為什麼要用 cURL?
是的,我們可以通過其他辦法獲取網頁內容。大多數時候,我因為想偷懶,都直接用簡單的PHP函數:
$content = file_get_contents("http://www.jb51.net");
// or
$lines = file("http://www.jb51.net");
// or
readfile(http://www.jb51.net);
不過,這種做法缺乏靈活性和有效的錯誤處理。而且,你也不能用它完成一些高難度任務——比如處理coockies、驗證、表單提交、文件上傳等等。
引用:
cURL 是一種功能強大的庫,支持很多不同的協議、選項,能提供 URL 請求相關的各種細節信息。
基本結構
在學習更為復雜的功能之前,先來看一下在PHP中建立cURL請求的基本步驟:
// 1. 初始化
$ch = curl_init();
// 2. 設置選項,包括URL
curl_setopt($ch, CURLOPT_URL, "http://www.jb51.net");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HEADER, 0);
// 3. 執行並獲取HTML文檔內容
$output = curl_exec($ch);
// 4. 釋放curl句柄
curl_close($ch);
第二步(也就是 curl_setopt() )最為重要,一切玄妙均在此。有一長串cURL參數可供設置,它們能指定URL請求的各個細節。要一次性全部看完並理解可能比較困難,所以今天我們只試一下那些更常用也更有用的選項。
檢查錯誤
你可以加一段檢查錯誤的語句(雖然這並不是必需的):
// ...
$output = curl_exec($ch);
if ($output === FALSE) {
echo "cURL Error: " . curl_error($ch);
}
// ...
請注意,比較的時候我們用的是“=== FALSE”,而非“== FALSE”。因為我們得區分 空輸出 和 布爾值FALSE,後者才是真正的錯誤。
獲取信息
這是另一個可選的設置項,能夠在cURL執行後獲取這一請求的有關信息:
// ...
curl_exec($ch);
$info = curl_getinfo($ch);
echo '獲取'. $info['url'] . '耗時'. $info['total_time'] . '秒';
// ...
返回的數組中包括了以下信息:
基於浏覽器的重定向
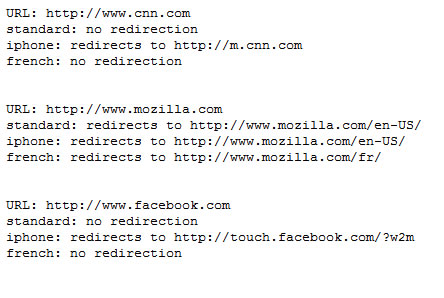
在第一個例子中,我們將提供一段用於偵測服務器是否有基於浏覽器的重定向的代碼。例如,有些網站會根據是否是手機浏覽器甚至用戶來自哪個國家來重定向網頁。
我們利用 CURLOPT_HTTPHEADER 選項來設定我們發送出的HTTP請求頭信息(http headers),包括user agent信息和默認語言。然後我們來看看這些特定網站是否會把我們重定向到不同的URL。
// 測試用的URL
$urls = array(
"http://www.cnn.com",
"http://www.mozilla.com",
"http://www.facebook.com"
);
// 測試用的浏覽器信息
$browsers = array(
"standard" => array (
"user_agent" => "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6 (.NET CLR 3.5.30729)",
"language" => "en-us,en;q=0.5"
),
"iphone" => array (
"user_agent" => "Mozilla/5.0 (iPhone; U; CPU like Mac OS X; en) AppleWebKit/420+ (KHTML, like Gecko) Version/3.0 Mobile/1A537a Safari/419.3",
"language" => "en"
),
"french" => array (
"user_agent" => "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; GTB6; .NET CLR 2.0.50727)",
"language" => "fr,fr-FR;q=0.5"
)
);
foreach ($urls as $url) {
echo "URL: $url\n";
foreach ($browsers as $test_name => $browser) {
$ch = curl_init();
// 設置 url
curl_setopt($ch, CURLOPT_URL, $url);
// 設置浏覽器的特定header
curl_setopt($ch, CURLOPT_HTTPHEADER, array(
"User-Agent: {$browser['user_agent']}",
"Accept-Language: {$browser['language']}"
));
// 頁面內容我們並不需要
curl_setopt($ch, CURLOPT_NOBODY, 1);
// 只需返回HTTP header
curl_setopt($ch, CURLOPT_HEADER, 1);
// 返回結果,而不是輸出它
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$output = curl_exec($ch);
curl_close($ch);
// 有重定向的HTTP頭信息嗎?
