數據庫技術產生於六十年代末,是數據管理的最新技術,是計算機科學的重要分支。
數據庫技術是信息系統的核心和基礎,它的出現極大地促進了計算機應用向各行各業的滲透。
數據庫的建設規模、數據庫信息量的大小和使用頻度已成為衡量一個國家信息化程度的重要標志。
數據(Data)是數據庫中存儲的基本對象
數據的定義
描述事物的符號記錄
數據的種類
文本、圖形、圖像、音頻、視頻、學生的檔案記錄、貨物的運輸情況等
數據的特點
數據與其語義是不可分的
數據的含義稱為數據的語義,數據與其語義是不可分的。
例如 93是一個數據
語義1:學生某門課的成績
語義2:某人的體重
語義3:計算機系2003級學生人數
學生檔案中的學生記錄
(李明,男,197205,江蘇南京市,計算機系,1990)
語義:學生姓名、性別、出生年月、籍貫、所在院系、
入學時間
解釋:李明是個大學生,1972年5月出生,江蘇南京市人,1990年考入計算機系
數據庫的定義
數據庫(Database,簡稱DB)是長期儲存在計算機內、有組織的、可共享的大量數據的集合。
數據庫的基本特征
數據按一定的數據模型組織、描述和儲存
可為各種用戶共享
冗余度較小
數據獨立性較高
易擴展
什麼是DBMS, Database Management System
位於用戶與操作系統之間的一層數據管理軟件。
是基礎軟件,是一個大型復雜的軟件系統
商業產品:Oracle, SQL Server, DB2, Sybase, Informix
開源產品: MySQL,Berkeley DB
DBMS的用途
科學地組織和存儲數據、高效地獲取和維護數據。
數據定義功能
提供數據定義語言(DDL)
定義數據庫中的數據對象
數據組織、存儲和管理
分類組織、存儲和管理各種數據
確定組織數據的文件結構和存取方式
實現數據之間的聯系
提供多種存取方法提高存取效率
數據操縱功能
提供數據操縱語言(DML)
實現對數據庫的基本操作 (查詢、插入、刪除和修改)
數據庫的事務管理和運行管理
數據庫在建立、運行和維護時由DBMS統一管理和控制
保證數據的安全性、完整性、多用戶對數據的並發使用
發生故障後的事務恢復
什麼是數據管理
對數據進行分類、組織、編碼、存儲、檢索和維護
數據處理的中心問題
數據管理技術的發展過程
人工管理階段(20世紀40年代中–50年代中)
文件系統階段(20世紀50年代末–60年代中)
數據庫系統階段(20世紀60年代末–現在)
數據結構化
數據的共享性高,冗余度低,易擴充
數據獨立性高
數據由DBMS統一管理和控制
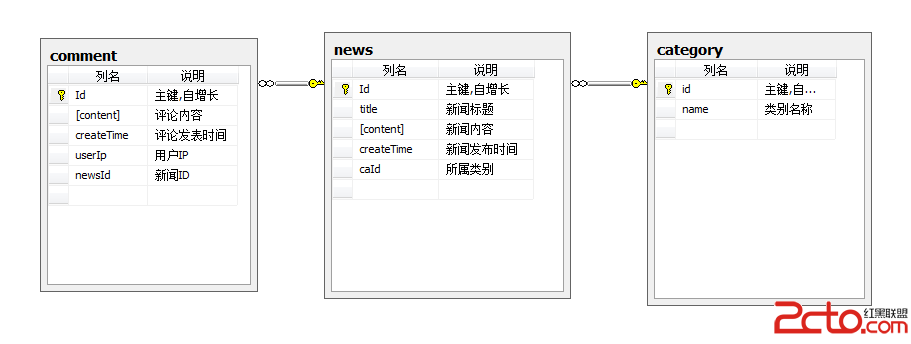
整體數據的結構化是數據庫的主要特征之一
整體結構化
不再僅僅針對某一個應用,而是面向全組織
不僅數據內部結構化,整體是結構化的,數據之間具有聯系
數據庫中實現的是數據的真正結構化
數據的結構用數據模型描述,無需程序定義和解釋
數據可以變長
數據的最小存取單位是數據項
數據庫系統從整體角度看待和描述數據,數據面向整個系統,可以被多個用戶、多個應用共享使用。
數據共享的好處
減少數據冗余,節約存儲空間
避免數據之間的不相容性與不一致性
使系統易於擴充
物理獨立性
指用戶的應用程序與存儲在磁盤上的數據庫中數據是相互獨立的。當數據的物理存儲改變了,應用程序不用改變。
邏輯獨立性
指用戶的應用程序與數據庫的邏輯結構(邏輯模式)是相互獨立的。數據的邏輯結構改變了,用戶程序可以保持不變。
