Apache Drill可用於大數據的實時分析,引用一段介紹:
受到Google Dremel啟發,Apache的Drill項目是對大數據集進行交互式分析的分布式系統。Drill並不會試圖取代已有的大數據批處理框架(Big Data batch processing framework),如Hadoop MapReduce或流處理框架(stream processing framework),如S4和Storm。相反,它是要填充現有空白的——對大數據集的實時交互式處理
簡單來說,Drill可接收SQL查詢語句,然後後端從多個數據源例如HDFS、MongoDB等獲取數據並分析產出分析結果。在一次分析中,它可以匯集多個數據源的數據。而且基於分布式的架構,可以支持秒級查詢。
Drill在架構上是比較靈活的,它的前端可以不一定是SQL查詢語言,後端數據源也可以接入Storage plugin來支持其他數據來源。這裡我就實現了一個從HTTP服務獲取數據的Storage plugin demo。這個demo可以接入基於GET請求,返回JSON格式的HTTP服務。源碼可從我的Github獲取:drill-storage-http
例子包括:
select name, length from http.`/e/api:search` where $p=2 and $q='avi' select name, length from http.`/e/api:search?q=avi&p=2` where length > 0
要實現一個自己的storage plugin,目前Drill這方面文檔幾乎沒有,只能從已有的其他storage plugin源碼入手,例如mongodb的,參考Drill子項目drill-mongo-storage。實現的storage plugin打包為jar放到jars目錄,Drill啟動時會自動載入,然後web上配置指定類型即可。
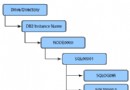
主要需要實現的類包括:
AbstractStoragePlugin StoragePluginConfig SchemaFactory BatchCreator AbstractRecordReader AbstractGroupScan
StoragePluginConfig用於配置plugin,例如:
{
"type" : "http",
"connection" : "http://xxx.com:8000",
"resultKey" : "results",
"enabled" : true
}
它必須是可JSON序列化/反序列化的,Drill會把storage配置存儲到/tmp/drill/sys.storage_plugins中,例如windows下D:\tmp\drill\sys.storage_plugins。
AbstractStoragePlugin 是plugin的主類,它必須配合StoragePluginConfig,實現這個類時,構造函數必須遵循參數約定,例如:
public HttpStoragePlugin(HttpStoragePluginConfig httpConfig, DrillbitContext context, String name)
Drill啟動時會自動掃描AbstractStoragePlugin實現類(StoragePluginRegistry),並建立StoragePluginConfig.class到AbstractStoragePlugin constructor的映射。AbstractStoragePlugin需要實現的接口包括:
// 相應地需要實現AbstraceGroupScan
// selection包含了database name和table name,可用可不用
public AbstractGroupScan getPhysicalScan(String userName, JSONOptions selection)
// 注冊schema
public void registerSchemas(SchemaConfig schemaConfig, SchemaPlus parent) throws IOException
// StoragePluginOptimizerRule 用於優化Drill生成的plan,可實現也可不實現
public Set getOptimizerRules()
Drill中的schema用於描述一個database,以及處理table之類的事務,必須要實現,否則任意一個SQL查詢都會被認為是找不到對應的table。AbstraceGroupScan用於一次查詢中提供信息,例如查詢哪些columns。
Drill在查詢時,有一種中間數據結構(基於JSON)叫Plan,其中又分為Logic Plan和Physical Plan。Logic Plan是第一層中間結構,用於完整表達一次查詢,是SQL或其他前端查詢語言轉換後的中間結構。完了後還要被轉換為Physical Plan,又稱為Exectuion Plan,這個Plan是被優化後的Plan,可用於與數據源交互進行真正的查詢。StoragePluginOptimizerRule就是用於優化Physical Plan的。這些Plan最終對應的結構有點類似於語法樹,畢竟SQL也可以被認為是一種程序語言。StoragePluginOptimizerRule可以被理解為改寫這些語法樹的。例如Mongo storage plugin就實現了這個類,它會把where中的filter轉換為mongodb自己的filter(如{‘$gt’: 2}),從而優化查詢。
這裡又牽扯出Apache的另一個項目:calcite,前身就是OptiQ。Drill中整個關於SQL的執行,主要是依靠這個項目。要玩轉Plan的優化是比較難的,也是因為文檔欠缺,相關代碼較多。
registerSchemas主要還是調用SchemaFactory.registerSchemas接口。Drill中的Schema是一種樹狀結構,所以可以看到registerSchemas實際就是往parent中添加child:
