一、 內存 在PHP中,填充一個字符串變量相當簡單,這只需要一個語句"<?php $str = 'hello world '; ?>"即可,並且該字符串能夠被自由地修改、拷貝和移動。而在C語言中,盡管你能夠編寫例如"char *str = "hello world ";"這樣的一個簡單的靜態字符串;但是,卻不能修改該字符串,因為它生存於程序空間內。為了創建一個可操縱的字符串,你必須分配一個內存塊,並且通過一個函數(例如strdup())來復制其內容。
{
char *str;
str = strdup("hello world");
if (!str) {
fprintf(stderr, "Unable to allocate memory!");
}
}
由於後面我們將分析的各種原因,傳統型內存管理函數(例如malloc(),free(),strdup(),realloc(),calloc(),等等)幾乎都不能直接為PHP源代碼所使用。
二、 釋放內存 在幾乎所有的平台上,內存管理都是通過一種請求和釋放模式實現的。首先,一個應用程序請求它下面的層(通常指"操作系統"):"我想使用一些內存空間"。如果存在可用的空間,操作系統就會把它提供給該程序並且打上一個標記以便不會再把這部分內存分配給其它程序。
當應用程序使用完這部分內存,它應該被返回到OS;這樣以來,它就能夠被繼續分配給其它程序。如果該程序不返回這部分內存,那麼OS無法知道是否這塊內存不再使用並進而再分配給另一個進程。如果一個內存塊沒有釋放,並且所有者應用程序丟失了它,那麼,我們就說此應用程序"存在漏洞",因為這部分內存無法再為其它程序可用。
在一個典型的客戶端應用程序中,較小的不太經常的內存洩漏有時能夠為OS所"容忍",因為在這個進程稍後結束時該洩漏內存會被隱式返回到OS。這並沒有什麼,因為OS知道它把該內存分配給了哪個程序,並且它能夠確信當該程序終止時不再需要該內存。
而對於長時間運行的服務器守護程序,包括象Apache這樣的web服務器和擴展php模塊來說,進程往往被設計為相當長時間一直運行。因為OS不能清理內存使用,所以,任何程序的洩漏-無論是多麼小-都將導致重復操作並最終耗盡所有的系統資源。
現在,我們不妨考慮用戶空間內的stristr()函數;為了使用大小寫不敏感的搜索來查找一個字符串,它實際上創建了兩個串的各自的一個小型副本,然後執行一個更傳統型的大小寫敏感的搜索來查找相對的偏移量。然而,在定位該字符串的偏移量之後,它不再使用這些小寫版本的字符串。如果它不釋放這些副本,那麼,每一個使用stristr()的腳本在每次調用它時都將洩漏一些內存。最後,web服務器進程將擁有所有的系統內存,但卻不能夠使用它。
你可以理直氣壯地說,理想的解決方案就是編寫良好、干淨的、一致的代碼。這當然不錯;但是,在一個象PHP解釋器這樣的環境中,這種觀點僅對了一半。
三、 錯誤處理 為了實現"跳出"對用戶空間腳本及其依賴的擴展函數的一個活動請求,需要使用一種方法來完全"跳出"一個活動請求。這是在Zend引擎內實現的:在一個請求的開始設置一個"跳出"地址,然後在任何die()或exit()調用或在遇到任何關鍵錯誤(E_ERROR)時執行一個longjmp()以跳轉到該"跳出"地址。
盡管這個"跳出"進程能夠簡化程序執行的流程,但是,在絕大多數情況下,這會意味著將會跳過資源清除代碼部分(例如free()調用)並最終導致出現內存漏洞。現在,讓我們來考慮下面這個簡化版本的處理函數調用的引擎代碼:
void call_function(const char *fname, int fname_len TSRMLS_DC){
zend_function *fe;
char *lcase_fname;
/* PHP函數名是大小寫不敏感的,
*為了簡化在函數表中對它們的定位,
*所有函數名都隱含地翻譯為小寫的
*/
lcase_fname = estrndup(fname, fname_len);
zend_str_tolower(lcase_fname, fname_len);
if (zend_hash_find(EG(function_table),lcase_fname, fname_len + 1, (void **)&fe) == FAILURE) {
zend_execute(fe->op_array TSRMLS_CC);
} else {
php_error_docref(NULL TSRMLS_CC, E_ERROR,"Call to undefined function: %s()", fname);
