復制代碼 代碼如下:
<?php
header("Content-Type:text/html; charset=utf-8");
define('APP_ROOT', str_replace('\\', '/', dirname(__FILE__)));
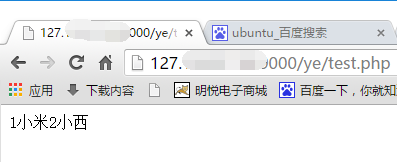
$test = '這裡是一段中文測試代碼!';
function get_tags_arr($title)
{
require(APP_ROOT.'/pscws4.class.php');
$pscws = new PSCWS4();
$pscws->set_dict(APP_ROOT.'/scws/dict.utf8.xdb');
$pscws->set_rule(APP_ROOT.'/scws/rules.utf8.ini');
$pscws->set_ignore(true);
$pscws->send_text($title);
$words = $pscws->get_tops(5);
$tags = array();
foreach ($words as $val) {
$tags[] = $val['word'];
}
$pscws->close();
return $tags;
}
print_r(get_tags_arr($test));
//============================================================
function get_keywords_str($content){
require(APP_ROOT.'/phpanalysis.class.php');
PhpAnalysis::$loadInit = false;
$pa = new PhpAnalysis('utf-8', 'utf-8', false);
$pa->LoadDict();
$pa->SetSource($content);
$pa->StartAnalysis( false );
$tags = $pa->GetFinallyResult();
return $tags;
}
print(get_keywords_str($test));
相關下載地址
SCWS – 簡易中文分詞系統
SCWS 在概念上並無創新成分,采用的是自行采集的詞頻詞典,並輔以一定程度上的專有名稱、人名、地名、數字年代等規則集,經小范圍測試大概准確率在 90% ~ 95% 之間,已能基本滿足一些中小型搜索引擎、關鍵字提取等場合運用。 SCWS 采用純 C 代碼開發,以 Unix-Like OS 為主要平台環境,提供共享函數庫,方便植入各種現有軟件系統。此外它支持 GBK,UTF-8,BIG5 等漢字編碼,切詞效率高。
系統平台:Windows/Unix
開發語言:C
使用方式:PHP擴展
演示網址:http://www.ftphp.com/scws/demo.php
開源官網:http://www.ftphp.com/scws/
晴楓附注:作為PHP擴展,容易與現有的基於PHP架構的Web系統繼續集成,是其一大優勢。
PhpanAlysis - PHP無組件分詞系統
PhpanAlysis分詞系統是基於字符串匹配的分詞方法 ,這種方法又叫做機械分詞方法,它是按照一定的策略將待分析的漢字串與一個“充分大的”機器詞典中的詞條進行配,若在詞典中找到某個字符串,則匹配成功(識別出一個詞)。按照掃描方向的不同,串匹配分詞方法可以分為正向匹配 和逆向匹配;按照不同長度優先匹配的情況,可以分為最大(最長)匹配和最小(最短)匹配;按照是否與詞性標注過程相結合,又可以分為單純分詞方法和分詞與標注相結合的一體化方法。
系統平台:PHP環境
開發語言:PHP
使用方式:HTTP服務
演示網址:http://www.itgrass.com/phpanalysis/
開源官網:http://www.itgrass.com/phpanalysis/
晴楓附注:實現簡單,容易使用,能做一些簡單應用,但大數據量的計算效率不如前幾種。
試用了幾個系統,基本分詞功能都沒什麼問題,只是在個別一些詞的劃分上存在一些差異;對於詞性的確定,系統間有所不同。
http://www.jb51.net/codes/40139.html