if (preg_match("!Location: (.*)!", $output, $matches)) {
echo "$test_name: redirects to $matches[1]\n";
} else {
echo "$test_name: no redirection\n";
}
}
echo "\n\n";
}
首先,我們建立一組需要測試的URL,接著指定一組需要測試的浏覽器信息。最後通過循環測試各種URL和浏覽器匹配可能產生的情況。
因為我們指定了cURL選項,所以返回的輸出內容則只包括HTTP頭信息(被存放於 $output 中)。利用一個簡單的正則,我們檢查這個頭信息中是否包含了“Location:”字樣。
運行這段代碼應該會返回如下結果:
用POST方法發送數據
當發起GET請求時,數據可以通過“查詢字串”(query string)傳遞給一個URL。例如,在google中搜索時,搜索關鍵即為URL的查詢字串的一部分:
http://www.google.com/search?q=nettuts
這種情況下你可能並不需要cURL來模擬。把這個URL丟給“file_get_contents()”就能得到相同結果。
不過有一些HTML表單是用POST方法提交的。這種表單提交時,數據是通過 HTTP請求體(request body) 發送,而不是查詢字串。例如,當使用CodeIgniter論壇的表單,無論你輸入什麼關鍵字,總是被POST到如下頁面:
http://codeigniter.com/forums/do_search/
你可以用PHP腳本來模擬這種URL請求。首先,新建一個可以接受並顯示POST數據的文件,我們給它命名為post_output.php:
print_r($_POST);
接下來,寫一段PHP腳本來執行cURL請求:
$url = "http://localhost/post_output.php";
$post_data = array (
"foo" => "bar",
"query" => "Nettuts",
"action" => "Submit"
);
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
// 我們在POST數據哦!
curl_setopt($ch, CURLOPT_POST, 1);
// 把post的變量加上
curl_setopt($ch, CURLOPT_POSTFIELDS, $post_data);
$output = curl_exec($ch);
curl_close($ch);
echo $output;
執行代碼後應該會得到以下結果:

這段腳本發送一個POST請求給 post_output.php ,這個頁面 $_POST 變量並返回,我們利用cURL捕捉了這個輸出。
文件上傳
上傳文件和前面的POST十分相似。因為所有的文件上傳表單都是通過POST方法提交的。
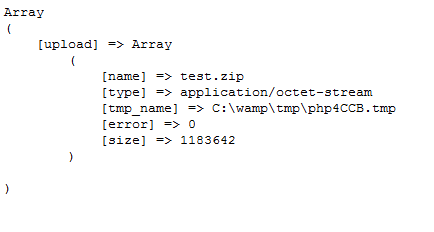
首先新建一個接收文件的頁面,命名為 upload_output.php:
print_r($_FILES);
以下是真正執行文件上傳任務的腳本:
$url = "http://localhost/upload_output.php";
$post_data = array (
"foo" => "bar",
// 要上傳的本地文件地址
"upload" => "@C:/wamp/www/test.zip"
);
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $post_data);
$output = curl_exec($ch);
curl_close($ch);
echo $output;
如果你需要上傳一個文件,只需要把文件路徑像一個post變量一樣傳過去,不過記得在前面加上@符號。執行這段腳本應該會得到如下輸出:
cURL批處理(multi cURL)
cURL還有一個高級特性——批處理句柄(handle)。這一特性允許你同時或異步地打開多個URL連接。
下面是來自來自php.net的示例代碼:
// 創建兩個cURL資源
$ch1 = curl_init();
$ch2 = curl_init();
// 指定URL和適當的參數
curl_setopt($ch1, CURLOPT_URL, "http://lxr.php.net/");
curl_setopt($ch1, CURLOPT_HEADER, 0);
curl_setopt($ch2, CURLOPT_URL, "http://www.php.net/");
curl_setopt($ch2, CURLOPT_HEADER, 0);
// 創建cURL批處理句柄
$mh = curl_multi_init();
// 加上前面兩個資源句柄
curl_multi_add_handle($mh,$ch1);
curl_multi_add_handle($mh,$ch2);
// 預定義一個狀態變量
$active = null;
// 執行批處理
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
while ($active && $mrc == CURLM_OK) {
if (curl_multi_select($mh) != -1) {
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
}
}
// 關閉各個句柄
curl_multi_remove_handle($mh, $ch1);
curl_multi_remove_handle($mh, $ch2);
curl_multi_close($mh);
這裡要做的就是打開多個cURL句柄並指派給一個批處理句柄。然後你就只需在一個while循環裡等它執行完畢。
這個示例中有兩個主要循環。第一個 do-while 循環重復調用 curl_multi_exec() 。這個函數是無隔斷(non-blocking)的,但會盡可能少地執行。它返回一個狀態值,只要這個值等於常量 CURLM_CALL_MULTI_PERFORM ,就代表還有一些刻不容緩的工作要做(例如,把對應URL的http頭信息發送出去)。也就是說,我們需要不斷調用該函數,直到返回值發生改變。
而接下來的 while 循環,只在 $active 變量為 true 時繼續。這一變量之前作為第二個參數傳給了 curl_multi_exec() ,代表只要批處理句柄中是否還有活動連接。接著,我們調用 curl_multi_select() ,在活動連接(例如接受服務器響應)出現之前,它都是被“屏蔽”的。這個函數成功執行後,我們又會進入另一個 do-while 循環,繼續下一條URL。
還是來看一看怎麼把這一功能用到實處吧:
WordPress 連接檢查器
想象一下你有一個文章數目龐大的博客,這些文章中包含了大量外部網站鏈接。一段時間之後,因為這樣那樣的原因,這些鏈接中相當數量都失效了。要麼是被和諧了,要麼是整個站點都被功夫網了...
