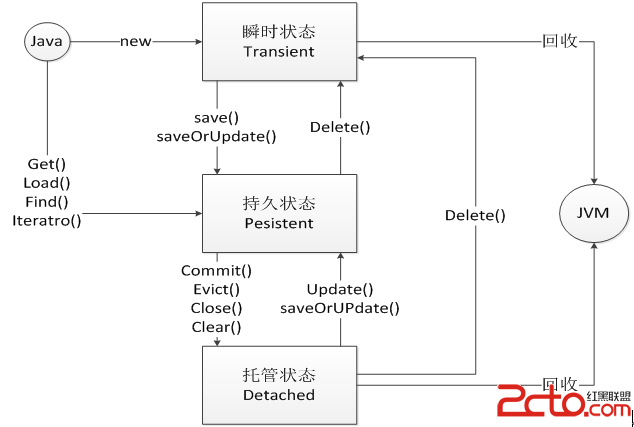
SHA-1算法是第一代“安全散列算法”的縮寫,其本質就是一個Hash算法。SHA系列標准主要用於數字簽名,生成消息摘要,曾被認為是MD5算法的後繼者。如今SHA家族已經出現了5個算法。Redis使用的是SHA-1,它能將一個最大2^64比特的消息,轉換成一串160位的消息摘要,並能保證任何兩組不同的消息產生的消息摘要是不同的。雖然SHA1於早年間也傳出了破解之道,但作為SHA家族的第一代算法,對我們仍然很具有學習價值和指導意義。
Redis的sha1.c文件實現了這一算法,但該文件源碼實際上是出自Valgrind項目的/tests/sha1_test.c文件(可以看出開源的強大之處:取之於民,用之於民)。它包含四個函數:
SHA1Init
typedef struct {
u_int32_t state[5];
u_int32_t count[2];
unsigned char buffer[64];
} SHA1_CTX;
它有三個成員,其含義如下:
void SHA1Final(unsigned char digest[20], SHA1_CTX* context);首先聲明了三個變量:
unsigned i;
unsigned char finalcount[8];
unsigned char c;
後面是個條件測試宏,因為是 #if 0,所以我們只關注它 #else 的部分:
for (i = 0; i < 8; i++) {
finalcount[i] = (unsigned char)((context->count[(i >= 4 ? 0 : 1)]
>> ((3-(i & 3)) * 8) ) & 255); /* Endian independent */
}
首先我們注意到了有一句注釋 Endian independent,直譯是端獨立,即該語句的結果與機器是大端還是小端無關。相信很多人在了解了大小端以後,在這裡都會陷入迷惘。相反如果你不了解大小端的話,這條語句理解起來反而輕松。我們需要理解的是比如:unsigned int a = 0x12345678; unsigned int b = (a>>24)&255。無論機器是大端還是小端,b的值都是0x12(0x00000012)。大小端對於移位操作的結果並無影響,a>>24 的語義一定是a 除以 2的24次方。 finalcount是char數組,context->count是整型數組。這段語句的意思就是將整型數據分拆成單個字節存儲。finalcount存儲的結果可以理解為是一個大端序的的超大整型。舉例比如:context->count[0]存儲的是0x11223344,context->count[1]存儲的是0x55667788。那麼最後finalcount[0]~finalcount[7]存儲的依次是:0x88、0x77、0x66、0x55、0x44、0x33、0x22、0x11
c = 0200;
SHA1Update(context, &c, 1);
c的二進制表示為10 000 000。因為前面我講解了,填充的時候是以字節為單位的,最少1個字節,最多64個字節。並且第一位要填充1,後面都填充0。所以拿到一個消息我們首先要給他填充一個字節的10 000 000.SHA1Update() 函數就是完成的數據填充(附加)操作,該函數具體細節容後再禀。這裡我們先關注整體結構。
while ((context->count[0] & 504) != 448) {
c = 0000;
SHA1Update(context, &c, 1);
}
這段代碼很容易看出它的功能就是:循環測試數據模512是否與448同余。不滿足條件就填充全一個字節0。細心的你也許會發現這裡的條件是不是寫錯了:
while ((context->count[0] & 504) != 448) //你覺得應該是 while ((context->count[0] & 511) != 448)理論上來說,你的想法確實不錯。不過源碼也沒問題,我們可以用bc來看一下這兩個數的二進制表達:
111111000 //504 111111111 //511可以看出它們的不同之處就是最後三位。504後三位全0,511後三位全1。context->count中存儲的是消息的長度,它的單位是:位。前面我們提到了我們的數據是以字節來存儲的,所以context->count[ ]中的數據肯定是8個倍數,所以後三位肯定是000。所以不管是000&000,還是000&111其結果都是0。 --------------------------------------------------------------------------------------------------------------------------------------------------------------
SHA1Update(context, finalcount, 8); /* Should cause a SHA1Transform() */很明顯,這一句完成的就是附加長度了。根據注釋可以看出,這將觸發SHA1Transform()函數的調用,該函數的功能就是進行運算,得出160位的消息摘要(message digest)並儲存在context-state[ ]中,它是整個SHA-1算法的核心。其實現細節請看下文的:計算消息摘要一節。
for (i = 0; i < 20; i++) {
digest[i] = (unsigned char)
((context->state[i>>2] >> ((3-(i & 3)) * 8) ) & 255);
}
