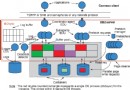
集算報表支持的數據源類型除傳統的關系型數據庫外,還支持:TXT文本、Excel、JSON、HTTP、Hadoop、mongodb等。
對於Hadoop,集算報表既可以直接訪問Hive,也可以讀取HDFS中的數據,完成數據計算和報表開發。Hive的訪問和普通數據庫一樣使用JDBC就可以,這裡不再贅述了。下面通過一個例子來看直接訪問HDFS的過程。
股票交易記錄按月以文本形式存儲在HDFS中,文件名為stock_record_yyyyMM.txt(如stock_record_200901.txt),內容包括股票代碼、交易日期和收盤價。根據指定月份查詢並計算各只股票的收盤均價,以便進行股價趨勢分析。文本內容如下:
code tradingDate price
120089 2009-01-0100:00:00 50.24
120123 2009-01-0100:00:00 10.35
120136 2009-01-0100:00:00 43.37
120141 2009-01-0100:00:00 41.86
120170 2009-01-0100:00:00 194.63
區別於一般報表工具,集算報表可以直接訪問HDFS完成數據的讀取計算,以下為實現過程。
使用集算報表訪問HDFS時需要加載Hadoop核心包及配置包,如:commons-configuration-1.6.jar、commons-lang-2.4.jar、hadoop-core-1.0.4.jar(Hadoop1.0.4)。將以上jar拷貝到[集算報表安裝目錄]\report\lib和[集算器安裝目錄]\esproc(如果需要使用集算器編輯器編輯和調試腳本的話)下。
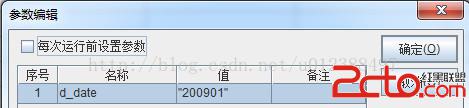
使用集算編輯器編寫腳本(stockFromHdfsTxt.dfx),完成HDFS的文件讀入和數據過濾,為報表返回結果集。由於要接收報表傳遞的參數,首先設置腳本腳本參數。
編輯腳本。
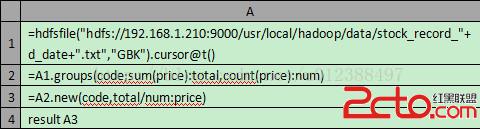
A1:使用hdfsfile函數根據文件路徑和指定參數創建HDFS文件游標;
A2:針對股票代碼匯總收盤價和數量;
A3:計算每只股票的平均收盤價,通過A4為報表返回結果集。
使用集算報表設計器新建報表模板,並設置參數:

設置數據集,使用“集算器”數據集類型,調用編輯好的腳本文件(stockFromHdfsTxt.dfx)。
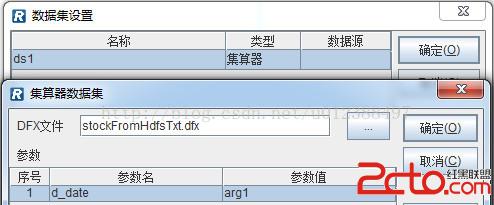
其中,dfx文件路徑既可以是絕對路徑,也可以是相對路徑,相對路徑是相對選項中配置的dfx主目錄的。
編輯報表表達式,直接使用集算腳本返回的結果集,完成報表制作。
值得注意的是,在報表設計器中預覽時,需要將Hadoop相關jar包拷貝到[集算報表安裝目錄]\report\lib下。
除了可以直接訪問HDFS的文本文件外,集算報表也可以讀取HDFS中的壓縮文件。這時仍然使用hdfsfile函數,由擴展名決定解壓方式。比如,要訪問Gzip文件可以這樣寫:
=hdfsfile("hdfs://192.168.1.210:9000/usr/local/hadoop/data/stock_record_"+d_date+".gz","GBK"),只需在將擴展名包含在url中即可。
通過上面的實現可以看到,使用集算器腳本可以很方便地完成HDFS文件的讀取計算,而且外置的集算腳本具有可視化的編輯調試環境,編輯好的腳本還可以復用(被其他報表或程序調用)。不過,如果腳本已經調試好,而且不需要復用的時候,要維護兩個文件(集算腳本和報表模板)的一致性會比較麻煩,這時候直接使用集算報表的腳本數據集就比較簡單了。
在腳本數據集中可以分步編寫腳本完成計算任務,語法與集算器一致,還可以直接使用報表定義好的數據源(本例並未涉及)和參數。使用腳本數據集可以這樣完成:
1. 在數據集設置窗口中點擊“增加”按鈕,彈出數據集類型對話框,選擇“腳本數據集”;
2. 在彈出的腳本數據集編輯窗口中編寫腳本;
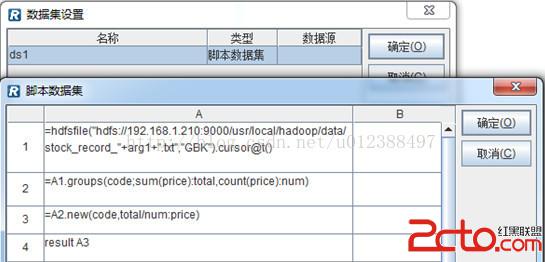
直接使用報表定義的參數arg1。
3.報表參數設置和報表表達式,與使用集算器數據集一致,不再贅述。
報表部署時,同樣需要將Hadoop的相關jar放到應用classpath下,如應用的web-inf\lib下。