我們下面建立一個腳本,分析所有這些鏈接,找出打不開或者404的網站/網頁,並生成一個報告。
請注意,以下並不是一個真正可用的WordPress插件,僅僅是一段獨立功能的腳本而已,僅供演示,謝謝。
好,開始吧。首先,從數據庫中讀取所有這些鏈接:
// CONFIG
$db_host = 'localhost';
$db_user = 'root';
$db_pass = '';
$db_name = 'wordpress';
$excluded_domains = array(
'localhost', 'www.mydomain.com');
$max_connections = 10;
// 初始化一些變量
$url_list = array();
$working_urls = array();
$dead_urls = array();
$not_found_urls = array();
$active = null;
// 連到 MySQL
if (!mysql_connect($db_host, $db_user, $db_pass)) {
die('Could not connect: ' . mysql_error());
}
if (!mysql_select_db($db_name)) {
die('Could not select db: ' . mysql_error());
}
// 找出所有含有鏈接的文章
$q = "SELECT post_content FROM wp_posts
WHERE post_content LIKE '%href=%'
AND post_status = 'publish'
AND post_type = 'post'";
$r = mysql_query($q) or die(mysql_error());
while ($d = mysql_fetch_assoc($r)) {
// 用正則匹配鏈接
if (preg_match_all("!href=\"(.*?)\"!", $d['post_content'], $matches)) {
foreach ($matches[1] as $url) {
// exclude some domains
$tmp = parse_url($url);
if (in_array($tmp['host'], $excluded_domains)) {
continue;
}
// store the url
$url_list []= $url;
}
}
}
// 移除重復鏈接
$url_list = array_values(array_unique($url_list));
if (!$url_list) {
die('No URL to check');
}
我們首先配置好數據庫,一系列要排除的域名($excluded_domains),以及最大並發連接數($max_connections)。然後,連接數據庫,獲取文章和包含的鏈接,把它們收集到一個數組中($url_list)。
下面的代碼有點復雜了,因此我將一小步一小步地詳細解釋:
// 1. 批處理器
$mh = curl_multi_init();
// 2. 加入需批量處理的URL
for ($i = 0; $i < $max_connections; $i++) {
add_url_to_multi_handle($mh, $url_list);
}
// 3. 初始處理
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
// 4. 主循環
while ($active && $mrc == CURLM_OK) {
// 5. 有活動連接
if (curl_multi_select($mh) != -1) {
// 6. 干活
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
// 7. 有信息否?
if ($mhinfo = curl_multi_info_read($mh)) {
// 意味著該連接正常結束
// 8. 從curl句柄獲取信息
$chinfo = curl_getinfo($mhinfo['handle']);
// 9. 死鏈麼?
if (!$chinfo['http_code']) {
$dead_urls []= $chinfo['url'];
// 10. 404了?
