Aerospike數據庫是Shared-Nothing 架構:一個Aerospike集群中的每個節點都是相同的,所有節點對等,無單點故障。
利用Aerospike智能分區算法,數據分布在集群中的各個節點之上。我們已經在這個領域的許多案例中測試過我們的方法,這個非常隨機數函數保證分區分布誤差在1-2%。
為了確定記錄去向,使用RIPEMD160算法,任意長度的記錄鍵(key)被哈希化為一個20位的定長字符串,前12位組成分區ID,用來確定哪個分區包含這條記錄。分區同樣分布於集群節點中。所以,集群中有N個節點,每個節點大約存儲1/N的數據。
因為數據均勻且隨機的分布於節點,不會出現熱點和瓶頸。也不會出現明顯的某個節點比其他節點處理請求多的情況。
例如,在美國很多的姓以R開頭。如果數據按照字母排序存儲,存儲以R開頭的服務器其通訊量會遠遠大於存儲以X,Y或Z開頭的服務器。數據隨機分配保證服務器負載均衡。
對於可靠性,Aerospike在一個或多個節點上復制分區。一個節點作為讀寫分區的主節點,其他節點存儲副本。
例如,在一個4節點的Aerospike集群中,每個節點約是1/4數據的主節點,同時也是1/4數據的副本。作為主節點的數據分區,分布於所有其他作為副本的節點。所以,如果節點#1不可訪問,節點#1的副本將被延伸至其他3個節點。
同步復制保證即時一致性,沒有數據丟失。在提交數據並返回結果給客戶端之前,寫事務被傳播到所有副本。個別案例中,在集群重新配置期間,當Aerospike智能終端發送請求到那些短暫過時的錯誤節點時,Aerospike智能集群會透明的代理請求至正確的節點。最後,當集群正在從分區中恢復,它解決所有發生在不同副本之間的沖突。解析可以配置為自動的,在這種情況下擁有最新的時間戳的數據被視為標准。或者為了在更高層次解析,所有數據副本可以被返回應用程序。
namespace是Aerospike數據庫以相同方式存儲的數據的集合。每個namespace分為4096個分區,分區被均等的分到集群中的節點。意味著如果集群中有n個節點,每節點約存儲1/n的數據
用非常隨機數哈希方法保證分區均勻分布。我們已經在這個領域的許多案例中測試過我們的方法,數據分布誤差在1-2%。
因為數據均勻且隨機的分布於節點,不會出現熱點和瓶頸。也不會出現明顯的某個節點比其他節點處理請求多的情況。
例如,在美國很多的姓以R開頭。如果數據按照字母排序存儲,存儲以R開頭的服務器其通訊量會遠遠大於存儲以X,Y或Z開頭的服務器。數據隨機分配保證服務器負載均衡。
下一步,無須人工分片。集群節點間均等的劃分分區。客戶端發現集群變化並發送請求到正確的節點。定節點被添加或移除,集群自動再平衡。集群中所有節點是均等的-沒有單獨的master節點失敗而導致整個數據庫宕掉。
當數據庫create一個條記錄,記錄key的哈希值被用來分配記錄到某一分區,哈希算法是確定的-哈希算法總是將記錄映射到同樣分區。在記錄的整個生命周期它駐留在同一節點上。分區可能從一個節點移動到其他節點。但是分區不會分裂或者重新分配記錄到其他分區
集群中每個節點有一個配置文件。每個節點上的namespace配置參數必須一致。考慮4節點集群的情況。Aerospike數據庫中,無復制數據需要設置復制因子為1(replication factor = 1),意思是數據庫中只存在一個副本。
因為所有4096個分區在一個4節點集群中,每個節點有1/4的數據-隨機分配的1024個分區。集群看起來如下圖,每個節點管理一個分區集合(簡單起見,只展示兩個節點的分區):
