函數。這做起來很簡單,但是對大的樹效率不高。
第二種添加和刪除節點的方法是更新新節點右邊的所有節點。讓我們看一下例子。我們要添加一種新的水果——“Strawberry”,作為“Red” 的最後一個子節點。首先,我們要騰出一個空間。“Red”的右值要從6變成8,7-10的“Yellow”節點要變成9-12,如此類推。更新“Red” 節點意味著我們要把所有左值和右值大於5的節點加上2。
我們用一下查詢:
UPDATE tree SET rgt=rgt+2 WHERE rgt>5;
UPDATE tree SET lft=lft+2 WHERE lft>5;
現在我們可以添加一個新的節點“Strawberry”來填補這個新的空間。這個節點左值為6右值為7。
INSERT INTO tree SET lft=6, rgt=7, title='Strawberry';
如果我們運行display_tree() 函數,我們將發現我們新的“Strawberry”節點已經成功地插入了樹中:Food
Fruit
Red
Cherry
Strawberry
Yellow
Banana
Meat
Beef
Pork
缺點
首先,改進前序遍歷樹算法看上去很難理解。它當然沒有鄰接列表方法簡單。然而,一旦你習慣了左值和右值這兩個屬性,他就會變得清晰起來,你可以用這個技術來完成臨街列表能完成的所有事情,同時改進前序遍歷樹算法更快。當然,更新樹需要很多查詢,要慢一點,但是取得節點卻可以只用一個查詢。
最後一點:就像我已經說得我部推薦你使用節點的標題來引用這個節點。你應該遵循數據庫標准化的基本規則。我沒有使用數字標識是因為用了之後例子就比較難讀。
算法3
 在MYSQL中,數據表大致上是
CREATE TABLE Table_Types
在MYSQL中,數據表大致上是
CREATE TABLE Table_Types