}
efree(lcase_fname);
}
當執行到php_error_docref()這一行時,內部錯誤處理器就會明白該錯誤級別是critical,並相應地調用longjmp()來中斷當前程序流程並離開call_function()函數,甚至根本不會執行到efree(lcase_fname)這一行。你可能想把efree()代碼行移動到zend_error()代碼行的上面;但是,調用這個call_function()例程的代碼行會怎麼樣呢?fname本身很可能就是一個分配的字符串,並且,在它被錯誤消息處理使用完之前,你根本不能釋放它。
注意,這個php_error_docref()函數是trigger_error()函數的一個內部等價實現。它的第一個參數是一個將被添加到docref的可選的文檔引用。第三個參數可以是任何我們熟悉的E_*家族常量,用於指示錯誤的嚴重程度。第四個參數(最後一個)遵循printf()風格的格式化和變量參數列表式樣。
四、 Zend內存管理器
在上面的"跳出"請求期間解決內存洩漏的方案之一是:使用Zend內存管理(ZendMM)層。引擎的這一部分非常類似於操作系統的內存管理行為-分配內存給調用程序。區別在於,它處於進程空間中非常低的位置而且是"請求感知"的;這樣以來,當一個請求結束時,它能夠執行與OS在一個進程終止時相同的行為。也就是說,它會隱式地釋放所有的為該請求所占用的內存。圖1展示了ZendMM與OS以及PHP進程之間的關系。
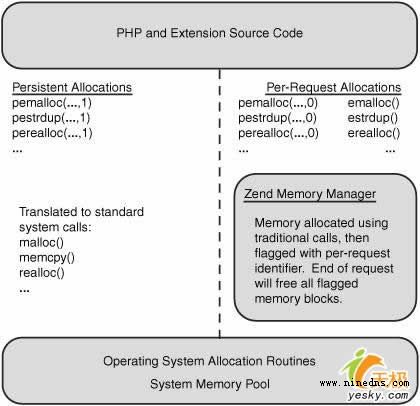
圖1.Zend內存管理器代替系統調用來實現針對每一種請求的內存分配。
除了提供隱式內存清除功能之外,ZendMM還能夠根據php.ini中memory_limit的設置控制每一種內存請求的用法。如果一個腳本試圖請求比系統中可用內存更多的內存,或大於它每次應該請求的最大量,那麼,ZendMM將自動地發出一個E_ERROR消息並且啟動相應的"跳出"進程。這種方法的一個額外優點在於,大多數內存分配調用的返回值並不需要檢查,因為如果失敗的話將會導致立即跳轉到引擎的退出部分。
把PHP內部代碼和OS的實際的內存管理層"鉤"在一起的原理並不復雜:所有內部分配的內存都要使用一組特定的可選函數實現。例如,PHP代碼不是使用malloc(16)來分配一個16字節內存塊而是使用了emalloc(16)。除了實現實際的內存分配任務外,ZendMM還會使用相應的綁定請求類型來標志該內存塊;這樣以來,當一個請求"跳出"時,ZendMM可以隱式地釋放它。
經常情況下,內存一般都需要被分配比單個請求持續時間更長的一段時間。這種類型的分配(因其在一次請求結束之後仍然存在而被稱為"永久性分配"),可以使用傳統型內存分配器來實現,因為這些分配並不會添加ZendMM使用的那些額外的相應於每種請求的信息。然而有時,直到運行時刻才會確定是否一個特定的分配需要永久性分配,因此ZendMM導出了一組幫助宏,其行為類似於其它的內存分配函數,但是使用最後一個額外參數來指示是否為永久性分配。
如果你確實想實現一個永久性分配,那麼這個參數應該被設置為1;在這種情況下,請求是通過傳統型malloc()分配器家族進行傳遞的。然而,如果運行時刻邏輯認為這個塊不需要永久性分配;那麼,這個參數可以被設置為零,並且調用將會被調整到針對每種請求的內存分配器函數。
例如,pemalloc(buffer_len,1)將映射到malloc(buffer_len),而pemalloc(buffer_len,0)將被使用下列語句映射到emalloc(buffer_len):
#define in Zend/zend_alloc.h:
#define pemalloc(size, persistent) ((persistent)?malloc(size): emalloc(size))
所有這些在ZendMM中提供的分配器函數都能夠從下表中找到其更傳統的對應實現。
表格1展示了ZendMM支持下的每一個分配器函數以及它們的e/pe對應實現:
表格1.傳統型相對於PHP特定的分配器。
分配器函數
e/pe對應實現
void *malloc(size_t count);
void *emalloc(size_t count);void *pemalloc(size_t count,char persistent);
void *calloc(size_t count);