最後的這步轉換將消息摘要轉換成單字節序列。用代碼來解釋就是:將context-state[5]中儲存的20個字節(5×4字節)的消息摘要取出,將其存儲在20個單字節的數組digest中。並且按大端序存儲(與之前分析context->count[ ]到finalcount[ ]轉換的思路相同)。SHA-1算法最後要得出的就是這160位(20字節)的數據。void SHA1Update(SHA1_CTX* context, const unsigned char* data, u_int32_t len);data就是我們要附加的數據。len是data的長度(單位:字節)
j = context->count[0];
if ((context->count[0] += len << 3) < j)
context->count[1]++;
context->count[1] += (len>>29);
context->count[ ]存儲的是消息的長度,超出context->count[0]的存儲范圍的部分存儲在context->count[1]中。len<<3就是len*8的意思,因為len的單位是字節,而context->count[ ]存儲的長度的單位是位,所以要乘以8。 if ((context->count[0] += len << 3) < j) 的意思就是說如果加上len*8個位,context->count[0]溢出了,那麼就要:context->count[1]++;進位。 len<<3的單位是位,len>>29(len<<3 >>32)表示的就是len中要存儲在context->count[1]中的部分。
j = (j >> 3) & 63;
j>>3獲得的就是字節數,j = (j >> 3) & 63得到的就是低6位的值,也就是代表64個字節(512位)長度的消息。,因為我們每次進行計算都是處理512位的消息數據。
if ((j + len) > 63) {
memcpy(&context->buffer[j], data, (i = 64-j));
SHA1Transform(context->state, context->buffer);
for ( ; i + 63 < len; i += 64) {
SHA1Transform(context->state, &data[i]);
}
j = 0;
}
else i = 0;
memcpy(&context->buffer[j], &data[i], len - i);
這段代碼大致的含義就是:如果j+len的長度大於63個字節,就分開處理,每64個字節處理一次,然後再處理後面的64個字節,重復這個過程;否則就直接將數據附加到buffer末尾。逐句分析一下:
memcpy(&context->buffer[j], data, (i = 64-j));
SHA1Transform(context->state, context->buffer);
i=64-j,然後從data中復制i個字節的數據附加到context->buffer[j]末尾,也就是說給buffer湊成了64個字節,然後執行SHA1Transform()來開始一次消息摘要的計算。
for ( ; i + 63 < len; i += 64) {
SHA1Transform(context->state, &data[i]);
}
j = 0;
然後開始循環,每64個字節處理一次。這裡可能有朋友會好奇每次i遞增的步長都是64,那麼為什麼比較的時候是 i + 63 < len;而不是 i + 64 < len;呢?其原因很簡單——因為下標是從0計數的。這些細節大家簡單琢磨一下就OK啦。 最後j=0,把buffer[ ]的偏移重置到開頭。因為已經計算完消息摘要的數據就沒有用了。
else i = 0;
memcpy(&context->buffer[j], &data[i], len - i);
如果前面的if不成立,那麼也就是說原始數據context->buffer加上新的數據data的長度還不足以湊成64個字節,所以直接附加上data就行了。相當於:memcpy(&context->buffer[j], &data[i], 0); 如果前面的if成立,那麼j是等於0的,而 i 所指向的偏移位置是 (└ len/64┘×64,len)之間。 └ ┘表示向下取整。
H0 = 0x67452301
H1 = 0xEFCDAB89
H2 = 0x98BADCFE
H3 = 0x10325476
H4 = 0xC3D2E1F0
在開始計算消息摘要之前,要先初始化這5個字的緩沖區,也就是按照上面的數值賦值。這步操作體現在sha1.c文件的SHA1Init()函數中。
void SHA1Init(SHA1_CTX* context)
{
/* SHA1 initialization constants */
context->state[0] = 0x67452301;
context->state[1] = 0xEFCDAB89;
context->state[2] = 0x98BADCFE;
context->state[3] = 0x10325476;
context->state[4] = 0xC3D2E1F0;
context->count[0] = context->count[1] = 0;
}
f(t;B,C,D) = (B AND C) OR ((NOT B) AND D) ( 0 <= t <= 19)
f(t;B,C,D) = B XOR C XOR D (20 <= t <= 39)
f(t;B,C,D) = (B AND C) OR (B AND D) OR (C AND D) (40 <= t <= 59)
f(t;B,C,D) = B XOR C XOR D (60 <= t <= 79).
