最近遇到一個問題,在用JDOM組件解析XML文件數據,並將數據存儲到oracle數據庫時,出現了如下錯誤:
Exception in thread "main" java.sql.BatchUpdateException: ORA-12899: value too large for column "SCOTT"."EMP1"."JOB" (actual: 12, maximum: 9) at oracle.jdbc.driver.DatabaseError.throwBatchUpdateException(DatabaseError.java:367) at oracle.jdbc.driver.OraclePreparedStatement.executeBatch(OraclePreparedStatement.java:8738) at com.uestc.util.InsertEmp.main(InsertEmp.java:48)要解析的XML文件如下所示:
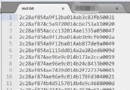
1000 諸葛亮 經理 1998-09-19 3000 500 1001 關雲長 經理 1999-03-12 3500 200 1002 趙子龍 項目經理 2000-07-27 5000 1600 1003 劉玄德 人事 2001-03-14 2000 1300
事先已在oracle數據庫中創建了emp1表,創建腳本語句為:
CREATE TABLE emp1( empno NUMBER(4), ename VARCHAR2(10), job VARCHAR2(9), hiredate DATE, sal NUMBER(7,2), comm NUMBER(7,2) );
問題的原因是對oracle中文字符集編碼的了解不夠。
查看oraccle server端字符集,輸入以下查詢語句:
select userenv('language') from dual;
如果顯示的是以下內容:
SIMPLIFIED CHINESE_CHINA.ZHS16GBK則oracle每個漢字字符占據兩個字節。
如果顯示的是以下內容:
SIMPLIFIED CHINESE_CHINA.AL32UTF8
則oracle每個漢字占據三個字節。經查詢本地的數據庫編碼是AL32UTF8,每個漢字占3個字節,因此job中“項目經理”占據了12個字節,而創建的數據庫表中只分配了9個字節,因此拋出了這個異常。將數據表的創建腳本改為如下所示,問題就解決了:
CREATE TABLE emp1( empno NUMBER(4), ename VARCHAR2(10), job VARCHAR2(12), hiredate DATE, sal NUMBER(7,2), comm NUMBER(7,2) );