void *ecalloc(size_t count);void *pecalloc(size_t count,char persistent);
void *realloc(void *ptr,size_t count);
void *erealloc(void *ptr,size_t count);
void *perealloc(void *ptr,size_t count,char persistent);
void *strdup(void *ptr);
void *estrdup(void *ptr);void *pestrdup(void *ptr,char persistent);
void free(void *ptr);
void efree(void *ptr);
void pefree(void *ptr,char persistent);
你可能會注意到,即使是pefree()函數也要求使用永久性標志。這是因為在調用pefree()時,它實際上並不知道是否ptr是一種永久性分配。針對一個非永久性分配調用free()能夠導致雙倍的空間釋放,而針對一種永久性分配調用efree()有可能會導致一個段錯誤,因為內存管理器會試圖查找並不存在的管理信息。因此,你的代碼需要記住它分配的數據結構是否是永久性的。
除了分配器函數核心部分外,還存在其它一些非常方便的ZendMM特定的函數,例如:
void *estrndup(void *ptr,int len);
該函數能夠分配len+1個字節的內存並且從ptr處復制len個字節到最新分配的塊。這個estrndup()函數的行為可以大致描述如下:
void *estrndup(void *ptr, int len)
{
char *dst = emalloc(len + 1);
memcpy(dst, ptr, len);
dst[len] = 0;
return dst;
}
在此,被隱式放置在緩沖區最後的NULL字節可以確保任何使用estrndup()實現字符串復制操作的函數都不需要擔心會把結果緩沖區傳遞給一個例如printf()這樣的希望以為NULL為結束符的函數。當使用estrndup()來復制非字符串數據時,最後一個字節實質上都浪費了,但其中的利明顯大於弊。
void *safe_emalloc(size_t size, size_t count, size_t addtl);
void *safe_pemalloc(size_t size, size_t count,size_t addtl,char persistent);
這些函數分配的內存空間最終大小是((size*count)+addtl)。你可以會問:"為什麼還要提供額外函數呢?為什麼不使用一個emalloc/pemalloc呢?"原因很簡單:為了安全。盡管有時候可能性相當小,但是,正是這一"可能性相當小"的結果導致宿主平台的內存溢出。這可能會導致分配負數個數的字節空間,或更有甚者,會導致分配一個小於調用程序要求大小的字節空間。而safe_emalloc()能夠避免這種類型的陷井-通過檢查整數溢出並且在發生這樣的溢出時顯式地預以結束。
注意,並不是所有的內存分配例程都有一個相應的p*對等實現。例如,不存在pestrndup(),並且在PHP 5.1版本前也不存在safe_pemalloc()。
五、 引用計數 慎重的內存分配與釋放對於PHP(它是一種多請求進程)的長期性能有極其重大的影響;但是,這還僅是問題的一半。為了使一個每秒處理上千次點擊的服務器高效地運行,每一次請求都需要使用盡可能少的內存並且要盡可能減少不必要的數據復制操作。請考慮下列PHP代碼片斷:
<?php
$a = 'Hello World';
$b = $a;
unset($a);
?>
在第一次調用之後,只有一個變量被創建,並且一個12字節的內存塊指派給它以便存儲字符串"Hello World",還包括一個結尾處的NULL字符。現在,讓我們來觀察後面的兩行:$b被置為與變量$a相同的值,然後變量$a被釋放。
如果PHP因每次變量賦值都要復制變量內容的話,那麼,對於上例中要復制的字符串還需要復制額外的12個字節,並且在數據復制期間還要進行另外的處理器加載。這一行為乍看起來有點荒謬,因為當第三行代碼出現時,原始變量被釋放,從而使得整個數據復制顯得完全不必要。其實,我們不妨再遠一層考慮,讓我們設想當一個10MB大小的文件的內容被裝載到兩個變量中時會發生什麼。這將會占用20MB的空間,此時,10已經足夠了。引擎會把那麼多的時間和內存浪費在這樣一種無用的努力上嗎?
