截取yahoo.com.cn新聞[僅供實驗]
有很多截取首頁新聞的程序,但是並不能成功。
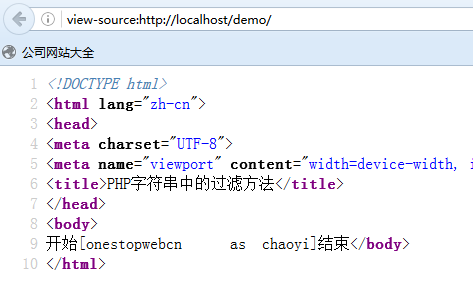
他們的工作原理無非兩種,一種是采用某些網站稱之為backend的後端數據庫接口,另一種則是硬聲聲的根據html代碼截取。本程序采用的是後者。應該說,容錯性能比較好。
<?
$open = fopen("http://www.yahoo.com.cn/index.html", "r");//網頁地址
$read = fread($open, 15000);
fclose($open);
$search = eregi("<!-- Start in the news -->(.*)<!-- End in the news -->", $read, $printing);//截取一段源代碼,最好先分析一下源代碼
//以下開始取出容余源代碼
$printing[1] = str_replace("href=\"/homer/?", "href=\"", $printing[1]);
$printing[1] = str_replace("href=\"/headlines/fullcoverage/", "href=\"http://www.yahoo.com.cn/headlines/fullcoverage/", $printing[1]);
$printing[1] = str_replace("</td></tr><tr><td valign=top align=right>", "", $printing[1]);
$printing[1] = str_replace("</td><td>", "", $printing[1]);
$printing[1] = str_replace(" class=sbody", "", $printing[1]);
$printing[1] = str_replace("</small>", "", $printing[1]);
$content = $printing[1];
$content = explode("-", $content);
$headlines = sizeof($content);
for ($i = 0; $i < $headlines; $i++) {
print "新聞".($i+1).") : $content[$i]<BR>";//激動人心的時刻到了!顯示出來了!
}
?>
在php3/php4 apache下調試通過。