public void registerSchemas(SchemaConfig schemaConfig, SchemaPlus parent) throws IOException {
HttpSchema schema = new HttpSchema(schemaName);
parent.add(schema.getName(), schema);
}
HttpSchema派生於AbstractSchema,主要需要實現接口getTable,因為我這個http storage plugin中的table實際就是傳給HTTP service的query,所以table是動態的,所以getTable的實現比較簡單:
public Table getTable(String tableName) { // table name can be any of string
HttpScanSpec spec = new HttpScanSpec(tableName); // will be pass to getPhysicalScan
return new DynamicDrillTable(plugin, schemaName, null, spec);
}
這裡的HttpScanSpec用於保存查詢中的一些參數,例如這裡保存了table name,也就是HTTP service的query,例如/e/api:search?q=avi&p=2。它會被傳到AbstraceStoragePlugin.getPhysicalScan中的JSONOptions:
public AbstractGroupScan getPhysicalScan(String userName, JSONOptions selection) throws IOException {
HttpScanSpec spec = selection.getListWith(new ObjectMapper(), new TypeReference() {});
return new HttpGroupScan(userName, httpConfig, spec);
}
HttpGroupScan後面會看到用處。
AbstractRecordReader負責真正地讀取數據並返回給Drill。BatchCreator則是用於創建AbstractRecordReader。
public class HttpScanBatchCreator implements BatchCreator{ @Override public CloseableRecordBatch getBatch(FragmentContext context, HttpSubScan config, List children) throws ExecutionSetupException { List readers = Lists.newArrayList(); readers.add(new HttpRecordReader(context, config)); return new ScanBatch(config, context, readers.iterator()); } }
既然AbstractRecordReader負責真正讀取數據,那麼它肯定是需要知道傳給HTTP service的query的,但這個query最早是在HttpScanSpec中,然後傳給了HttpGroupScan,所以馬上會看到HttpGroupScan又把參數信息傳給了HttpSubScan。
Drill也會自動掃描BatchCreator的實現類,所以這裡就不用關心HttpScanBatchCreator的來歷了。
HttpSubScan的實現比較簡單,主要是用來存儲HttpScanSpec的:
public class HttpSubScan extends AbstractBase implements SubScan // 需要實現SubScan
回到HttpGroupScan,必須實現的接口:
public SubScan getSpecificScan(int minorFragmentId) { // pass to HttpScanBatchCreator
return new HttpSubScan(config, scanSpec); // 最終會被傳遞到HttpScanBatchCreator.getBatch接口
}
最終query被傳遞到HttpRecordReader,該類需要實現的接口包括:setup和next,有點類似於迭代器。setup中查詢出數據,然後next中轉換數據給Drill。轉換給Drill時可以使用到VectorContainerWriter和JsonReader。這裡也就是Drill中傳說的vector數據格式,也就是列存儲數據。
以上,就包含了plugin本身的創建,及查詢中query的傳遞。查詢中類似select titile, name 中的columns會被傳遞到HttpGroupScan.clone接口,只不過我這裡並不關注。實現了這些,就可以通過Drill查詢HTTP service中的數據了。
而select * from xx where xx中的where filter,Drill自己會對查詢出來的數據做過濾。如果要像mongo plugin中構造mongodb的filter,則需要實現StoragePluginOptimizerRule。
我這裡實現的HTTP storage plugin,本意是覺得傳給HTTP service的query可能會動態構建,例如:
select name, length from http.`/e/api:search` where $p=2 and $q='avi' # p=2&q=avi 就是動態構建,其值可以來源於其他查詢結果 select name, length from http.`/e/api:search?q=avi&p=2` where length > 0 # 這裡就是靜態的
第一條查詢就需要借助StoragePluginOptimizerRule,它會收集所有where中的filter,最終作為HTTP serivce的query。但這裡的實現還不完善。
總體而言,由於Drill項目相對較新,要進行擴展還是比較困難的。尤其是Plan優化部分。