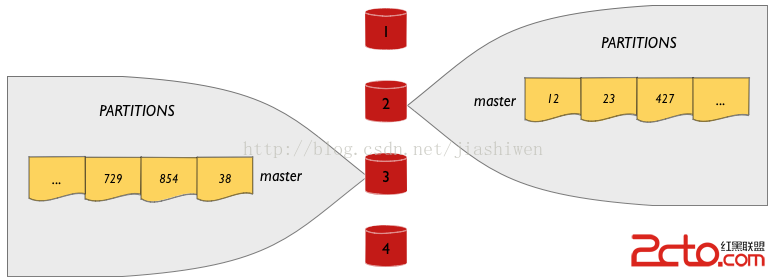
每個節點是1/4數據分區的主數據節點-如果節點是數據的主讀寫源,那麼它就是主數據節點。
客戶端對數據有位置感知能力-客戶端知道每個分區的位置-索引數據可以單跳從節點返回。每個讀寫請求發送至主數據節點處理。當智能節點讀某條記錄時,它發送請求到記錄的主數據節點。
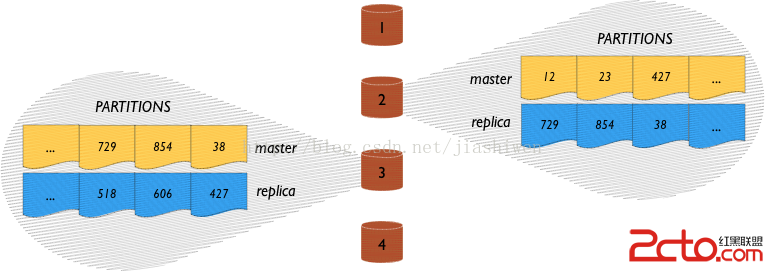
現在考慮一下帶數據復制的情況。大多數情況是維護兩個數據副本,主數據和副本。Aerospike數據庫中,需要指定復制因子為2(replication factor = 2)。
在這個例子中,每個節點擁有1/4的主數據(1024個分區)和1/4的數據副本(1024個分區)。看起來像這樣(簡單起見,顯示兩個節點的細節)
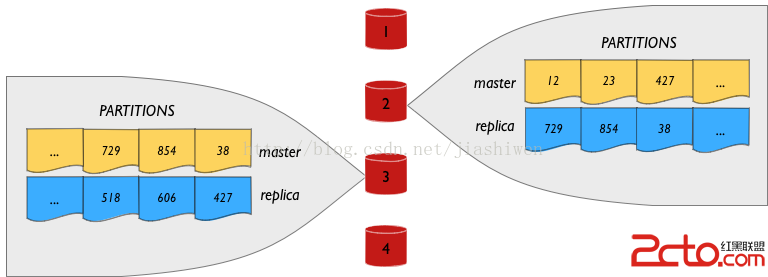
注意,每個節點的主數據作為副本被分布到所有的其他節點。例如,節點#1的主數據分區副本橫跨其他節點分布。當節點#1不可用,節點#1的數據副本延伸至跨其他數據節點。
與先前提到的無副本的例子一樣,客戶端發送請求至主數據。
與無復制的情況一樣,讀請求通過智能客戶端發送至正確的節點,寫請求也被發送至正確的節點。當節點收到寫請求,它保存數據並轉發寫請求到副本節點。一旦副本節點確認數據寫成功並且主數據節點本身也完成寫動作,然後確認被發送至客戶端,寫操作成功。
復制因子不能超過集群中節點的數量。越多副本越可靠,但是對於穿越所有副本的寫請求的需求也越高。實踐中,多數數據庫復制因子為2。無人工分片。
Aerospike數據再平衡算法保證請求量在所有節點間均勻分布,在再平衡期間節點失敗發生時,算法依舊健壯。系統被設計為持續可用,所有數據再平衡不影響集群行為。事務算法與數據分布系統集成,只有一個一致投票來協調集群變化。當客戶端發現新的集群配置時,利用集群內部重定向算法,只有一個小的間隔。這樣,在一個可伸縮的無共享機制優化事務簡單環境,同時保ACID特征。
Aerospike允許配置選項指定有多少可用的操作開銷應該用於管理任務,例如與運行客戶端事務相比有多少用於節點間再平衡。在首選事務放緩的情況下,集群愈合更快。在交易量和速度必須維持的情況下,集群再平衡會很慢。
在某些集群因子不能滿足的情況下。集群可以配置為減少配置因子以保持所有數據,或者清除哪些標記為可丟棄的就數據。如果集群不成接受更多數據,集群將在read-only模式下操作,直到新的擴容可用-節點會自動變為可以接受應用程序的寫操作。
不需要操作員干預,甚至在要求的時間內,集群將自愈。在客戶部署中,提取8節點集群中的一個會讓整個回路被打斷。這就需要無人工干預。即使數據中心在高峰時宕機,事務依舊保持精確的ACID。幾小時內,當錯誤被修復,操作者不需要執行特殊步驟來維護集群。
我們的擴容計劃和系統監控,為你提供處理不可預見的錯誤的能力,而且無服務丟失。你可以配置硬件容量、設置復制/同步策略,這樣數據庫恢復時可以對用戶無影響。
討論網絡硬件如何處理高峰流量負載的細節超出了本文檔的范圍。Aerospike數據庫提供了用來評估瓶頸的監控工具。如果網絡是瓶頸,數據庫不會滿負荷運轉,請求會變慢。
對於容量規劃我們有很多建議,管理存儲並監控集群以確保存儲不溢出。但是在存儲溢出的情況下,Aerospike觸發停止寫限制-在這種情況下不會有新的記錄 被接受。但是數據修改和讀取被正常處理。
換句話說,即使超過容量,數據庫不會停止處理查詢操作,它持續保持盡量多的用戶請求處理量。