數據獨立性是由DBMS的二級映像功能來保證的
DBMS提供的數據控制功能
(1)數據的安全性(Security)保護
保護數據,以防止不合法的使用造成的數據的洩密和破壞。
(2)數據的完整性(Integrity)檢查
將數據控制在有效的范圍內,或保證數據之間滿足一定的關系。
(3)並發(Concurrency)控制
對多用戶的並發操作加以控制和協調,防止相互干擾而得到錯誤的結果。
(4)數據庫恢復(Recovery)
將數據庫從錯誤狀態恢復到某一已知的正確狀態。
抽象:是從眾多的事物中抽取出共同的、本質性的特征,而捨棄其非本質的特征。例如蘋果、香蕉、生梨、桃子等,它們共同的特性就是水果。得出水果概念的過程,就是一個抽象的過程。要抽象,就必須進行比較,沒有比較就無法找到在本質上共同的部分。共同特征是指那些能把一類事物與他類事物區分開來的特征,這些具有區分作用的特征又稱本質特征。因此抽取事物的共同特征就是抽取事物的本質特征,捨棄非本質的特征。
數據模型分為兩類(分屬兩個不同的層次)
(1) 概念模型 也稱信息模型,它是按用戶的觀點來對數據和信息建模,用於數據庫設計。
(2) 邏輯模型和物理模型
邏輯模型主要包括網狀模型、層次模型、關系模型、面向對象模型等,按計算機系統的觀點對數據建模,用於DBMS實現。
物理模型是對數據最底層的抽象,描述數據在系統內部的表示方式和存取方法,在磁盤或磁帶上的存儲方式和存取方法。
什麼是數據結構
描述數據庫的組成對象,以及對象之間的聯系
描述的內容
與數據類型、內容、性質有關的對象
與數據之間聯系有關的對象
數據結構是對系統靜態特性的描述
數據操作
對數據庫中各種對象(型)的實例(值)允許執行的
操作及有關的操作規則
數據操作的類型
查詢
更新(包括插入、刪除、修改)
數據模型對操作的定義
操作的確切含義
操作符號
操作規則(如優先級)
實現操作的語言
數據操作是對系統動態特性的描述
數據的完整性約束條件
一組完整性規則的集合。
完整性規則:給定的數據模型中數據及其聯系所具有的制約和依存規則
用以限定符合數據模型的數據庫狀態以及狀態的變化,以保證數據的正確、有效、相容。
數據模型對完整性約束條件的定義
反映和規定本數據模型必須遵守的基本的通用的完整性約束條件。例如在關系模型中,任何關系必須滿足實體完整性和參照完整性兩個條件。
提供定義完整性約束條件的機制,以反映具體應用所涉及的數據必須遵守的特定的語義約束條件。
概念模型的用途
概念模型用於信息世界的建模
是現實世界到機器世界的一個中間層次
是數據庫設計的有力工具
數據庫設計人員和用戶之間進行交流的語言
對概念模型的基本要求
較強的語義表達能力
能夠方便、直接地表達應用中的各種語義知識
簡單、清晰、易於用戶理解
(1) 實體(Entity)
客觀存在並可相互區別的事物稱為實體。
可以是具體的人、事、物或抽象的概念。
(2) 屬性(Attribute)
實體所具有的某一特性稱為屬性。
一個實體可以由若干個屬性來刻畫。
(3) 碼(Key)
唯一標識實體的屬性集稱為碼。
(4) 域(Domain)
屬性的取值范圍稱為該屬性的域。
(5) 實體型(Entity Type)
用實體名及其屬性名集合來抽象和刻畫同類實體稱為實體型。
(6) 實體集(Entity Set)
同一類型實體的集合稱為實體集
(7) 聯系(Relationship)
現實世界中事物內部以及事物之間的聯系在信息世界
中反映為實體內部的聯系和實體之間的聯系。