} else if ($chinfo['http_code'] == 404) {
$not_found_urls []= $chinfo['url'];
// 11. 還能用
} else {
$working_urls []= $chinfo['url'];
}
// 12. 移除句柄
curl_multi_remove_handle($mh, $mhinfo['handle']);
curl_close($mhinfo['handle']);
// 13. 加入新URL,干活
if (add_url_to_multi_handle($mh, $url_list)) {
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
}
}
}
}
// 14. 完了
curl_multi_close($mh);
echo "==Dead URLs==\n";
echo implode("\n",$dead_urls) . "\n\n";
echo "==404 URLs==\n";
echo implode("\n",$not_found_urls) . "\n\n";
echo "==Working URLs==\n";
echo implode("\n",$working_urls);
// 15. 向批處理器添加url
function add_url_to_multi_handle($mh, $url_list) {
static $index = 0;
// 如果還剩url沒用
if ($url_list[$index]) {
// 新建curl句柄
$ch = curl_init();
// 配置url
curl_setopt($ch, CURLOPT_URL, $url_list[$index]);
// 不想輸出返回的內容
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
// 重定向到哪兒我們就去哪兒
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
// 不需要內容體,能夠節約帶寬和時間
curl_setopt($ch, CURLOPT_NOBODY, 1);
// 加入到批處理器中
curl_multi_add_handle($mh, $ch);
// 撥一下計數器,下次調用該函數就能添加下一個url了
$index++;
return true;
} else {
// 沒有新的URL需要處理了
return false;
}
}
下面解釋一下以上代碼。列表的序號對應著代碼注釋中的順序數字。
我把這個腳本在我的博客上跑了一遍(測試需要,有一些錯誤鏈接是故意加上的),結果如下:
<img border="0" src="http://files.jb51.net/upload/201106/20110602225008534.png" />
共檢查約40個URL,只耗費兩秒不到。當需要檢查更加大量的URL時,其省心省力的效果可想而知!如果你同時打開10個連接,還能再快上10倍!另外,你還可以利用cURL批處理的無隔斷特性來處理大量URL請求,而不會阻塞你的Web腳本。
另一些有用的cURL 選項
HTTP 認證
如果某個URL請求需要基於 HTTP 的身份驗證,你可以使用下面的代碼:
復制內容到剪貼板代碼:
$url = "http://www.somesite.com/members/";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
// 發送用戶名和密碼
curl_setopt($ch, CURLOPT_USERPWD, "myusername:mypassword");
// 你可以允許其重定向
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
// 下面的選項讓 cURL 在重定向後
// 也能發送用戶名和密碼
curl_setopt($ch, CURLOPT_UNRESTRICTED_AUTH, 1);
$output = curl_exec($ch);
curl_close($ch);
FTP 上傳
PHP 自帶有 FTP 類庫, 但你也能用 cURL:
// 開一個文件指針
$file = fopen("/path/to/file", "r");
// url裡包含了大部分所需信息
$url = "ftp://username:[email protected]:21/path/to/new/file";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
// 上傳相關的選項
curl_setopt($ch, CURLOPT_UPLOAD, 1);
curl_setopt($ch, CURLOPT_INFILE, $fp);
curl_setopt($ch, CURLOPT_INFILESIZE, filesize("/path/to/file"));
// 是否開啟ASCII模式 (上傳文本文件時有用)
curl_setopt($ch, CURLOPT_FTPASCII, 1);
$output = curl_exec($ch);
curl_close($ch);
翻牆術
你可以用代理發起cURL請求:
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL,'http://www.example.com');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
// 指定代理地址
curl_setopt($ch, CURLOPT_PROXY, '11.11.11.11:8080');
// 如果需要的話,提供用戶名和密碼
curl_setopt($ch, CURLOPT_PROXYUSERPWD,'user:pass');
$output = curl_exec($ch);
curl_close ($ch);
回調函數
可以在一個URL請求過程中,讓cURL調用某指定的回調函數。例如,在內容或者響應下載的過程中立刻開始利用數據,而不用等到完全下載完。
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL,'http://net.tutsplus.com');
curl_setopt($ch, CURLOPT_WRITEFUNCTION,"progress_function");
curl_exec($ch);
curl_close ($ch);
function progress_function($ch,$str) {
echo $str;
return strlen($str);
}
這個回調函數必須返回字串的長度,不然此功能將無法正常使用。
在URL響應接收的過程中,只要收到一個數據包,這個函數就會被調用。
小結
今天我們一起學習了cURL庫的強大功能和靈活的擴展性。希望你喜歡。下一次要發起URL請求時,考慮下cURL吧!
原文:基於PHP的cURL快速入門
英文原文:http://net.tutsplus.com/tutorial%20...%20for-mastering-curl/
原文作者:Burak Guzel