數據庫高可用架構對於我們這些應用端開發的人來說是一個比較陌生的領域,是在具體的數據庫產品之上搭建的環境,需要像DBA這樣對數據庫產品有足夠的了解才能有所涉及,雖然不能深入其中,但可以通過一些經典的高可用架構學習其中的思想。就我所了解到的有以下幾種:
MySQL Replication
MySQL Cluster
Oracle RAC
IBM HACMP
Oracle ASM
MySQL Replication
MySQL Replication就是通過異步復制多個copy以達到提高可用性的目的,常規的復制架構有以下幾種:
Master-Slaves
Master-Master
Master-Master-Salves
1)Master-Slaves
Master- Slaves是最常用的提高可用的方法,特別是在互聯網應用中,讀遠遠大於寫,因此提高讀的可用性是首當其中的,Master-Slaves就是讓寫的操作集中在一台數據庫Master上,然後這個Master會把更新的操作復制到其他數據庫Slaves上,讀的操作都發生在Slaves上,架構圖如下所示:
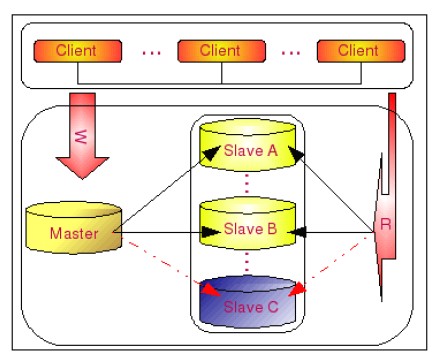
如上圖在SlaveC不可用時,讀和寫都不會中斷,等SlaveC恢復後會自動同步丟失的數據,又能重新投入運轉,可維護性非常好。但如果Master有問題就麻煩了,因此它只解決了讀的高可用性,但不保證寫的高可用性。
2)Master-Master
為解決上面談的寫的高可用性,MySQL提供了Master-Master的復制架構,如下所示:
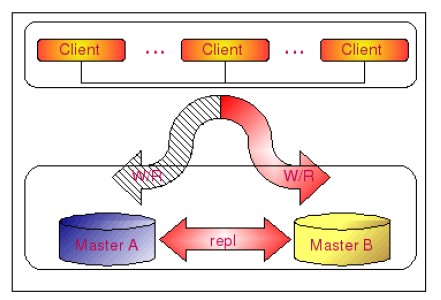
一般說來都向MasterA寫,MasterA同步數據到MasterB,當MasterA有問題時,會自動切換到MasterB,等MasterA恢復時,MasterB同步數據到MasterA
3)Master-Master-Salves
Master-Master-Salves是結合上面兩種方案,是一種同時提供讀和寫高可用的復制架構,如下圖所示:
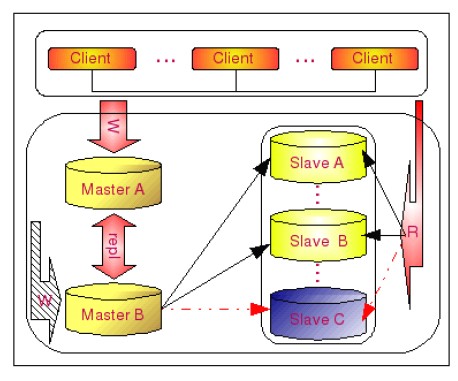
MySQL Cluster
MySQL Cluster主要由三個部分組成:
SQL服務器節點
NDB數據存儲節點
監控和管理節點
三個部門的組成結構如下圖所示:
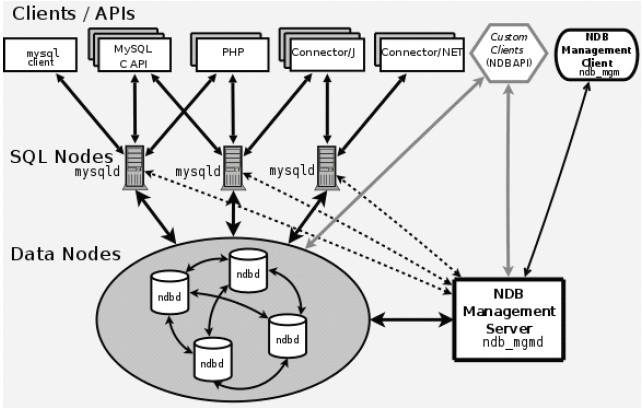
這樣的分層也是由MySQL本身把SQL處理和存儲分開的架構相關系的。
這樣一來MySQL Cluster就可以分別在SQL處理和存儲兩個層次上做高可用的復制策略。在SQL處理層次上,比較容易做集群,因為這些SQL處理是無狀態性的,完全可以通過增加機器的方式增強可用性。在存儲層次上,通過對每個節點進行備份的形式增加存儲的可用性,這類似與MySQL Replication,結構圖如下所示:
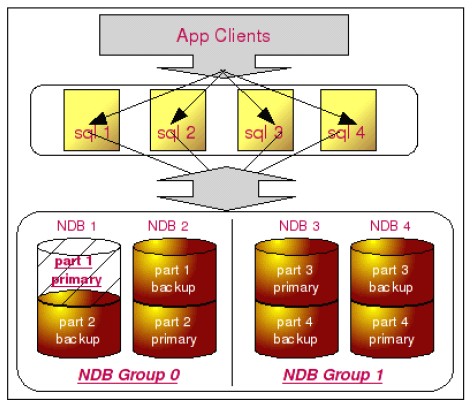
Oracle RAC
Oracle RAC和MySQL Cluster有些相似,但主要集中在SQL處理層的高可用性,而在存儲上體現不多,結構圖如下所示:
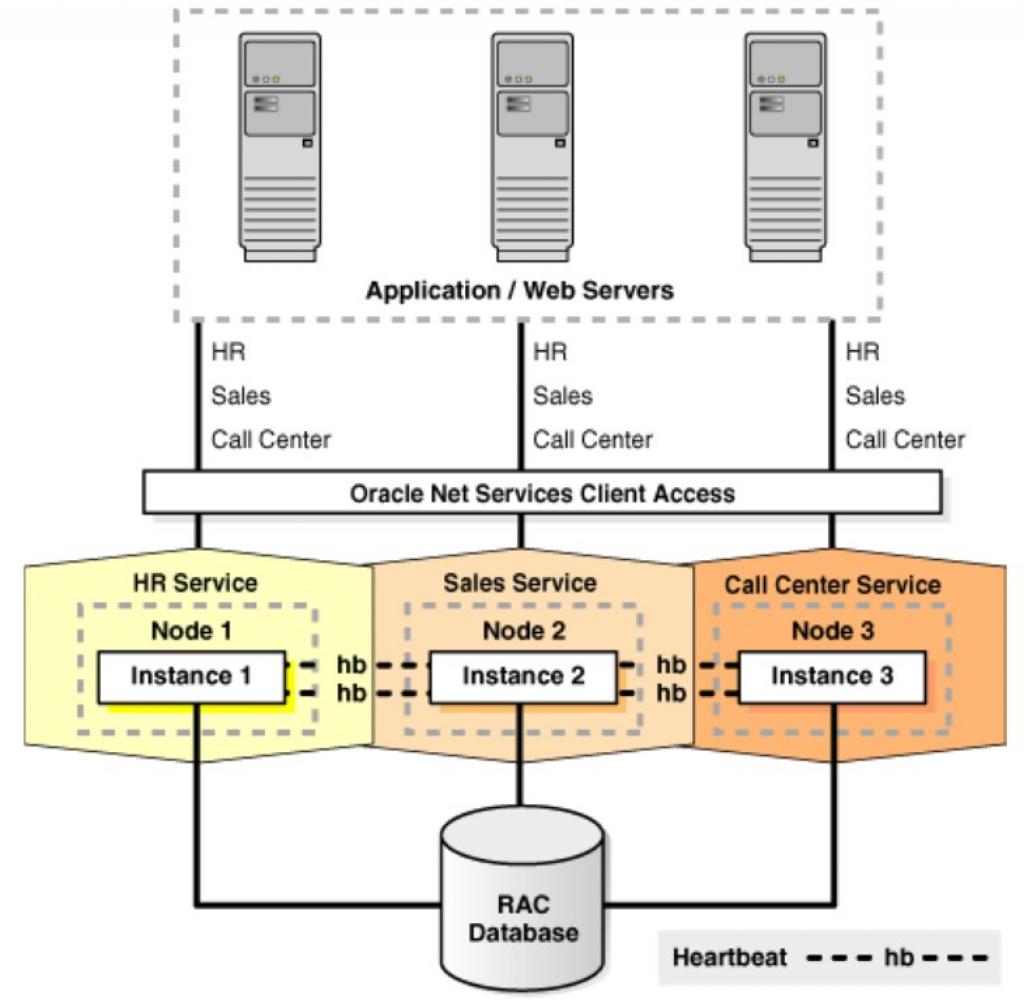
它的主要優點就是對應用透明,並且通過Heartbeat檢測可用性非常高,主要缺點就是存儲是共享的,存儲上可擴展能力不足。
IBM HACMP
IBM HACMP與Oracle RAC也是類似,主要用於雙機互備,運行流程如下所示:
1)作為雙機系統的兩台服務器(主機A和B)同時運行在Hacmp環境中;
2)服務器除正常運行自機的應用外,同時又作為對方的備份主機;
3)兩台主機系統(A和B)在整個運行過程中,通過 “心跳線”相互監測對方的運行情況(包括系統的軟硬件運行、網絡通訊和應用運行情況等);
4)一旦發現對方主機的運行不正常(出故障)時,故障機上的應用就會立即停止運行,本機(故障機的備份機)就會立即在自己的機器上啟動故障機上的應用,把故障機的應用及其資源(包括用到的IP地址和磁盤空間等)接管過來,使故障機上的應用在本機繼續運行;
5)應用和資源的接管過程由Ha軟件自動完成,無需人工干預;
6)當兩台主機正常工作時,也可以根據需要將其中一台機上的應用人為切換到另一台機(備份機)上運行。
Oracle ASM
Oracle ASM主要提供存儲的可擴展性,通過自動化的存儲管理加上後端可擴展性的存儲陣列達到高可用性,結構圖如下所示:
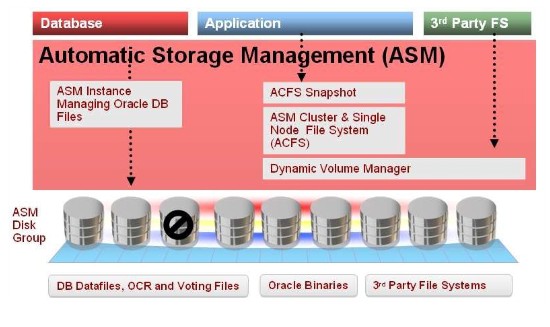
因此,可以嘗試把Oracle RAC和ASM組合起來使用,同時提供SQL處理和存儲的高可用性,這也是MySQL Cluster想達到的效果。