每一輪還會用到一個附加常數K(t):
K(t) = 0x5A827999 ( 0 <= t <= 19)
K(t) = 0x6ED9EBA1 (20 <= t <= 39)
K(t) = 0x8F1BBCDC (40 <= t <= 59)
K(t) = 0xCA62C1D6 (60 <= t <= 79)
共有5步:
1. M(t) = W(t) (0<= t<= 15)
2. W(t) = S^1(W(t-3) XOR W(t-8) XOR W(t-14) XOR W(t-16)) (16<= t <= 79,S^1()表示循環左移1位)
3. A = H0, B = H1, C = H2, D = H3, E = H4.
4. 對於(0<= t <= 79)開始執行80輪變換
TEMP = S^5(A) + f(t;B,C,D) + E + W(t) + K(t);
E = D; D = C; C = S^30(B); B = A; A = TEMP;
5. H0 = H0 + A, H1 = H1 + B, H2 = H2 + C, H3 = H3 + D, H4 = H4 + E.
上面的數學表達式改編自RFC文檔,在經過80輪運算之後的H0~H4就是SHA-1算法要生成的160比特(位)的消息摘要。裡面使用了ABCDE這5個符號,Redis源碼中使用的是v表示符號A;w、x、y代表上文中的B、C、D,z表示上文中的TEMP。在5步之中的前面兩步中,進行了消息塊M(i)到W(i)的轉換,這樣做的目的是將16個字(32位)的消息塊(M)轉換成80個字的字塊(W)。
#define rol(value, bits) (((value) << (bits)) | ((value) >> (32 - (bits))))
typedef union {
unsigned char c[64];
u_int32_t l[16];
} CHAR64LONG16;
#ifdef SHA1HANDSOFF
CHAR64LONG16 block[1]; /* use array to appear as a pointer */
W(i) = block-l[i&15] // 16<= i <= 79
#if BYTE_ORDER == LITTLE_ENDIAN #define blk0(i) (block->l[i] = (rol(block->l[i],24)&0xFF00FF00) \ |(rol(block->l[i],8)&0x00FF00FF)) #elif BYTE_ORDER == BIG_ENDIAN #define blk0(i) block->l[i]blk0的功能實際是就是進行字節序的轉換。如果是小端序就將block->l[i] 轉換為大端序(上面代碼中的第2行),如果是大端序就不操作,直接等價於block->l[i]。實際上在調用blk0(i)的時候,它參數i的取值范圍是0~15。
#define blk(i) (block->l[i&15] = rol(block->l[(i+13)&15]^block->l[(i+8)&15] \
^block->l[(i+2)&15]^block->l[i&15],1))
實際上在調用blk(i)的時候,它的參數i的取值范圍是16~79。 實際上它實現的功能我們在下面會用到,它實際計算的表達式是:
用符號W(i)來表示block-l[i] W(i) = S^1( W(i-3) XOR W(i-8) XOR W(i-14) XOR W(i-16) ) //S^1()表示循環左移 因為觀察上面表達式可知,我們只需要16個字的存儲空間來保存就可以了。所以在實現上等價與: W(i%16) = S^1( W((i-3)%16) XOR W((i-8)%16) XOR W((i-14)%16) XOR W((i-16)%16) )下面來簡單證明一下:
因為a&15等價與a%16 則源碼blk(i)完成的操作等價於: W(i%16) = S^1( W((i+13)%16) XOR W((i+8)%16) XOR W((i+2)%16) XOR W((i%16)) ) 設m+n=16 (i+n)%16 = (i+16-m)%16 = ((i-m)%16 + 16%16)%16 = (i-m)%16 當n=13,8,2,0時,m等於3,8,14,16 所以: W(i%16) = S^1( W((i+13)%16) XOR W((i+8)%16) XOR W((i+2)%16) XOR W((i%16)) ) W(i%16) = S^1( W((i-3)%16) XOR W((i-8)%16) XOR W((i-14)%16) XOR W((i-16)%16) ) 等價