實體內部的聯系通常是指組成實體的各屬性之間的聯系
實體之間的聯系通常是指不同實體集之間的聯系
非關系模型
層次模型(Hierarchical Model)
網狀模型(Network Model)
關系模型(Relational Model)
面向對象模型(Object Oriented Model)
對象關系模型(Object Relational Model)
層次模型是數據庫系統中最早出現的數據模型
層次數據庫系統的典型代表是IBM公司的IMS(Information Management System)數據庫管理系統
層次模型用樹形結構來表示各類實體以及實體間的聯系
層次模型
滿足下面兩個條件的基本層次聯系的集合為層次模型
1. 有且只有一個結點沒有雙親結點,這個結點稱為根結點
2. 根以外的其它結點有且只有一個雙親結點
層次模型中的幾個術語
根結點,雙親結點,兄弟結點,葉結點
層次模型的特點:
結點的雙親是唯一的
只能直接處理一對多的實體聯系
每個記錄類型可以定義一個排序字段,也稱為碼字段
任何記錄值只有按其路徑查看時,才能顯出它的全部意義
沒有一個子女記錄值能夠脫離雙親記錄值而獨立存在
優點
層次模型的數據結構比較簡單清晰
查詢效率高,性能優於關系模型,不低於網狀模型
層次數據模型提供了良好的完整性支持
缺點
多對多聯系表示不自然
對插入和刪除操作的限制多,應用程序的編寫比較復雜
查詢子女結點必須通過雙親結點
由於結構嚴密,層次命令趨於程序化
網狀數據庫系統采用網狀模型作為數據的組織方式
典型代表是DBTG系統:
亦稱CODASYL系統
70年代由DBTG提出的一個系統方案
奠定了數據庫系統的基本概念、方法和技術
實際系統
Cullinet Software Inc.公司的 IDMS
Univac公司的 DMS1100
Honeywell公司的IDS/2
HP公司的IMAGE
網狀模型
滿足下面兩個條件的基本層次聯系的集合:
1. 允許一個以上的結點無雙親;
2. 一個結點可以有多於一個的雙親。
表示方法(與層次數據模型相同)
實體型:用記錄類型描述
每個結點表示一個記錄類型(實體)
屬性:用字段描述
每個記錄類型可包含若干個字段
聯系:用結點之間的連線表示記錄類型(實體)之
間的一對多的父子聯系
網狀模型與層次模型的區別
網狀模型允許多個結點沒有雙親結點
網狀模型允許結點有多個雙親結點
網狀模型允許兩個結點之間有多種聯系(復合聯系)
網狀模型可以更直接地去描述現實世界
層次模型實際上是網狀模型的一個特例
關系數據庫系統采用關系模型作為數據的組織方式
1970年美國IBM公司San Jose研究室的研究員E.F.Codd首次提出了數據庫系統的關系模型
計算機廠商新推出的數據庫管理系統幾乎都支持關系模型
關系(Relation)
一個關系對應通常說的一張表
元組(Tuple)
表中的一行即為一個元組
屬性(Attribute)
表中的一列即為一個屬性,給每一個屬性起一個名稱即屬性名
主碼(Key)
表中的某個屬性組,它可以唯一確定一個元組。
域(Domain)
屬性的取值范圍。
分量
元組中的一個屬性值。
關系模式
對關系的描述
關系名(屬性1,屬性2,…,屬性n)
學生(學號,姓名,年齡,性別,系,年級)
優點
建立在嚴格的數學概念的基礎上
概念單一
實體和各類聯系都用關系來表示
對數據的檢索結果也是關系
關系模型的存取路徑對用戶透明
具有更高的數據獨立性,更好的安全保密性
簡化了程序員的工作和數據庫開發建立的工作