你應該知道,PHP的設計者早已深谙此理。
記住,在引擎中,變量名和它們的值實際上是兩個不同的概念。值本身是一個無名的zval*存儲體(在本例中,是一個字符串值),它被通過zend_hash_add()賦給變量$a。如果兩個變量名都指向同一個值,會發生什麼呢?
{
zval *helloval;
MAKE_STD_ZVAL(helloval);
ZVAL_STRING(helloval, "Hello World", 1);
zend_hash_add(EG(active_symbol_table), "a", sizeof("a"),&helloval, sizeof(zval*), NULL);
zend_hash_add(EG(active_symbol_table), "b", sizeof("b"),&helloval, sizeof(zval*), NULL);
}
此時,你可以實際地觀察$a或$b,並且會看到它們都包含字符串"Hello World"。遺憾的是,接下來,你繼續執行第三行代碼"unset($a);"。此時,unset()並不知道$a變量指向的數據還被另一個變量所使用,因此它只是盲目地釋放掉該內存。任何隨後的對變量$b的存取都將被分析為已經釋放的內存空間並因此導致引擎崩潰。
這個問題可以借助於zval(它有好幾種形式)的第四個成員refcount加以解決。當一個變量被首次創建並賦值時,它的refcount被初始化為1,因為它被假定僅由最初創建它時相應的變量所使用。當你的代碼片斷開始把helloval賦給$b時,它需要把refcount的值增加為2;這樣以來,現在該值被兩個變量所引用:
{
zval *helloval;
MAKE_STD_ZVAL(helloval);
ZVAL_STRING(helloval, "Hello World", 1);
zend_hash_add(EG(active_symbol_table), "a", sizeof("a"),&helloval, sizeof(zval*), NULL);
ZVAL_ADDREF(helloval);
zend_hash_add(EG(active_symbol_table), "b", sizeof("b"),&helloval,sizeof(zval*),NULL);
}
現在,當unset()刪除原變量的$a相應的副本時,它就能夠從refcount參數中看到,還有另外其他人對該數據感興趣;因此,它應該只是減少refcount的計數值,然後不再管它。
六、 寫復制(Copy on Write)
通過refcounting來節約內存的確是不錯的主意,但是,當你僅想改變其中一個變量的值時情況會如何呢?為此,請考慮下面的代碼片斷:
<?php
$a = 1;
$b = $a;
$b += 5;
?>
通過上面的邏輯流程,你當然知道$a的值仍然等於1,而$b的值最後將是6。並且此時,你還知道,Zend在盡力節省內存-通過使$a和$b都引用相同的zval(見第二行代碼)。那麼,當執行到第三行並且必須改變$b變量的值時,會發生什麼情況呢?