/* (R0+R1), R2, R3, R4 are the different operations used in SHA1 */ #define R0(v,w,x,y,z,i) z+=((w&(x^y))^y)+blk0(i)+0x5A827999+rol(v,5);w=rol(w,30); #define R1(v,w,x,y,z,i) z+=((w&(x^y))^y)+blk(i)+0x5A827999+rol(v,5);w=rol(w,30); #define R2(v,w,x,y,z,i) z+=(w^x^y)+blk(i)+0x6ED9EBA1+rol(v,5);w=rol(w,30); #define R3(v,w,x,y,z,i) z+=(((w|x)&y)|(w&x))+blk(i)+0x8F1BBCDC+rol(v,5);w=rol(w,30); #define R4(v,w,x,y,z,i) z+=(w^x^y)+blk(i)+0xCA62C1D6+rol(v,5);w=rol(w,30);這段代碼中的R2、R3、R4三個宏函數,所完成的操作就是 t(t表示輪數,共計80輪運算) 在范圍 [20,39]、[40,59]、[60,79]的時候的運算。對應RFC文檔中:求解TEMP、給A~E重新賦值。但是我們可以看到當 t 的范圍在[0,20]的時候使用了R0和R1這兩個宏函數來表示,它們的差別之處在於R0裡面計算 z(即TEMP)值的時候,加上的是blk0(i),而R1中加的是blk(i) (和R2、R3、R4一樣,加的是blk(i))。造成這個差別的原因是在前面提到了5步運算的前兩步中:當 t 取值[0,15]的時候W(t)直接等於M(t),而 t>15以後(這裡是t取值[16,19])Wt則需要進行轉換才能得到,即
W(t) = S^1(W(t-3) XOR W(t-8) XOR W(t-14) XOR W(t-16))前面我們已經證明了,blk(i)實現的功能正是這個公式的計算。 大家如果細心的話,可以發現R0和R1中使用的 f 函數是:(w&(x^y))^y 而RFC文檔中給出的是(B&C)|(B&D) 用wxy替換BCD的話就是 (w&x)|(w&y)。那麼(w&(x^y))^y和(w&x)|(w&y)等價嗎?答案是肯定的,邏輯表達式的證明也不是我的強項,不過因為只涉及三個變量所以我們可以用枚舉的方法來比較兩個邏輯表達式的值,於是我手寫了一個小程序來比較它們:
#include談了這麼多,是時候引入sha1.c文件的核心函數了——SHA1Transform()int main(){ for(int w=0;w<2;w++){ for(int x=0;x<2;x++){ for(int y=0;y<2;y++){ printf("-------------\n"); //分割線,使更容易比較閱讀 printf("%d %d %d:%d\n",w,x,y,(w&(x^y))^y); printf("%d %d %d:%d\n",w,x,y,(w&x)|(~w&y)); } } } }
void SHA1Transform(u_int32_t state[5], const unsigned char buffer[64])該函數的代碼行數較多,為節省篇幅,我這裡就不全部列出了。 開始部分聲明了u_int32_t類型的五個變量:a、b、c、d、e。接著定義了結構體類型CHAR64LONG,並聲明了一個該類型的指針變量block(實際是數組實現),前面有介紹。然後:
memcpy(block, buffer, 64);將參數buffer裡面的字節復制到block中。
a = state[0];
b = state[1];
c = state[2];
d = state[3];
e = state[4];
實際上完成的就是RFC文檔中的H0~H4賦值給ABCDE的操作。接下來就是80輪運算的代碼。每20輪為一組,共分四組。
R0(a,b,c,d,e, 0); R0(e,a,b,c,d, 1); R0(d,e,a,b,c, 2); R0(c,d,e,a,b, 3);
R0(b,c,d,e,a, 4); R0(a,b,c,d,e, 5); R0(e,a,b,c,d, 6); R0(d,e,a,b,c, 7);
R0(c,d,e,a,b, 8); R0(b,c,d,e,a, 9); R0(a,b,c,d,e,10); R0(e,a,b,c,d,11);
R0(d,e,a,b,c,12); R0(c,d,e,a,b,13); R0(b,c,d,e,a,14); R0(a,b,c,d,e,15);
R1(e,a,b,c,d,16); R1(d,e,a,b,c,17); R1(c,d,e,a,b,18); R1(b,c,d,e,a,19);
...
第一組比較特殊,使用了R0和R1兩個宏函數,其原因前面已經介紹了。因為第0~15輪運算和16~79輪運算的時候消息塊M(i)和字塊W(i)的轉換是不一樣的。後面的20~39輪,40~59輪,60~79輪就是依次使用的R2,R3,R4來運算了,比較好理解,就不表了。接著:
state[0] += a;
state[1] += b;
state[2] += c;
state[3] += d;
state[4] += e;
/* Wipe variables */
a = b = c = d = e = 0;
完成的就是更新緩沖區H0~H4的內容。然後把a~e清空為0(這一步我感覺意義不到,本身就是棧存儲的5個變量,函數結束後就釋放了啊)。最後state[0]~state[4]中存儲的就是SHA-1算法的生成的消息摘要。