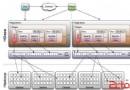
在報表項目中有時會有動態層次報表,而且還需要層次鑽取的場景,開發難度較大。這裡記錄了使潤乾集算報表開發《各級部門KPI報表》的過程。
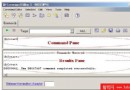
《各級部門KPI報表》初始狀態如下圖:
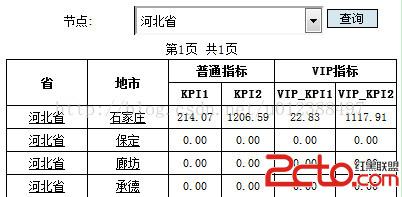
當前節點是根節點“河北省”,要求報表顯示當前節點的下一級節點“地市”匯總的KPI數值。Kpi又分為普通指標和VIP指標兩類,共四項。如果點擊“石家莊”來鑽取的時候,要求能夠將石家莊下一級的KPI匯總指標顯示出來,如下圖:
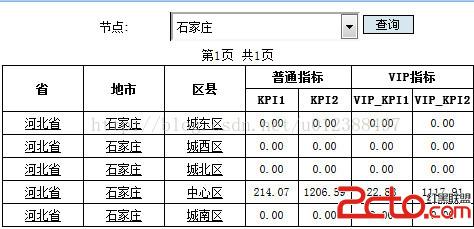
點擊“中心區”鑽取,要求能夠將下一級的KPI匯總指標顯示出來,以此類推,直到顯示到最後一級。如下圖:

前四級固定是“省、地市、區縣、營業部”,後邊則是動態的“架構4、架構5、架構6. . . 架構13”(根節點“省”對應“架構0”)。
這個報表對應的oracle數據庫表有兩個,tree(樹形結構維表)和kpi(指標事實表),如下圖:
Tree表

Kpi表
Tree表的葉子節點,通過id字段與kpi表關聯。這個報表的難點在於1、動態的多層數據、標題;2、樹形結構數據與事實表關聯。
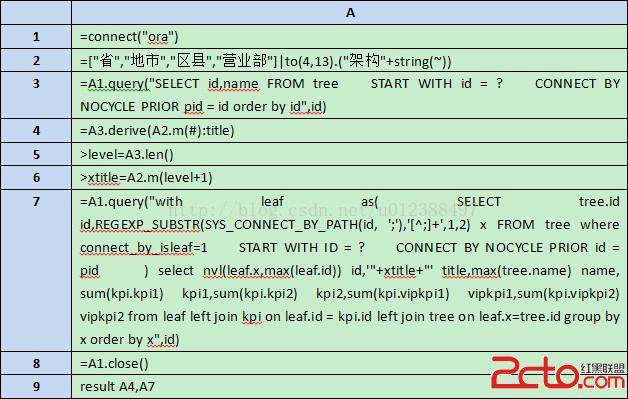
采用潤乾集算報表實現的第一步:編寫集算腳本tree.dfx,完成源數據計算。集算腳本如下:
A1:連接預先配置好的oracle數據庫。
A2:新建一個序列,內容是“省、地市、區縣、營業部、架構4、架構5、架構6. . . 架構13”。
A3:使用oracle數據庫提供的connectby語句編寫sql,從數據庫中取出指定id(節點編號)的所有父節點id、name。id是預先定義的網格參數,如果傳進來的值是104020,那麼A3的計算結果是:
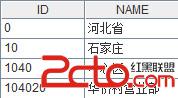
A4:為A3增加一個字段title,按照順序,對應A2中的層級。結果是:
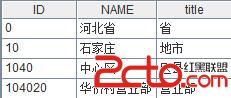
A5:計算變量level,是A3序表的長度,也就是輸入節點“104020”的層級號“4”(“省”為第一級)。
A6:計算輸入節點“104020”的下一級對應的層級名稱“架構4”,賦值給變量xtitle。
A7:編寫sql,從tree表中取出輸入節點“104020”的所有葉子節點,並拆分sys_connect_by_path字符串,得到這些葉子節點對應的輸入節點“104020”的下一級節點。形成臨時表leaf與kpi表關聯分組匯總。為了能夠得到輸入節點“104020”的下一級節點的name,leaf還需要與tree關聯一次。需要注意的是,如果輸入節點號本身就是葉子節點,結果中的name將為空。完整的sql如下:
with leaf as(
SELECT tree.id id,REGEXP_SUBSTR(SYS_CONNECT_BY_PATH(id,';'),'[^;]+',1,2) x FROM tree
whereconnect_by_isleaf=1
START WITH ID =?
CONNECT BY NOCYCLE PRIOR id = pid
)
select nvl(leaf.x,max(leaf.id))id,'"+xtitle+"' title,max(tree.name) name, sum(kpi.kpi1)kpi1,sum(kpi.kpi2) kpi2,sum(kpi.vipkpi1) vipkpi1,sum(kpi.vipkpi2) vipkpi2
from leaf left join kpi on leaf.id = kpi.idleft join tree on leaf.x=tree.id
group by leaf.x order by leaf.x計算的結果是:

A8:關閉數據庫連接。
A9:向報表返回A4、A7兩個結果集。
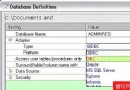
第二步:在報表設計器中定義報表參數和集算數據集,調用tree.dfx。如下圖:
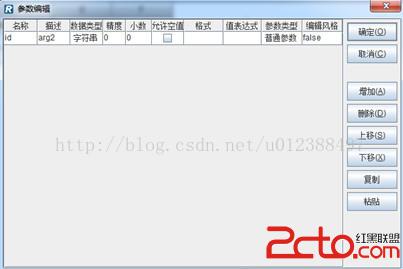
定義報表參數“id”
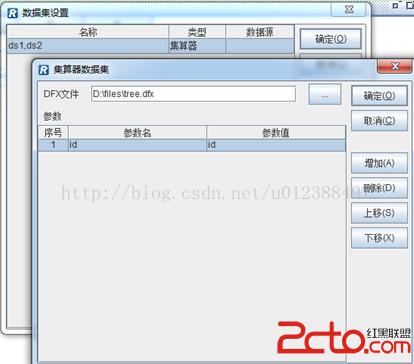
定義集算數據集(其中的參數名“id”是集算腳本的輸出參數名,參數值“id”是報表參數。
第三步,設計報表如下圖:

A列是報表的左半部分,是輸入節點(例如:“104020”)的所有父節點和它本身,橫向擴展,A1的值是id,顯示的是title。A3顯示的是name。
B列是報表的中間部分,是輸入節點(例如:“104020”)的下一級子節點,縱向擴展。在B3格中設置隱藏列的條件是value()==null,如果輸入節點本省就是葉子節點,那麼name==null,B列就會隱藏不顯示了。
C列到F列是報表的右半部分,顯示的是ds2.name對應的kpi統計值。
為了實現報表的格式需要,A3單元格需要將左主格設置為B3。
為了實現鑽取功能,需要:
1、 將A3單元格的超鏈接屬性定義為表達式:"/reportJsp/showReport.jsp?rpx=r4.rpx&id="+ds1.ID。超鏈接指向本報表自身,報表參數是當前列對應的ds1.ID。
2、 將B3單元格的超鏈接屬性定義為表達式:"/reportJsp/showReport.jsp?rpx=r4.rpx&id="+ds2.ID。超鏈接指向本報表自身,報表參數是當前行對應的ds2.ID。
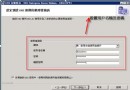
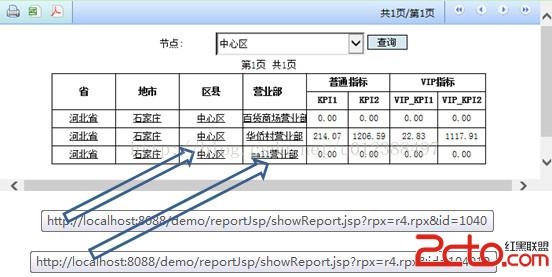
第四步:發布報表並運行。實際的超鏈值如下圖:
 數據庫的樹形遞歸查詢還是比較豐富的,用其他數據庫(比如MySQL,PostgreSQL及Greenplum等)可能就很難實現A7中的SQL。那麼有什麼其他方案,可以讓這些數據庫也能實現上述復雜的樹形結構計算呢?
數據庫的樹形遞歸查詢還是比較豐富的,用其他數據庫(比如MySQL,PostgreSQL及Greenplum等)可能就很難實現A7中的SQL。那麼有什麼其他方案,可以讓這些數據庫也能實現上述復雜的樹形結構計算呢?