看代碼:
復制代碼 代碼如下:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title> New Document </title>
<meta name="author" content=""/>
<meta name="keywords" content=""/>
<meta name="description" content=""/>
<link rel="stylesheet" type="text/css" href="" />
</head>
<body>
<?php
$string1 = "i am a phper";
$string2 = "這網站是";
print_r(str_split($string1));
echo "<br />";
print_r(str_split($string2,4));
?>
</body>
</html>
測試結果打出我所料——
中文亂碼
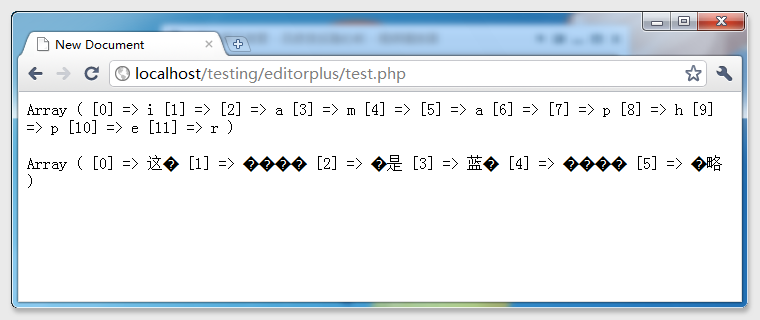
Why?Why?Why?Why?亂碼是什麼?什麼事亂碼?給我解釋解釋,什麼,是%&的亂碼!
因為英文無亂碼,只有中文亂碼,首先想到了編碼的問題,於是突然想起來UTF-8的編碼是UTF-8需要3個字節,死馬當活馬醫吧!
於是 print_r(str_split($string2,4));這句中的4 ,就被換成了6,於是乎——看結果
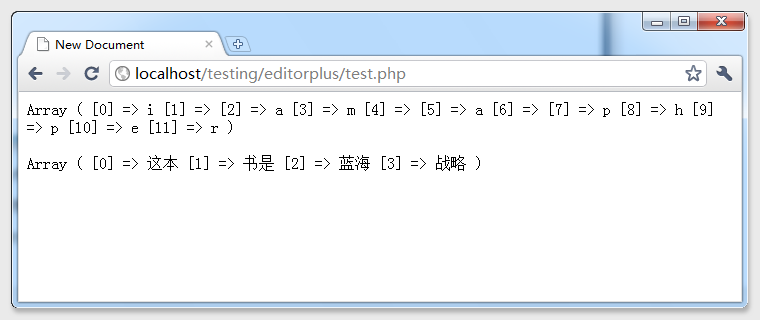
同樣,你也可以試試將編碼的charset的UTF-8改成GB2312,因為Unicode的編碼是需要2字節的,所以說Gb2312的編碼比UTF-8能夠節約1/3的空間,但是如果你要兼容繁體中文、韓文、日文的其他的語言就需要使用UTF-8了。