redis翻譯_redis管道
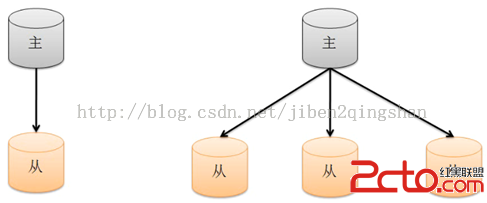
Redis is a TCP server using the client-server model and what is called a Request/Response protocol.
redis使用的是基於tcp協議的client-server模型,也可以叫做
Request/Response 協議模型. This means that usually a request is accomplished with the following steps:
它的意思是指通常一個請求完成分為下面的步驟
The client sends a query to the server, and reads from the socket, usually in a blocking way, for the server response.
客戶端對redis服務器發生查詢請求,通過socket連接redis服務器端,通常在收到返回之前是阻塞的
The server processes the command and sends the response back to the client
redis服務器執行命令並且發送結果返回給客戶端 So for instance a four commands sequence is something like this:
因此rdis實例執行4個命令的順序大概是這樣的:
Client: INCR X
Server: 1
Client: INCR X
Server: 2
Client: INCR X
Server: 3
Client: INCR X
Server: 4 Clients and Servers are connected via a networking link. Such a link can be very fast (a loopback interface) or very slow (a connection established over the Internet with many hops between the two hosts). Whatever the network latency is, there is a time for the packets to travel from the client to the server, and back from the server to the client to carry the reply.
客戶端與redis服務器通過網絡連接。這樣的連接可以是非常快的(一個本地回送端口)或者是非常慢(通過Internet連接的兩個主機)。然而不管這個網絡因素如何,有一個數據包到服務器,服務器就會返回一個應答。(解釋:請求發出到收到返回的這個時間叫RTT) This time is called RTT (Round Trip Time). It is very easy to see how this can affect the performances when a client needs to perform many requests in a row (for instance adding many elements to the same list, or populating a database with many keys). For instance if the RTT time is 250 milliseconds (in the case of a very slow link over the Internet), even if the server is able to process 100k requests per second, we'll be able to process at max four requests per second.
這個個過程的時間開銷叫RTT(一個來回時間).顯然,當一個客戶端連續不斷地發生請求(增加很多元素進同一個list,或者獲取很多key)對性能是有影響的。因此如果一個redis實例的RTT 時間是250毫米(連接的網絡比較慢),盡管redis理論上每秒可以處理100k的請求,我們每秒也只能處理4個請求. If the interface used is a loopback interface, the RTT is much shorter (for instance my host reports 0,044 milliseconds pinging 127.0.0.1), but it is still a lot if you need to perform many writes in a row.
如果網絡使用的是會送接口,RTT 時間就短很多(比如我ping本機的實例只要44毫米),但是如果連續不斷地發送命令仍然會比較長。 Fortunately there is a way to improve this use case.
幸運的是有一些改進的案例.
Redis Pipelining
A Request/Response server can be implemented so that it is able to process new requests even if the client didn't already read the old responses. This way it is possible to send
multiple commands to the server without waiting for the replies at all, and finally read the replies in a single step.
一個Request/Response 的sever可以執行新的requests,盡管client沒收到以前的respones。這個方式是向server發送很多命令,不等待應答,直到最後一次性讀取所有的應答。 This is called pipelining, and is a technique widely in use since many decades. For instance many POP3 protocol implementations already supported this feature, dramatically speeding up the process of downloading new emails from the server.
這種方式就叫pipelining(管道),是十幾年前就被廣泛使用的技術。例如,POP3協議已經實現了這種特性,大大加快了從服務器下載郵件的速度。 Redis supports pipelining since the very early days, so whatever version you are running, you can use pipelining with Redis. This is an example using the raw netcat utility:
redis在早期就已經支持pipelining,因此不管哪個版本你都可以使用pipelining。下面是一個使用netcat的例子:
$ (printf "PING\r\nPING\r\nPING\r\n"; sleep 1) | nc localhost 6379
+PONG
+PONG
+PONG
This time we are not paying the cost of RTT for every call, but just one time for the three commands
不是每個call都花一個RTT時間,而是一個RTT 時間執行3個命令。 To be very explicit, with pipelining the order of operations of our very first example will be the following:
顯然,pipelining 的操作過程是這樣的:
Client: INCR X
Client: INCR X
Client: INCR X
Client: INCR X
Server: 1
Server: 2
Server: 3
Server: 4 IMPORTANT NOTE:While the client sends commands using pipelining, the server will be forced to queue the replies, using memory. So if you need to send a lot of commands with pipelining, it is better to send them as batches having a reasonable number, for instance 10k commands, read the replies, and then send another 10k commands again, and so forth. The speed will be nearly the same, but the additional memory used will be at max the amount needed to queue the replies for this 10k commands.
當client使用pipelining發生一些命令時,redis server將使用內存為應答創建一個隊列。因此你使用pipelining發生很多命令,一個好的做法是,合理地批量發送,比如,10k一個批次,得到返回後在發生10k。速度大概是一樣的,但是redis server為了這個10k的命令要花費內存去創建應答隊列。
Some benchmark
In the following benchmark we'll use the Redis Ruby client, supporting pipelining, to test the speed improvement due to pipelining:
下面是使用ruby支持pipelining客戶端的例子:
require 'rubygems'
require 'redis'
def bench(descr)
start = Time.now
yield
puts "#{descr} #{Time.now-start} seconds"
end
def without_pipelining
r = Redis.new
10000.times {
r.ping
}
end
def with_pipelining
r = Redis.new
r.pipelined {
10000.times {
r.ping
}
}
end
bench("without pipelining") {
without_pipelining
}
bench("with pipelining") {
with_pipelining
}
Running the above simple script will provide the following figures in my Mac OS X system, running over the loopback interface, where pipelining will provide the smallest improvement as the RTT is already pretty low:
在mac os x上運行上面的腳步,和沒有使用pipelining 運行的比較如下:
without pipelining 1.185238 seconds
with pipelining 0.250783 seconds
As you can see, using pipelining, we improved the transfer by a factor of five.
可以發現,使用pipelining傳輸速度提升了5倍
Pipelining VS Scripting
Using Redis scripting (available in Redis version 2.6 or greater) a number of use cases for pipelining can be addressed more efficiently using scripts that perform a lot of the work needed at the server side. A big advantage of scripting is that it is able to both read and write data with minimal latency, making operations like
read, compute, write very fast (pipelining can't help in this scenario since the client needs the reply of the read command before it can call the write command).
大量的實驗證明,為pipelining 使用腳步可以在服務端處理更多的工作。一個大優點是,使用腳步可以讓讀和寫延遲小,使得讀、寫、計算變得很快(在客戶端需要收到返回才發送命令的情況時,pipelining 是不能滿足的) Sometimes the application may also want to send EVAL or EVALSHA commands in a pipeline. This is entirely possible and Redis explicitly supports it with the SCRIPT LOAD command (it guarantees that EVALSHA can be called without the risk of failing).
一些應用可能想在pipeline裡發生EVAL 或者EVALSHA命令。使用SCRIOT LOAD命令是完全支持的(它保證執行沒有失敗的風險)