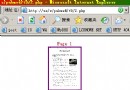
復制代碼 代碼如下:
$str = '中華人民共和國123456789abcdefg';
echo preg_match("/^[u4e00-u9fa5_a-zA-Z0-9]{3,15}$",$strName);
運行一下上面這段代碼,看會有什麼提示信息?
Warning: preg_match(): Compilation failed: PCRE does not support L, l, N, P, p, U, u, or X at offset 3 in F:wwwrootphptest.php on line 2
原來,PHP正則表達式中不支持下列 Perl 轉義序列:L, l, N, P, p, U, u, or X
在 UTF-8 模式下,允許用“x{...}”,花括號中的內容是表示十六進制數字的字符串。
原來的十六進制轉義序列 xhh 如果其值大於 127 的話則匹配了一個雙字節 UTF-8 字符。
所以,
可以這樣來解決
復制代碼 代碼如下:
preg_match("/^[x80-xff_a-zA-Z0-9]{3,15}$",$strName);
preg_match('/[x{2460}-x{2468}]/u', $str);
匹配 內碼漢字
按照他提供的方式進行測試,代碼如下:
復制代碼 代碼如下:
$str = "php編程";
if (preg_match("/^[x{2460}-x{2468}]+$/u",$str)) {
print("該字符串全部是中文");
} else {
print("該字符串不全部是中文");
}
發現這次依然對是否為中文判斷失常。不過,既然x表示的十六進制數據,為什麼和js裡邊提供的范圍x4e00-x9fa5不一樣呢?於是我就換成了下邊的代碼:
復制代碼 代碼如下:
$str = "php編程";
if (preg_match("/^[x4e00-x9fa5]+$/u",$str)) {
print("該字符串全部是中文");
} else {
print("該字符串不全部是中文");
}
本來以為鐵定成功了的事情,沒想到,warning又一次產生了:
Warning: preg_match() [function.preg-match]: Compilation failed: invalid UTF-8 string at offset 6 in test.php on line 3
看來又有錯誤的表達方式了,於是對照了一下那篇文章的表達方式,給“4e00”和“9fa5”兩邊分別用"{"和“}”包起來,跑了一遍,發現真的准確了:
復制代碼 代碼如下:
$str = "php編程";
if (preg_match("/^[x{4e00}-x{9fa5}]+$/u",$str)) {
print("該字符串全部是中文");
} else {
print("該字符串不全部是中文");
}
知道了php中utf-8編碼下用正則表達式匹配漢字的最終正確表達式——/^[x{4e00}-x{9fa5}]+$/u,
最後總結出
復制代碼 代碼如下:
//if (preg_match(“/^[".chr(0xa1)."-".chr(0xff)."]+$/”, $str)) { //只能在GB2312情況下使用
if (preg_match(“/^[x7f-xff]+$/”, $str)) { //兼容gb2312,utf-8
echo “正確輸入”;
} else {
echo “錯誤輸入”;
}
雙字節字符編碼范圍
1. GBK (GB2312/GB18030)
x00-xff GBK雙字節編碼范圍
x20-x7f ASCII
xa1-xff 中文 gb2312
x80-xff 中文 gbk
2. UTF-8 (Unicode)
u4e00-u9fa5 (中文)
x3130-x318F (韓文
xAC00-xD7A3 (韓文)
u0800-u4e00 (日文)