回答是,Zend要查看refcount的值,並且確保在它的值大於1時對之進行分離。在Zend引擎中,分離是破壞一個引用對的過程,正好與你剛才看到的過程相反:
zval *get_var_and_separate(char *varname, int varname_len TSRMLS_DC)
{
zval **varval, *varcopy;
if (zend_hash_find(EG(active_symbol_table),varname, varname_len + 1, (void**)&varval) == FAILURE) {
/* 變量根本並不存在-失敗而導致退出*/
return NULL;
}
if ((*varval)->refcount < 2) {
/* varname是唯一的實際引用,
*不需要進行分離
*/
return *varval;
}
/* 否則,再復制一份zval*的值*/
MAKE_STD_ZVAL(varcopy);
varcopy = *varval;
/* 復制任何在zval*內的已分配的結構*/
zval_copy_ctor(varcopy);
/*刪除舊版本的varname
*這將減少該過程中varval的refcount的值
*/
zend_hash_del(EG(active_symbol_table), varname, varname_len + 1);
/*初始化新創建的值的引用計數,並把它依附到
* varname變量
*/
varcopy->refcount = 1;
varcopy->is_ref = 0;
zend_hash_add(EG(active_symbol_table), varname, varname_len + 1,&varcopy, sizeof(zval*), NULL);
/*返回新的zval* */
return varcopy;
}
現在,既然引擎有一個僅為變量$b所擁有的zval*(引擎能知道這一點),所以它能夠把這個值轉換成一個long型值並根據腳本的請求給它增加5。
七、 寫改變(change-on-write)
引用計數概念的引入還導致了一個新的數據操作可能性,其形式從用戶空間腳本管理器看來與"引用"有一定關系。請考慮下列的用戶空間代碼片斷:
<?php
$a = 1;
$b = &$a;
$b += 5;
?>
在上面的PHP代碼中,你能看出$a的值現在為6,盡管它一開始為1並且從未(直接)發生變化。之所以會發生這種情況是因為當引擎開始把$b的值增加5時,它注意到$b是一個對$a的引用並且認為"我可以改變該值而不必分離它,因為我想使所有的引用變量都能看到這一改變"。
但是,引擎是如何知道的呢?很簡單,它只要查看一下zval結構的第四個和最後一個元素(is_ref)即可。這是一個簡單的開/關位,它定義了該值是否實際上是一個用戶空間風格引用集的一部分。在前面的代碼片斷中,當執行第一行時,為$a創建的值得到一個refcount為1,還有一個is_ref值為0,因為它僅為一個變量($a)所擁有並且沒有其它變量對它產生寫引用改變。在第二行,這個值的refcount元素被增加為2,除了這次is_ref元素被置為1之外(因為腳本中包含了一個"&"符號以指示是完全引用)。
最後,在第三行,引擎再一次取出與變量$b相關的值並且檢查是否有必要進行分離。這一次該值沒有被分離,因為前面沒有包括一個檢查。下面是get_var_and_separate()函數中與refcount檢查有關的部分代碼:
if ((*varval)->is_ref || (*varval)->refcount < 2) {
/* varname是唯一的實際引用,
* 或者它是對其它變量的一個完全引用
*任何一種方式:都沒有進行分離
*/
return *varval;
}
這一次,盡管refcount為2,卻沒有實現分離,因為這個值是一個完全引用。引擎能夠自由地修改它而不必關心其它變量值的變化。
八、 分離問題
盡管已經存在上面討論到的復制和引用技術,但是還存在一些不能通過is_ref和refcount操作來解決的問題。請考慮下面這個PHP代碼塊:
<?php
$a = 1;
$b = $a;
$c = &$a;
?>
在此,你有一個需要與三個不同的變量相關聯的值。其中,兩個變量是使用了"change-on-write"完全引用方式,而第三個變量處於一種可分離的"copy-on-write"(寫復制)上下文中。如果僅使用is_ref和refcount來描述這種關系,有哪些值能夠工作呢?
回答是:沒有一個能工作。在這種情況下,這個值必須被復制到兩個分離的zval*中,盡管兩者都包含完全相同的數據(見圖2)。

圖2.引用時強制分離
同樣,下列代碼塊將引起相同的沖突並且強迫該值分離出一個副本(見圖3)。

圖3.復制時強制分離
<?php
$a = 1;
$b = &$a;
$c = $a;
?>
注意,在這裡的兩種情況下,$b都與原始的zval對象相關聯,因為在分離發生時引擎無法知道介於到該操作當中的第三個變量的名字。
九、 總結 PHP是一種托管語言。從普通用戶角度來看,這種仔細地控制資源和內存的方式意味著更為容易地進行原型開發並導致出現更少的沖突。然而,當我們深入"內裡"之後,一切的承諾似乎都不復存在,最終還要依賴於真正有責任心的開發者來維持整個運行時刻環境的一致性。